 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWinner-Take-All bottlenecks enforce disentangled symbolic representations in multi-task learning
May 21, 2026Winner-take-all (WTA) networks constitute a central circuit motif in cortical networks of the brain. In addition, WTA-like activations are abundant in modern deep learning models in the form of the softmax activation for example in attention layers of transformers. While their role in the extraction of latent factors has been studied for relatively simple generative models, their role in the context of highly non-linearly entangled latent factors has remained elusive. In this article, we show that a WTA bottleneck within a deep neural network can enforce under certain well-defined conditions the extraction of categorical latent factors of the data in a multi-task learning setup. In particular, we prove that the representation that emerges in the WTA bottleneck is highly symbolic, where a single neuron or a population of neurons encodes the presence of a single abstract feature such as a specific object, color, or position. We furthermore show empirically on two datasets, that this also holds for architectures and setups that do not fully comply with the assumptions of our theorem and demonstrate the advantages of the acquired symbolic representation for generalization. Our proposed model provides insights into the generalization capabilities of deep neural networks with WTA-like components and may serve as an interface between symbolic and subsymbolic AI systems.
A Scalable Hybrid Training Approach for Recurrent Spiking Neural Networks
Jun 17, 2025Recurrent spiking neural networks (RSNNs) can be implemented very efficiently in neuromorphic systems. Nevertheless, training of these models with powerful gradient-based learning algorithms is mostly performed on standard digital hardware using Backpropagation through time (BPTT). However, BPTT has substantial limitations. It does not permit online training and its memory consumption scales linearly with the number of computation steps. In contrast, learning methods using forward propagation of gradients operate in an online manner with a memory consumption independent of the number of time steps. These methods enable SNNs to learn from continuous, infinite-length input sequences. Yet, slow execution speed on conventional hardware as well as inferior performance has hindered their widespread application. In this work, we introduce HYbrid PRopagation (HYPR) that combines the efficiency of parallelization with approximate online forward learning. Our algorithm yields high-throughput online learning through parallelization, paired with constant, i.e., sequence length independent, memory demands. HYPR enables parallelization of parameter update computation over the sub sequences for RSNNs consisting of almost arbitrary non-linear spiking neuron models. We apply HYPR to networks of spiking neurons with oscillatory subthreshold dynamics. We find that this type of neuron model is particularly well trainable by HYPR, resulting in an unprecedentedly low task performance gap between approximate forward gradient learning and BPTT.
Privacy-Aware Lifelong Learning
May 16, 2025

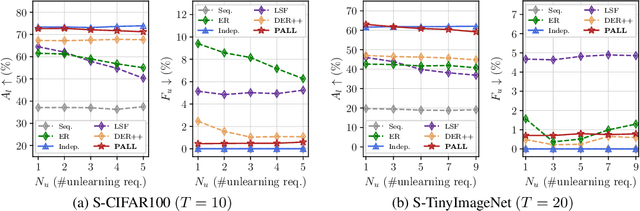

Lifelong learning algorithms enable models to incrementally acquire new knowledge without forgetting previously learned information. Contrarily, the field of machine unlearning focuses on explicitly forgetting certain previous knowledge from pretrained models when requested, in order to comply with data privacy regulations on the right-to-be-forgotten. Enabling efficient lifelong learning with the capability to selectively unlearn sensitive information from models presents a critical and largely unaddressed challenge with contradicting objectives. We address this problem from the perspective of simultaneously preventing catastrophic forgetting and allowing forward knowledge transfer during task-incremental learning, while ensuring exact task unlearning and minimizing memory requirements, based on a single neural network model to be adapted. Our proposed solution, privacy-aware lifelong learning (PALL), involves optimization of task-specific sparse subnetworks with parameter sharing within a single architecture. We additionally utilize an episodic memory rehearsal mechanism to facilitate exact unlearning without performance degradations. We empirically demonstrate the scalability of PALL across various architectures in image classification, and provide a state-of-the-art solution that uniquely integrates lifelong learning and privacy-aware unlearning mechanisms for responsible AI applications.
Advancing Spatio-Temporal Processing in Spiking Neural Networks through Adaptation
Aug 14, 2024

