 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Local Learning Match Self-Supervised Backpropagation?
Jan 29, 2026While end-to-end self-supervised learning with backpropagation (global BP-SSL) has become central for training modern AI systems, theories of local self-supervised learning (local-SSL) have struggled to build functional representations in deep neural networks. To establish a link between global and local rules, we first develop a theory for deep linear networks: we identify conditions for local-SSL algorithms (like Forward-forward or CLAPP) to implement exactly the same weight update as a global BP-SSL. Starting from the theoretical insights, we then develop novel variants of local-SSL algorithms to approximate global BP-SSL in deep non-linear convolutional neural networks. Variants that improve the similarity between gradient updates of local-SSL with those of global BP-SSL also show better performance on image datasets (CIFAR-10, STL-10, and Tiny ImageNet). The best local-SSL rule with the CLAPP loss function matches the performance of a comparable global BP-SSL with InfoNCE or CPC-like loss functions, and improves upon state-of-the-art for local SSL on these benchmarks.
Spiking Music: Audio Compression with Event Based Auto-encoders
Feb 02, 2024Neurons in the brain communicate information via punctual events called spikes. The timing of spikes is thought to carry rich information, but it is not clear how to leverage this in digital systems. We demonstrate that event-based encoding is efficient for audio compression. To build this event-based representation we use a deep binary auto-encoder, and under high sparsity pressure, the model enters a regime where the binary event matrix is stored more efficiently with sparse matrix storage algorithms. We test this on the large MAESTRO dataset of piano recordings against vector quantized auto-encoders. Not only does our "Spiking Music compression" algorithm achieve a competitive compression/reconstruction trade-off, but selectivity and synchrony between encoded events and piano key strikes emerge without supervision in the sparse regime.
Are training trajectories of deep single-spike and deep ReLU network equivalent?
Jun 14, 2023Communication by binary and sparse spikes is a key factor for the energy efficiency of biological brains. However, training deep spiking neural networks (SNNs) with backpropagation is harder than with artificial neural networks (ANNs), which is puzzling given that recent theoretical results provide exact mapping algorithms from ReLU to time-to-first-spike (TTFS) SNNs. Building upon these results, we analyze in theory and in simulation the learning dynamics of TTFS-SNNs. Our analysis highlights that even when an SNN can be mapped exactly to a ReLU network, it cannot always be robustly trained by gradient descent. The reason for that is the emergence of a specific instance of the vanishing-or-exploding gradient problem leading to a bias in the gradient descent trajectory in comparison with the equivalent ANN. After identifying this issue we derive a generic solution for the network initialization and SNN parameterization which guarantees that the SNN can be trained as robustly as its ANN counterpart. Our theoretical findings are illustrated in practice on image classification datasets. Our method achieves the same accuracy as deep ConvNets on CIFAR10 and enables fine-tuning on the much larger PLACES365 dataset without loss of accuracy compared to the ANN. We argue that the combined perspective of conversion and fine-tuning with robust gradient descent in SNN will be decisive to optimize SNNs for hardware implementations needing low latency and resilience to noise and quantization.
GateON: an unsupervised method for large scale continual learning
Jun 02, 2023



The objective of continual learning (CL) is to learn tasks sequentially without retraining on earlier tasks. However, when subjected to CL, traditional neural networks exhibit catastrophic forgetting and limited generalization. To overcome these problems, we introduce a novel method called 'Gate and Obstruct Network' (GateON). GateON combines learnable gating of activity and online estimation of parameter relevance to safeguard crucial knowledge from being overwritten. Our method generates partially overlapping pathways between tasks which permits forward and backward transfer during sequential learning. GateON addresses the issue of network saturation after parameter fixation by a re-activation mechanism of fixed neurons, enabling large-scale continual learning. GateON is implemented on a wide range of networks (fully-connected, CNN, Transformers), has low computational complexity, effectively learns up to 100 MNIST learning tasks, and achieves top-tier results for pre-trained BERT in CL-based NLP tasks.
