 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel Approximation using Analog In-Memory Computing
Nov 05, 2024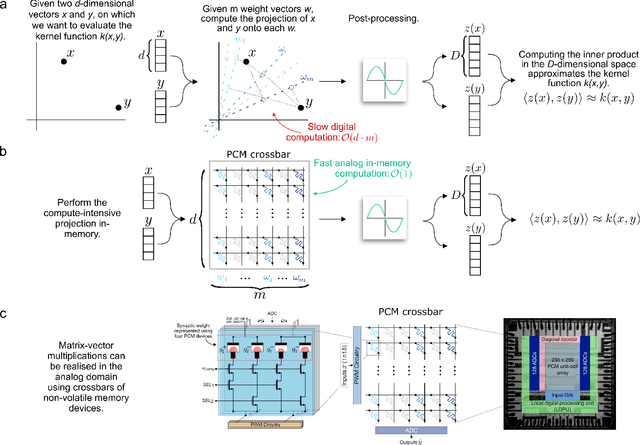
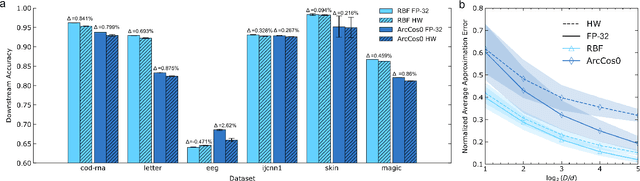
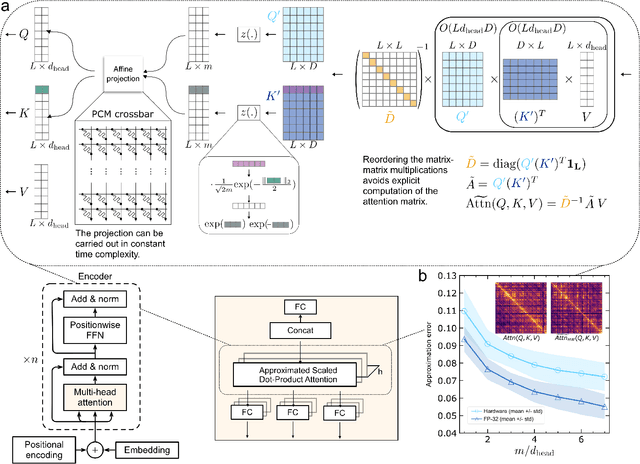
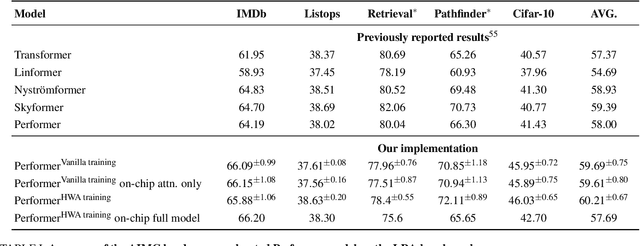
Kernel functions are vital ingredients of several machine learning algorithms, but often incur significant memory and computational costs. We introduce an approach to kernel approximation in machine learning algorithms suitable for mixed-signal Analog In-Memory Computing (AIMC) architectures. Analog In-Memory Kernel Approximation addresses the performance bottlenecks of conventional kernel-based methods by executing most operations in approximate kernel methods directly in memory. The IBM HERMES Project Chip, a state-of-the-art phase-change memory based AIMC chip, is utilized for the hardware demonstration of kernel approximation. Experimental results show that our method maintains high accuracy, with less than a 1% drop in kernel-based ridge classification benchmarks and within 1% accuracy on the Long Range Arena benchmark for kernelized attention in Transformer neural networks. Compared to traditional digital accelerators, our approach is estimated to deliver superior energy efficiency and lower power consumption. These findings highlight the potential of heterogeneous AIMC architectures to enhance the efficiency and scalability of machine learning applications.
Learning-to-learn enables rapid learning with phase-change memory-based in-memory computing
Apr 22, 2024There is a growing demand for low-power, autonomously learning artificial intelligence (AI) systems that can be applied at the edge and rapidly adapt to the specific situation at deployment site. However, current AI models struggle in such scenarios, often requiring extensive fine-tuning, computational resources, and data. In contrast, humans can effortlessly adjust to new tasks by transferring knowledge from related ones. The concept of learning-to-learn (L2L) mimics this process and enables AI models to rapidly adapt with only little computational effort and data. In-memory computing neuromorphic hardware (NMHW) is inspired by the brain's operating principles and mimics its physical co-location of memory and compute. In this work, we pair L2L with in-memory computing NMHW based on phase-change memory devices to build efficient AI models that can rapidly adapt to new tasks. We demonstrate the versatility of our approach in two scenarios: a convolutional neural network performing image classification and a biologically-inspired spiking neural network generating motor commands for a real robotic arm. Both models rapidly learn with few parameter updates. Deployed on the NMHW, they perform on-par with their software equivalents. Moreover, meta-training of these models can be performed in software with high-precision, alleviating the need for accurate hardware models.
A Precision-Optimized Fixed-Point Near-Memory Digital Processing Unit for Analog In-Memory Computing
Feb 12, 2024



Analog In-Memory Computing (AIMC) is an emerging technology for fast and energy-efficient Deep Learning (DL) inference. However, a certain amount of digital post-processing is required to deal with circuit mismatches and non-idealities associated with the memory devices. Efficient near-memory digital logic is critical to retain the high area/energy efficiency and low latency of AIMC. Existing systems adopt Floating Point 16 (FP16) arithmetic with limited parallelization capability and high latency. To overcome these limitations, we propose a Near-Memory digital Processing Unit (NMPU) based on fixed-point arithmetic. It achieves competitive accuracy and higher computing throughput than previous approaches while minimizing the area overhead. Moreover, the NMPU supports standard DL activation steps, such as ReLU and Batch Normalization. We perform a physical implementation of the NMPU design in a 14 nm CMOS technology and provide detailed performance, power, and area assessments. We validate the efficacy of the NMPU by using data from an AIMC chip and demonstrate that a simulated AIMC system with the proposed NMPU outperforms existing FP16-based implementations, providing 139$\times$ speed-up, 7.8$\times$ smaller area, and a competitive power consumption. Additionally, our approach achieves an inference accuracy of 86.65 %/65.06 %, with an accuracy drop of just 0.12 %/0.4 % compared to the FP16 baseline when benchmarked with ResNet9/ResNet32 networks trained on the CIFAR10/CIFAR100 datasets, respectively.