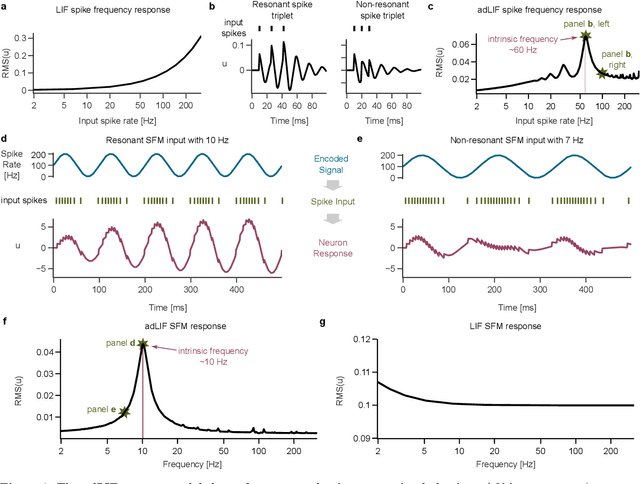

Efficient implementations of spiking neural networks on neuromorphic hardware promise orders of magnitude less power consumption than their non-spiking counterparts. The standard neuron model for spike-based computation on such neuromorphic systems has long been the leaky integrate-and-fire (LIF) neuron. As a promising advancement, a computationally light augmentation of the LIF neuron model with an adaptation mechanism experienced a recent upswing in popularity, caused by demonstrations of its superior performance on spatio-temporal processing tasks. The root of the superiority of these so-called adaptive LIF neurons however, is not well understood. In this article, we thoroughly analyze the dynamical, computational, and learning properties of adaptive LIF neurons and networks thereof. We find that the frequently observed stability problems during training of such networks can be overcome by applying an alternative discretization method that results in provably better stability properties than the commonly used Euler-Forward method. With this discretization, we achieved a new state-of-the-art performance on common event-based benchmark datasets. We also show that the superiority of networks of adaptive LIF neurons extends to the prediction and generation of complex time series. Our further analysis of the computational properties of networks of adaptive LIF neurons shows that they are particularly well suited to exploit the spatio-temporal structure of input sequences. Furthermore, these networks are surprisingly robust to shifts of the mean input strength and input spike rate, even when these shifts were not observed during training. As a consequence, high-performance networks can be obtained without any normalization techniques such as batch normalization or batch-normalization through time.
Learning-to-learn enables rapid learning with phase-change memory-based in-memory computing
Apr 22, 2024There is a growing demand for low-power, autonomously learning artificial intelligence (AI) systems that can be applied at the edge and rapidly adapt to the specific situation at deployment site. However, current AI models struggle in such scenarios, often requiring extensive fine-tuning, computational resources, and data. In contrast, humans can effortlessly adjust to new tasks by transferring knowledge from related ones. The concept of learning-to-learn (L2L) mimics this process and enables AI models to rapidly adapt with only little computational effort and data. In-memory computing neuromorphic hardware (NMHW) is inspired by the brain's operating principles and mimics its physical co-location of memory and compute. In this work, we pair L2L with in-memory computing NMHW based on phase-change memory devices to build efficient AI models that can rapidly adapt to new tasks. We demonstrate the versatility of our approach in two scenarios: a convolutional neural network performing image classification and a biologically-inspired spiking neural network generating motor commands for a real robotic arm. Both models rapidly learn with few parameter updates. Deployed on the NMHW, they perform on-par with their software equivalents. Moreover, meta-training of these models can be performed in software with high-precision, alleviating the need for accurate hardware models.
Adversarially Robust Spiking Neural Networks Through Conversion
Nov 15, 2023



Spiking neural networks (SNNs) provide an energy-efficient alternative to a variety of artificial neural network (ANN) based AI applications. As the progress in neuromorphic computing with SNNs expands their use in applications, the problem of adversarial robustness of SNNs becomes more pronounced. To the contrary of the widely explored end-to-end adversarial training based solutions, we address the limited progress in scalable robust SNN training methods by proposing an adversarially robust ANN-to-SNN conversion algorithm. Our method provides an efficient approach to embrace various computationally demanding robust learning objectives that have been proposed for ANNs. During a post-conversion robust finetuning phase, our method adversarially optimizes both layer-wise firing thresholds and synaptic connectivity weights of the SNN to maintain transferred robustness gains from the pre-trained ANN. We perform experimental evaluations in numerous adaptive adversarial settings that account for the spike-based operation dynamics of SNNs, and show that our approach yields a scalable state-of-the-art solution for adversarially robust deep SNNs with low-latency.
Restoring Vision in Adverse Weather Conditions with Patch-Based Denoising Diffusion Models
Jul 29, 2022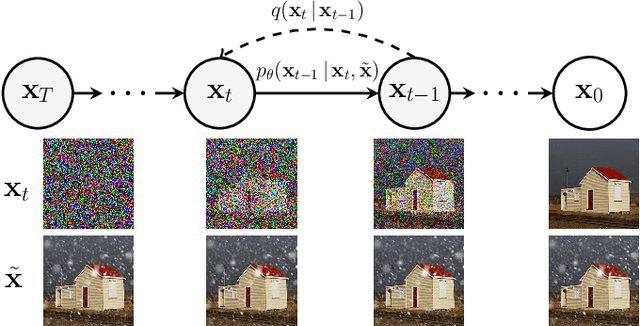


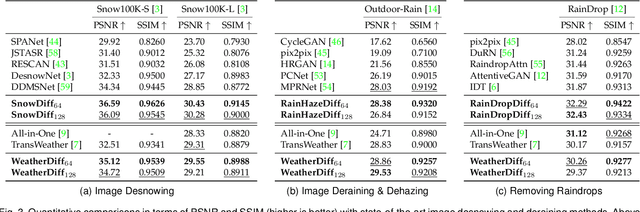
Image restoration under adverse weather conditions has been of significant interest for various computer vision applications. Recent successful methods rely on the current progress in deep neural network architectural designs (e.g., with vision transformers). Motivated by the recent progress achieved with state-of-the-art conditional generative models, we present a novel patch-based image restoration algorithm based on denoising diffusion probabilistic models. Our patch-based diffusion modeling approach enables size-agnostic image restoration by using a guided denoising process with smoothed noise estimates across overlapping patches during inference. We empirically evaluate our model on benchmark datasets for image desnowing, combined deraining and dehazing, and raindrop removal. We demonstrate our approach to achieve state-of-the-art performances on both weather-specific and multi-weather image restoration, and qualitatively show strong generalization to real-world test images.
Memory-enriched computation and learning in spiking neural networks through Hebbian plasticity
May 23, 2022