An Exact Mapping From ReLU Networks to Spiking Neural Networks
Dec 23, 2022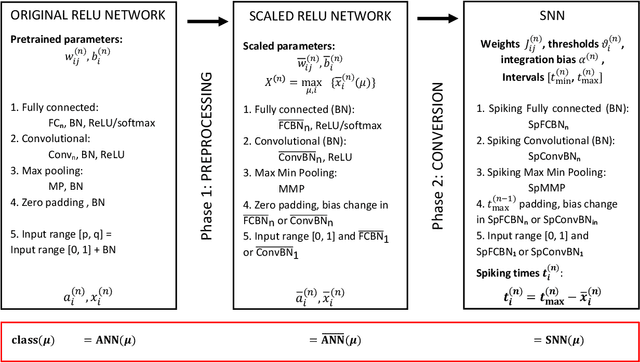
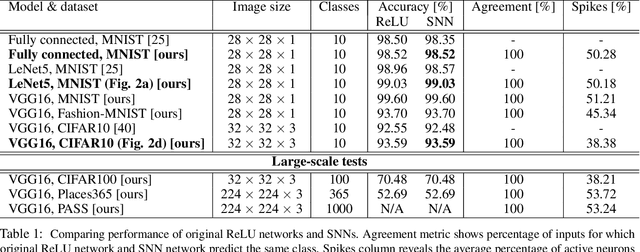
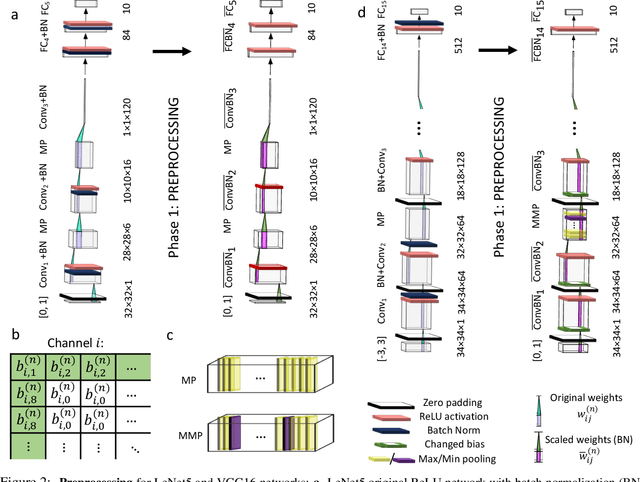
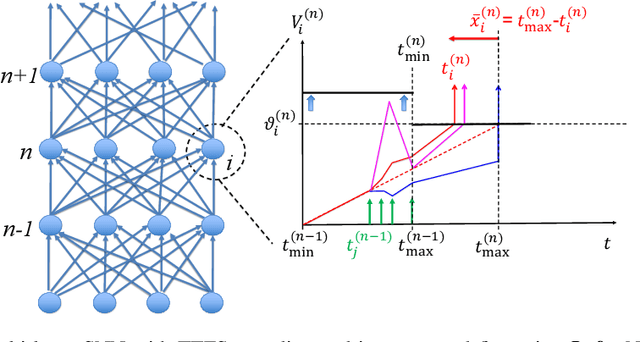
Deep spiking neural networks (SNNs) offer the promise of low-power artificial intelligence. However, training deep SNNs from scratch or converting deep artificial neural networks to SNNs without loss of performance has been a challenge. Here we propose an exact mapping from a network with Rectified Linear Units (ReLUs) to an SNN that fires exactly one spike per neuron. For our constructive proof, we assume that an arbitrary multi-layer ReLU network with or without convolutional layers, batch normalization and max pooling layers was trained to high performance on some training set. Furthermore, we assume that we have access to a representative example of input data used during training and to the exact parameters (weights and biases) of the trained ReLU network. The mapping from deep ReLU networks to SNNs causes zero percent drop in accuracy on CIFAR10, CIFAR100 and the ImageNet-like data sets Places365 and PASS. More generally our work shows that an arbitrary deep ReLU network can be replaced by an energy-efficient single-spike neural network without any loss of performance.
