 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowState: Sampling Rate Invariant Time Series Forecasting
Aug 07, 2025



Foundation models (FMs) have transformed natural language processing, but their success has not yet translated to time series forecasting. Existing time series foundation models (TSFMs), often based on transformer variants, struggle with generalization across varying context and target lengths, lack adaptability to different sampling rates, and are computationally inefficient. We introduce FlowState, a novel TSFM architecture that addresses these challenges through two key innovations: a state space model (SSM) based encoder and a functional basis decoder. This design enables continuous-time modeling and dynamic time-scale adjustment, allowing FlowState to inherently generalize across all possible temporal resolutions, and dynamically adjust the forecasting horizons. In contrast to other state-of-the-art TSFMs, which require training data across all possible sampling rates to memorize patterns at each scale, FlowState inherently adapts its internal dynamics to the input scale, enabling smaller models, reduced data requirements, and improved efficiency. We further propose an efficient pretraining strategy that improves robustness and accelerates training. Despite being the smallest model, FlowState outperforms all other models and is state-of-the-art for the GIFT-ZS and the Chronos-ZS benchmarks. Ablation studies confirm the effectiveness of its components, and we demonstrate its unique ability to adapt online to varying input sampling rates.
Mind the GAP: Glimpse-based Active Perception improves generalization and sample efficiency of visual reasoning
Sep 30, 2024Human capabilities in understanding visual relations are far superior to those of AI systems, especially for previously unseen objects. For example, while AI systems struggle to determine whether two such objects are visually the same or different, humans can do so with ease. Active vision theories postulate that the learning of visual relations is grounded in actions that we take to fixate objects and their parts by moving our eyes. In particular, the low-dimensional spatial information about the corresponding eye movements is hypothesized to facilitate the representation of relations between different image parts. Inspired by these theories, we develop a system equipped with a novel Glimpse-based Active Perception (GAP) that sequentially glimpses at the most salient regions of the input image and processes them at high resolution. Importantly, our system leverages the locations stemming from the glimpsing actions, along with the visual content around them, to represent relations between different parts of the image. The results suggest that the GAP is essential for extracting visual relations that go beyond the immediate visual content. Our approach reaches state-of-the-art performance on several visual reasoning tasks being more sample-efficient, and generalizing better to out-of-distribution visual inputs than prior models.
Learning-to-learn enables rapid learning with phase-change memory-based in-memory computing
Apr 22, 2024There is a growing demand for low-power, autonomously learning artificial intelligence (AI) systems that can be applied at the edge and rapidly adapt to the specific situation at deployment site. However, current AI models struggle in such scenarios, often requiring extensive fine-tuning, computational resources, and data. In contrast, humans can effortlessly adjust to new tasks by transferring knowledge from related ones. The concept of learning-to-learn (L2L) mimics this process and enables AI models to rapidly adapt with only little computational effort and data. In-memory computing neuromorphic hardware (NMHW) is inspired by the brain's operating principles and mimics its physical co-location of memory and compute. In this work, we pair L2L with in-memory computing NMHW based on phase-change memory devices to build efficient AI models that can rapidly adapt to new tasks. We demonstrate the versatility of our approach in two scenarios: a convolutional neural network performing image classification and a biologically-inspired spiking neural network generating motor commands for a real robotic arm. Both models rapidly learn with few parameter updates. Deployed on the NMHW, they perform on-par with their software equivalents. Moreover, meta-training of these models can be performed in software with high-precision, alleviating the need for accurate hardware models.