Memory is a key component of biological neural systems that enables the retention of information over a huge range of temporal scales, ranging from hundreds of milliseconds up to years. While Hebbian plasticity is believed to play a pivotal role in biological memory, it has so far been analyzed mostly in the context of pattern completion and unsupervised learning. Here, we propose that Hebbian plasticity is fundamental for computations in biological neural systems. We introduce a novel spiking neural network architecture that is enriched by Hebbian synaptic plasticity. We show that Hebbian enrichment renders spiking neural networks surprisingly versatile in terms of their computational as well as learning capabilities. It improves their abilities for out-of-distribution generalization, one-shot learning, cross-modal generative association, language processing, and reward-based learning. As spiking neural networks are the basis for energy-efficient neuromorphic hardware, this also suggests that powerful cognitive neuromorphic systems can be build based on this principle.
Many-Joint Robot Arm Control with Recurrent Spiking Neural Networks
Apr 08, 2021
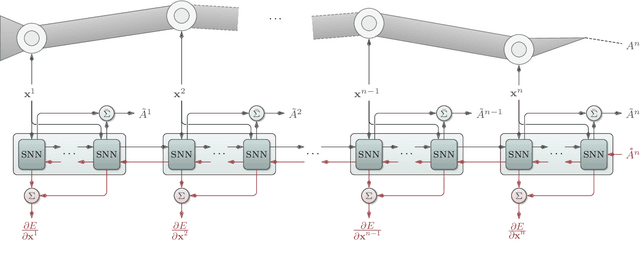
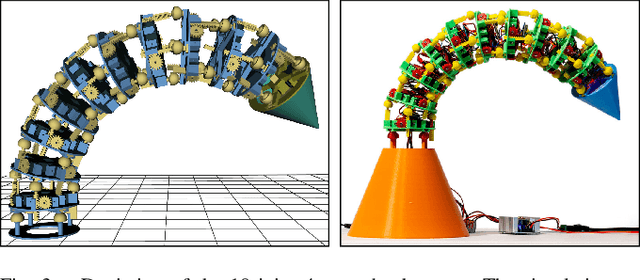
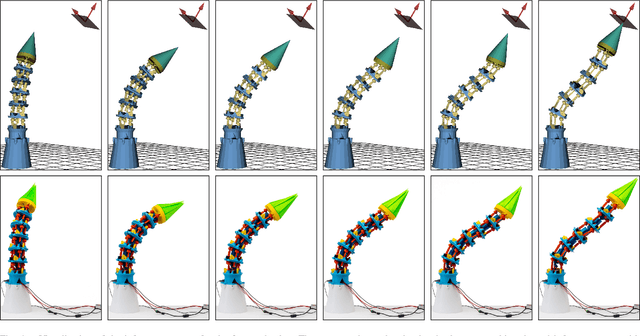
In the paper, we show how scalable, low-cost trunk-like robotic arms can be constructed using only basic 3D-printing equipment and simple electronics. The design is based on uniform, stackable joint modules with three degrees of freedom each. Moreover, we present an approach for controlling these robots with recurrent spiking neural networks. At first, a spiking forward model learns motor-pose correlations from movement observations. After training, intentions can be projected back through unrolled spike trains of the forward model essentially routing the intention-driven motor gradients towards the respective joints, which unfolds goal-direction navigation. We demonstrate that spiking neural networks can thus effectively control trunk-like robotic arms with up to 75 articulated degrees of freedom with near millimeter accuracy.
Oscillatory background activity implements a backbone for sampling-based computations in spiking neural networks
Jun 19, 2020



Various data suggest that the brain carries out probabilistic inference. Models that perform inference through sampling are particularly appealing since instead of requiring networks to perform sophisticated mathematical operations, they can simply exploit stochasticity in neuron behavior. However, sampling from complex distributions is a hard problem. In particular, mixing behavior is often very sensitive to the temperature parameter which controls the stochasticity of the sampler. We propose that background oscillations, an ubiquitous phenomenon throughout the brain, can mitigate this issue and thus implement the backbone for sampling-based computations in spiking neural networks. We first show that both in current-based and conductance-based neuron models, the level of background activity effectively defines the sampling temperature of the network. This mechanism allows brain networks to flexibly control the sampling behavior, either favoring convergence to local optima or promoting mixing. We then demonstrate that background oscillations can in this way structure stochastic computations into discrete sampling episodes. In each such episode, solutions are first explored at high temperatures before annealing to low temperatures favors convergence to a good solution.