Mesoscopic modeling of hidden spiking neurons
May 26, 2022

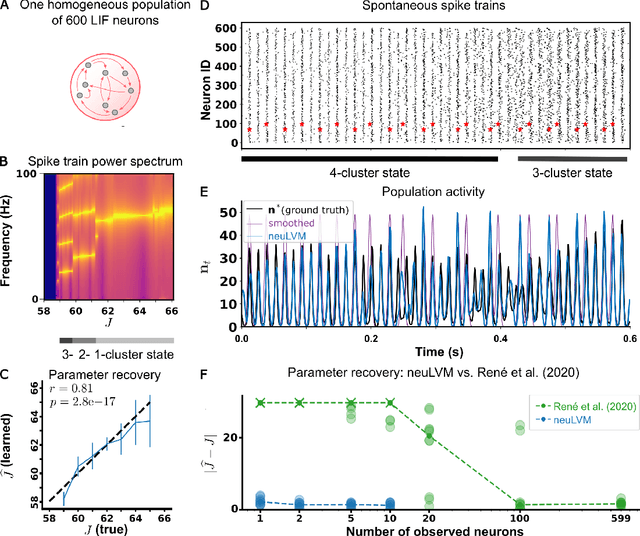

Can we use spiking neural networks (SNN) as generative models of multi-neuronal recordings, while taking into account that most neurons are unobserved? Modeling the unobserved neurons with large pools of hidden spiking neurons leads to severely underconstrained problems that are hard to tackle with maximum likelihood estimation. In this work, we use coarse-graining and mean-field approximations to derive a bottom-up, neuronally-grounded latent variable model (neuLVM), where the activity of the unobserved neurons is reduced to a low-dimensional mesoscopic description. In contrast to previous latent variable models, neuLVM can be explicitly mapped to a recurrent, multi-population SNN, giving it a transparent biological interpretation. We show, on synthetic spike trains, that a few observed neurons are sufficient for neuLVM to perform efficient model inversion of large SNNs, in the sense that it can recover connectivity parameters, infer single-trial latent population activity, reproduce ongoing metastable dynamics, and generalize when subjected to perturbations mimicking photo-stimulation.
Fitting summary statistics of neural data with a differentiable spiking network simulator
Jun 18, 2021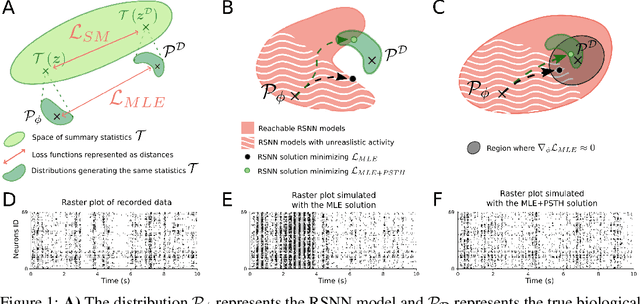
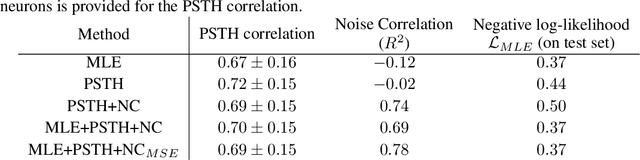
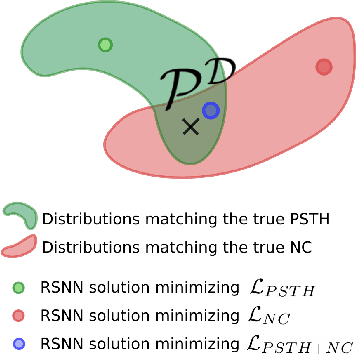

Fitting network models to neural activity is becoming an important tool in neuroscience. A popular approach is to model a brain area with a probabilistic recurrent spiking network whose parameters maximize the likelihood of the recorded activity. Although this is widely used, we show that the resulting model does not produce realistic neural activity and wrongly estimates the connectivity matrix when neurons that are not recorded have a substantial impact on the recorded network. To correct for this, we suggest to augment the log-likelihood with terms that measure the dissimilarity between simulated and recorded activity. This dissimilarity is defined via summary statistics commonly used in neuroscience, and the optimization is efficient because it relies on back-propagation through the stochastically simulated spike trains. We analyze this method theoretically and show empirically that it generates more realistic activity statistics and recovers the connectivity matrix better than other methods.