Efficient Biologically Plausible Adversarial Training
Oct 05, 2023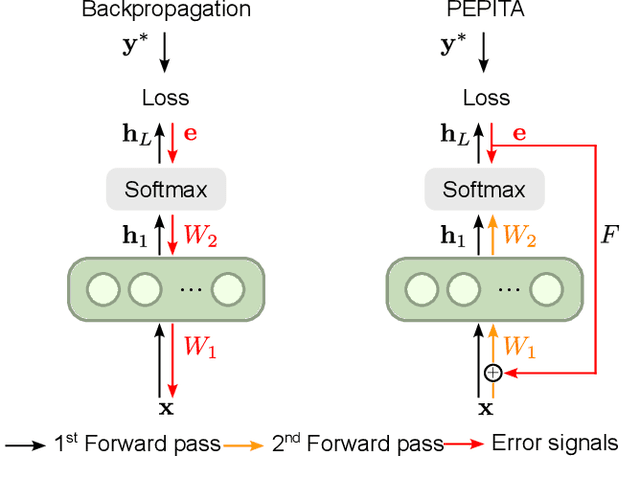


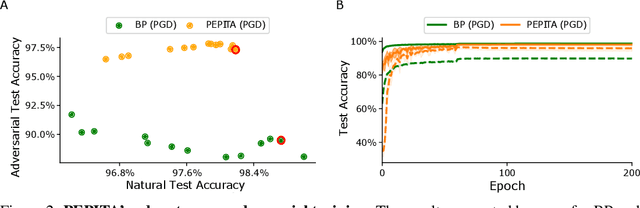
Artificial Neural Networks (ANNs) trained with Backpropagation (BP) show astounding performance and are increasingly often used in performing our daily life tasks. However, ANNs are highly vulnerable to adversarial attacks, which alter inputs with small targeted perturbations that drastically disrupt the models' performance. The most effective method to make ANNs robust against these attacks is adversarial training, in which the training dataset is augmented with exemplary adversarial samples. Unfortunately, this approach has the drawback of increased training complexity since generating adversarial samples is very computationally demanding. In contrast to ANNs, humans are not susceptible to adversarial attacks. Therefore, in this work, we investigate whether biologically-plausible learning algorithms are more robust against adversarial attacks than BP. In particular, we present an extensive comparative analysis of the adversarial robustness of BP and Present the Error to Perturb the Input To modulate Activity (PEPITA), a recently proposed biologically-plausible learning algorithm, on various computer vision tasks. We observe that PEPITA has higher intrinsic adversarial robustness and, with adversarial training, has a more favourable natural-vs-adversarial performance trade-off as, for the same natural accuracies, PEPITA's adversarial accuracies decrease in average by 0.26% and BP's by 8.05%.
Are training trajectories of deep single-spike and deep ReLU network equivalent?
Jun 14, 2023Communication by binary and sparse spikes is a key factor for the energy efficiency of biological brains. However, training deep spiking neural networks (SNNs) with backpropagation is harder than with artificial neural networks (ANNs), which is puzzling given that recent theoretical results provide exact mapping algorithms from ReLU to time-to-first-spike (TTFS) SNNs. Building upon these results, we analyze in theory and in simulation the learning dynamics of TTFS-SNNs. Our analysis highlights that even when an SNN can be mapped exactly to a ReLU network, it cannot always be robustly trained by gradient descent. The reason for that is the emergence of a specific instance of the vanishing-or-exploding gradient problem leading to a bias in the gradient descent trajectory in comparison with the equivalent ANN. After identifying this issue we derive a generic solution for the network initialization and SNN parameterization which guarantees that the SNN can be trained as robustly as its ANN counterpart. Our theoretical findings are illustrated in practice on image classification datasets. Our method achieves the same accuracy as deep ConvNets on CIFAR10 and enables fine-tuning on the much larger PLACES365 dataset without loss of accuracy compared to the ANN. We argue that the combined perspective of conversion and fine-tuning with robust gradient descent in SNN will be decisive to optimize SNNs for hardware implementations needing low latency and resilience to noise and quantization.
Online Spatio-Temporal Learning with Target Projection
Apr 26, 2023



Recurrent neural networks trained with the backpropagation through time (BPTT) algorithm have led to astounding successes in various temporal tasks. However, BPTT introduces severe limitations, such as the requirement to propagate information backwards through time, the weight symmetry requirement, as well as update-locking in space and time. These problems become roadblocks for AI systems where online training capabilities are vital. Recently, researchers have developed biologically-inspired training algorithms, addressing a subset of those problems. In this work, we propose a novel learning algorithm called online spatio-temporal learning with target projection (OSTTP) that resolves all aforementioned issues of BPTT. In particular, OSTTP equips a network with the capability to simultaneously process and learn from new incoming data, alleviating the weight symmetry and update-locking problems. We evaluate OSTTP on two temporal tasks, showcasing competitive performance compared to BPTT. Moreover, we present a proof-of-concept implementation of OSTTP on a memristive neuromorphic hardware system, demonstrating its versatility and applicability to resource-constrained AI devices.
Neuromorphic Optical Flow and Real-time Implementation with Event Cameras
Apr 14, 2023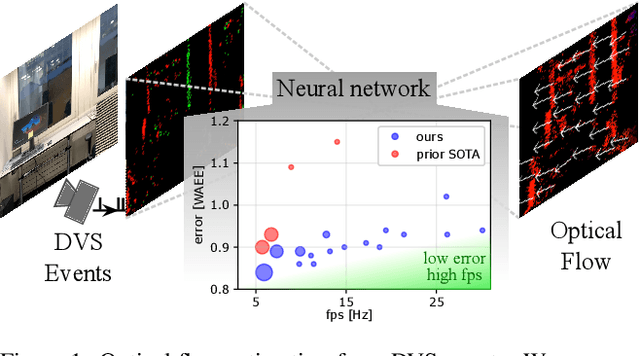
Optical flow provides information on relative motion that is an important component in many computer vision pipelines. Neural networks provide high accuracy optical flow, yet their complexity is often prohibitive for application at the edge or in robots, where efficiency and latency play crucial role. To address this challenge, we build on the latest developments in event-based vision and spiking neural networks. We propose a new network architecture, inspired by Timelens, that improves the state-of-the-art self-supervised optical flow accuracy when operated both in spiking and non-spiking mode. To implement a real-time pipeline with a physical event camera, we propose a methodology for principled model simplification based on activity and latency analysis. We demonstrate high speed optical flow prediction with almost two orders of magnitude reduced complexity while maintaining the accuracy, opening the path for real-time deployments.
Dynamic Event-based Optical Identification and Communication
Mar 14, 2023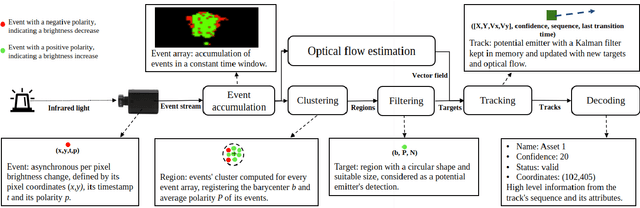

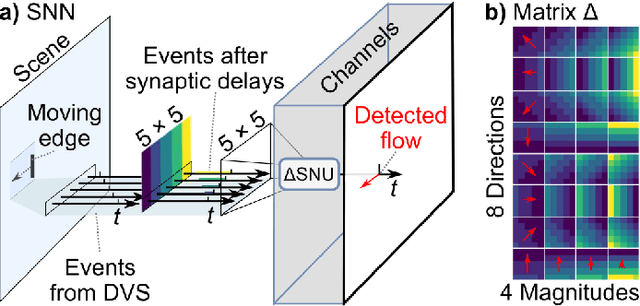
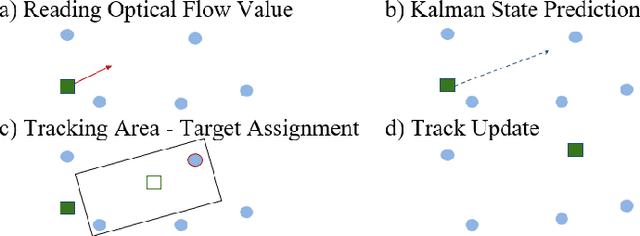
Optical identification is often done with spatial or temporal visual pattern recognition and localization. Temporal pattern recognition, depending on the technology, involves a trade-off between communication frequency, range and accurate tracking. We propose a solution with light-emitting beacons that improves this trade-off by exploiting fast event-based cameras and, for tracking, sparse neuromorphic optical flow computed with spiking neurons. In an asset monitoring use case, we demonstrate that the system, embedded in a simulated drone, is robust to relative movements and enables simultaneous communication with, and tracking of, multiple moving beacons. Finally, in a hardware lab prototype, we achieve state-of-the-art optical camera communication frequencies in the kHz magnitude.