Towards truly local gradients with CLAPP: Contrastive, Local And Predictive Plasticity
Oct 16, 2020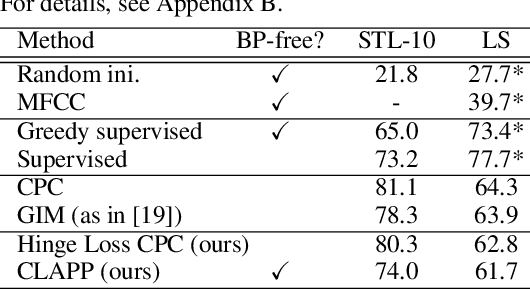
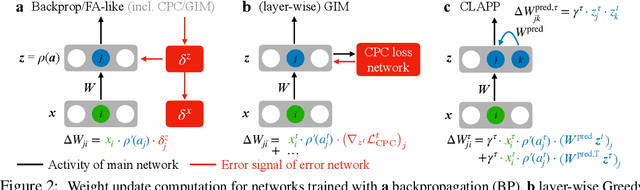

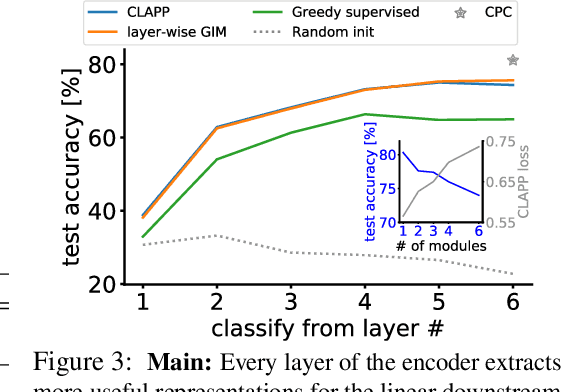
Back-propagation (BP) is costly to implement in hardware and implausible as a learning rule implemented in the brain. However, BP is surprisingly successful in explaining neuronal activity patterns found along the cortical processing stream. We propose a locally implementable, unsupervised learning algorithm, CLAPP, which minimizes a simple, layer-specific loss function, and thus does not need to back-propagate error signals. The weight updates only depend on state variables of the pre- and post-synaptic neurons and a layer-wide third factor. Networks trained with CLAPP build deep hierarchical representations of images and speech.
Biologically inspired alternatives to backpropagation through time for learning in recurrent neural nets
Jan 25, 2019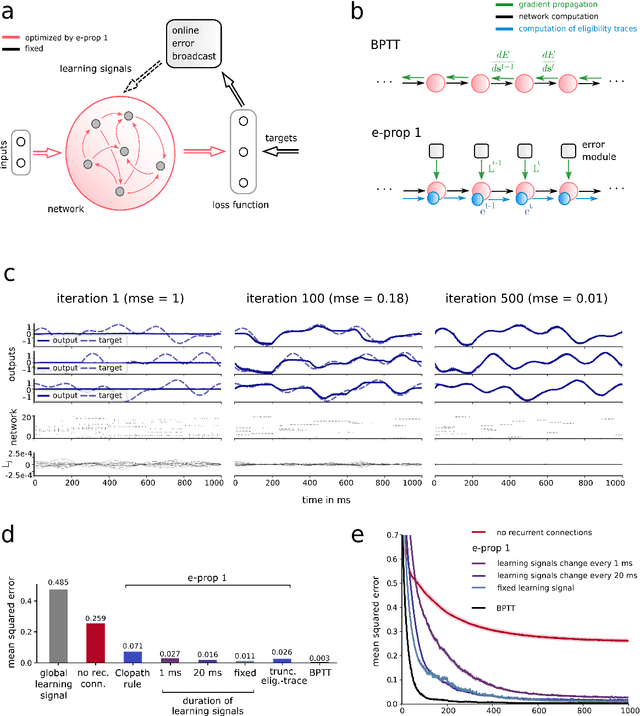
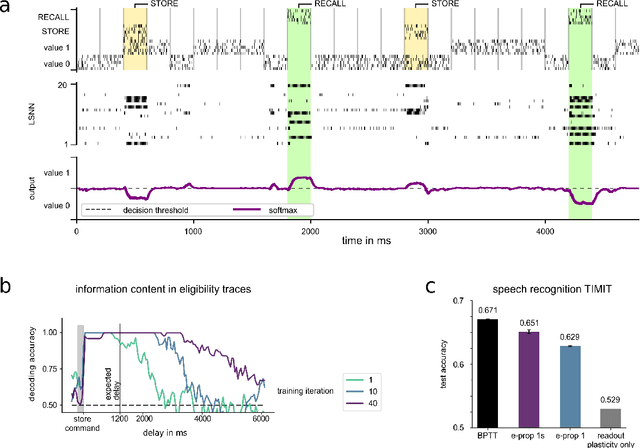
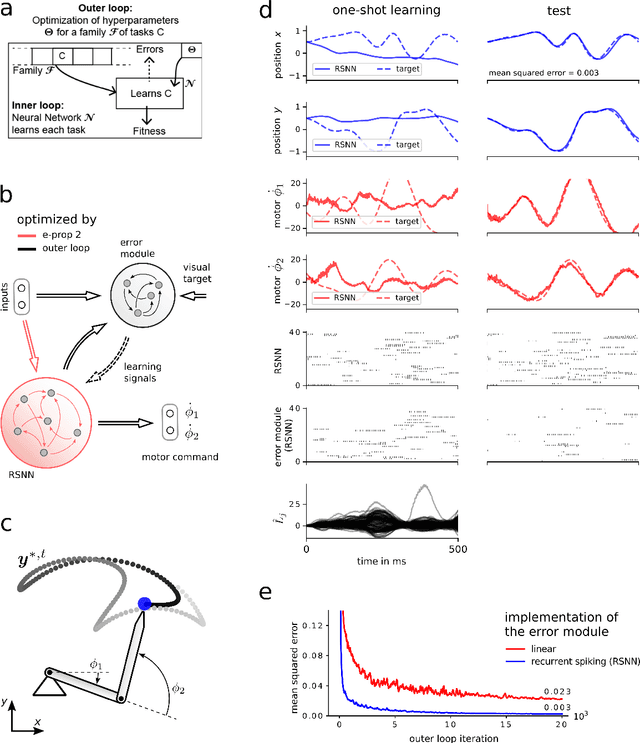
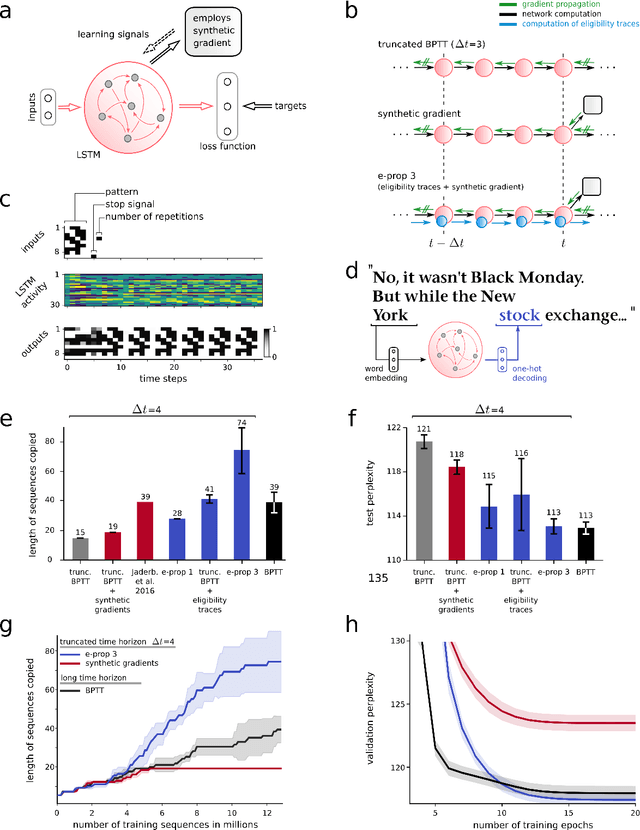
The way how recurrently connected networks of spiking neurons in the brain acquire powerful information processing capabilities through learning has remained a mystery. This lack of understanding is linked to a lack of learning algorithms for recurrent networks of spiking neurons (RSNNs) that are both functionally powerful and can be implemented by known biological mechanisms. Since RSNNs are simultaneously a primary target for implementations of brain-inspired circuits in neuromorphic hardware, this lack of algorithmic insight also hinders technological progress in that area. The gold standard for learning in recurrent neural networks in machine learning is back-propagation through time (BPTT), which implements stochastic gradient descent with regard to a given loss function. But BPTT is unrealistic from a biological perspective, since it requires a transmission of error signals backwards in time and in space, i.e., from post- to presynaptic neurons. We show that an online merging of locally available information during a computation with suitable top-down learning signals in real-time provides highly capable approximations to BPTT. For tasks where information on errors arises only late during a network computation, we enrich locally available information through feedforward eligibility traces of synapses that can easily be computed in an online manner. The resulting new generation of learning algorithms for recurrent neural networks provides a new understanding of network learning in the brain that can be tested experimentally. In addition, these algorithms provide efficient methods for on-chip training of RSNNs in neuromorphic hardware.