An Exact Mapping From ReLU Networks to Spiking Neural Networks
Dec 23, 2022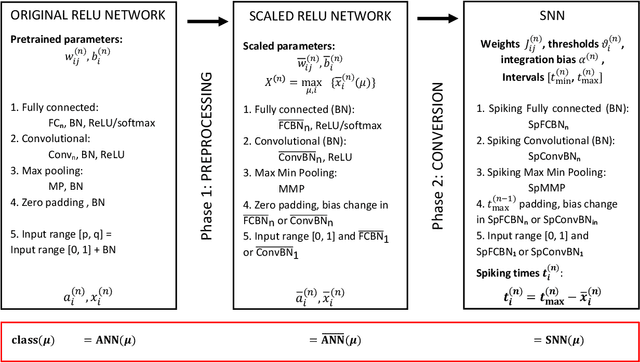
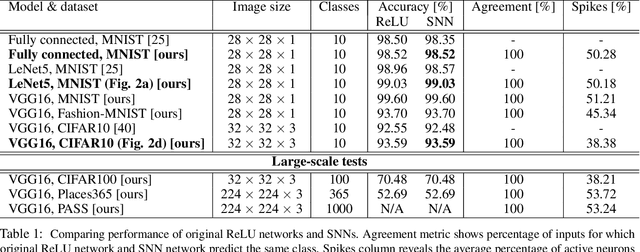
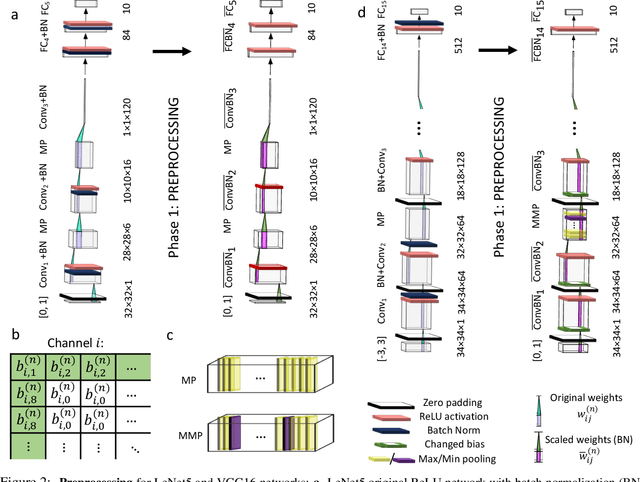
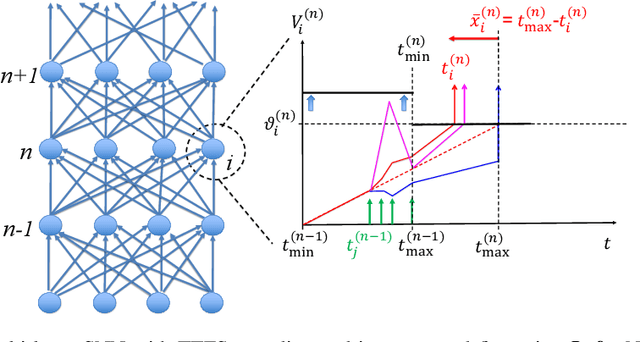
Deep spiking neural networks (SNNs) offer the promise of low-power artificial intelligence. However, training deep SNNs from scratch or converting deep artificial neural networks to SNNs without loss of performance has been a challenge. Here we propose an exact mapping from a network with Rectified Linear Units (ReLUs) to an SNN that fires exactly one spike per neuron. For our constructive proof, we assume that an arbitrary multi-layer ReLU network with or without convolutional layers, batch normalization and max pooling layers was trained to high performance on some training set. Furthermore, we assume that we have access to a representative example of input data used during training and to the exact parameters (weights and biases) of the trained ReLU network. The mapping from deep ReLU networks to SNNs causes zero percent drop in accuracy on CIFAR10, CIFAR100 and the ImageNet-like data sets Places365 and PASS. More generally our work shows that an arbitrary deep ReLU network can be replaced by an energy-efficient single-spike neural network without any loss of performance.
On the visual analytic intelligence of neural networks
Sep 28, 2022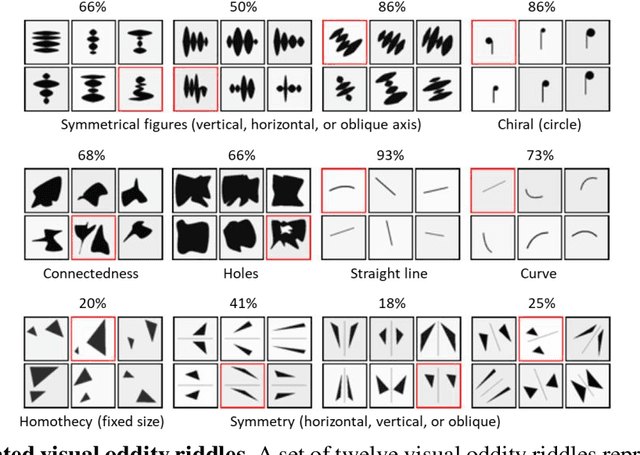
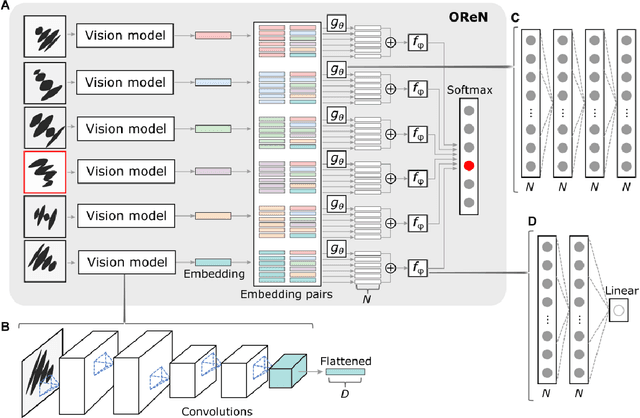
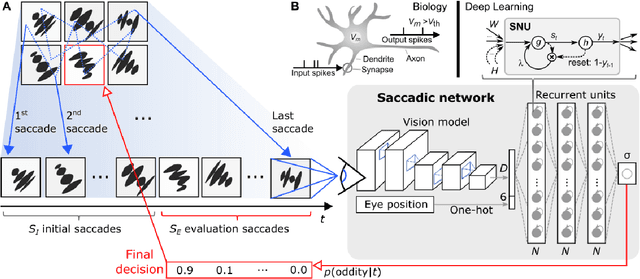
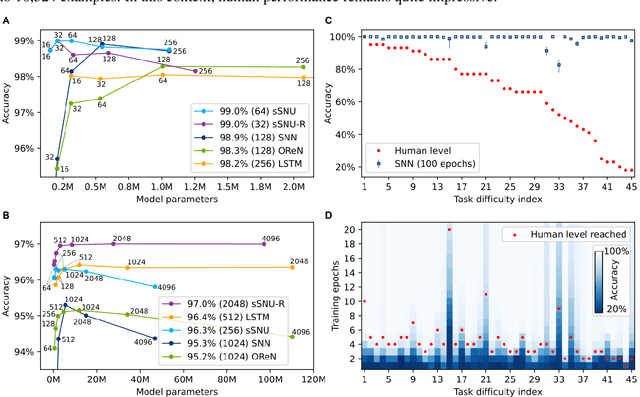
Visual oddity task was conceived as a universal ethnic-independent analytic intelligence test for humans. Advancements in artificial intelligence led to important breakthroughs, yet competing with humans on such analytic intelligence tasks remains challenging and typically resorts to non-biologically-plausible architectures. We present a biologically realistic system that receives inputs from synthetic eye movements - saccades, and processes them with neurons incorporating dynamics of neocortical neurons. We introduce a procedurally generated visual oddity dataset to train an architecture extending conventional relational networks and our proposed system. Both approaches surpass the human accuracy, and we uncover that both share the same essential underlying mechanism of reasoning. Finally, we show that the biologically inspired network achieves superior accuracy, learns faster and requires fewer parameters than the conventional network.