Long short-term memory and learning-to-learn in networks of spiking neurons
Nov 02, 2018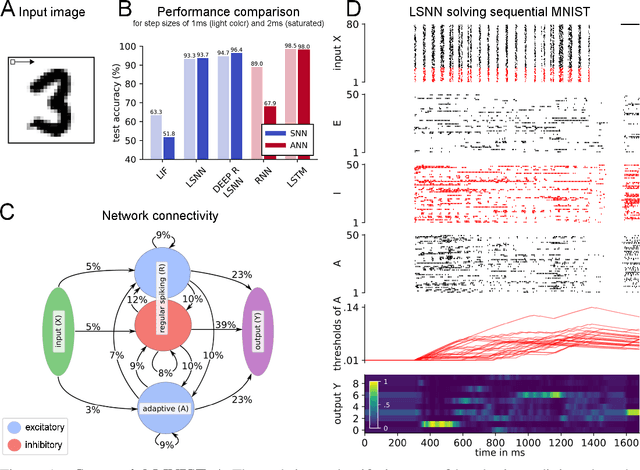
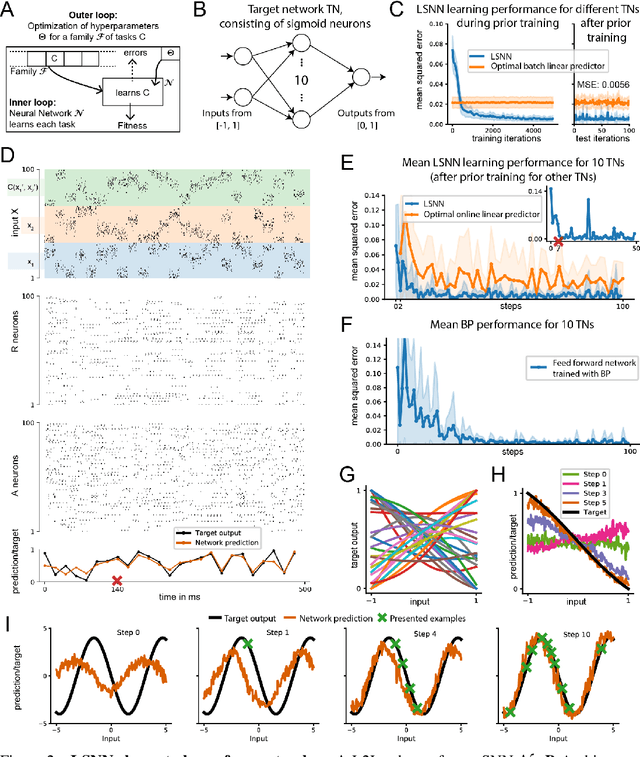
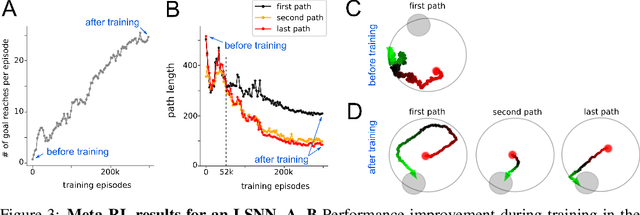
Recurrent networks of spiking neurons (RSNNs) underlie the astounding computing and learning capabilities of the brain. But computing and learning capabilities of RSNN models have remained poor, at least in comparison with ANNs. We address two possible reasons for that. One is that RSNNs in the brain are not randomly connected or designed according to simple rules, and they do not start learning as a tabula rasa network. Rather, RSNNs in the brain were optimized for their tasks through evolution, development, and prior experience. Details of these optimization processes are largely unknown. But their functional contribution can be approximated through powerful optimization methods, such as backpropagation through time (BPTT). A second major mismatch between RSNNs in the brain and models is that the latter only show a small fraction of the dynamics of neurons and synapses in the brain. We include neurons in our RSNN model that reproduce one prominent dynamical process of biological neurons that takes place at the behaviourally relevant time scale of seconds: neuronal adaptation. We denote these networks as LSNNs because of their Long short-term memory. The inclusion of adapting neurons drastically increases the computing and learning capability of RSNNs if they are trained and configured by deep learning (BPTT combined with a rewiring algorithm that optimizes the network architecture). In fact, the computational performance of these RSNNs approaches for the first time that of LSTM networks. In addition RSNNs with adapting neurons can acquire abstract knowledge from prior learning in a Learning-to-Learn (L2L) scheme, and transfer that knowledge in order to learn new but related tasks from very few examples. We demonstrate this for supervised learning and reinforcement learning.