 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated Predictive Coding Networks via Direct Kolen-Pollack Feedback Alignment
Feb 17, 2026Predictive coding (PC) is a biologically inspired algorithm for training neural networks that relies only on local updates, allowing parallel learning across layers. However, practical implementations face two key limitations: error signals must still propagate from the output to early layers through multiple inference-phase steps, and feedback decays exponentially during this process, leading to vanishing updates in early layers. We propose direct Kolen-Pollack predictive coding (DKP-PC), which simultaneously addresses both feedback delay and exponential decay, yielding a more efficient and scalable variant of PC while preserving update locality. Leveraging direct feedback alignment and direct Kolen-Pollack algorithms, DKP-PC introduces learnable feedback connections from the output layer to all hidden layers, establishing a direct pathway for error transmission. This yields an algorithm that reduces the theoretical error propagation time complexity from O(L), with L being the network depth, to O(1), removing depth-dependent delay in error signals. Moreover, empirical results demonstrate that DKP-PC achieves performance at least comparable to, and often exceeding, that of standard PC, while offering improved latency and computational performance, supporting its potential for custom hardware-efficient implementations.
Bio-Inspired Artificial Neural Networks based on Predictive Coding
Aug 12, 2025Backpropagation (BP) of errors is the backbone training algorithm for artificial neural networks (ANNs). It updates network weights through gradient descent to minimize a loss function representing the mismatch between predictions and desired outputs. BP uses the chain rule to propagate the loss gradient backward through the network hierarchy, allowing efficient weight updates. However, this process requires weight updates at every layer to rely on a global error signal generated at the network's output. In contrast, the Hebbian model of synaptic plasticity states that weight updates are local, depending only on the activity of pre- and post-synaptic neurons. This suggests biological brains likely do not implement BP directly. Recently, Predictive Coding (PC) has gained interest as a biologically plausible alternative that updates weights using only local information. Originating from 1950s work on signal compression, PC was later proposed as a model of the visual cortex and formalized under the free energy principle, linking it to Bayesian inference and dynamical systems. PC weight updates rely solely on local information and provide theoretical advantages such as automatic scaling of gradients based on uncertainty. This lecture notes column offers a novel, tutorial-style introduction to PC, focusing on its formulation, derivation, and connections to well-known optimization and signal processing algorithms such as BP and the Kalman Filter (KF). It aims to support existing literature by guiding readers from the mathematical foundations of PC to practical implementation, including Python examples using PyTorch.
MesaNet: Sequence Modeling by Locally Optimal Test-Time Training
Jun 05, 2025Sequence modeling is currently dominated by causal transformer architectures that use softmax self-attention. Although widely adopted, transformers require scaling memory and compute linearly during inference. A recent stream of work linearized the softmax operation, resulting in powerful recurrent neural network (RNN) models with constant memory and compute costs such as DeltaNet, Mamba or xLSTM. These models can be unified by noting that their recurrent layer dynamics can all be derived from an in-context regression objective, approximately optimized through an online learning rule. Here, we join this line of work and introduce a numerically stable, chunkwise parallelizable version of the recently proposed Mesa layer (von Oswald et al., 2024), and study it in language modeling at the billion-parameter scale. This layer again stems from an in-context loss, but which is now minimized to optimality at every time point using a fast conjugate gradient solver. Through an extensive suite of experiments, we show that optimal test-time training enables reaching lower language modeling perplexity and higher downstream benchmark performance than previous RNNs, especially on tasks requiring long context understanding. This performance gain comes at the cost of additional flops spent during inference time. Our results are therefore intriguingly related to recent trends of increasing test-time compute to improve performance -- here by spending compute to solve sequential optimization problems within the neural network itself.
Chameleon: A MatMul-Free Temporal Convolutional Network Accelerator for End-to-End Few-Shot and Continual Learning from Sequential Data
May 30, 2025On-device learning at the edge enables low-latency, private personalization with improved long-term robustness and reduced maintenance costs. Yet, achieving scalable, low-power end-to-end on-chip learning, especially from real-world sequential data with a limited number of examples, is an open challenge. Indeed, accelerators supporting error backpropagation optimize for learning performance at the expense of inference efficiency, while simplified learning algorithms often fail to reach acceptable accuracy targets. In this work, we present Chameleon, leveraging three key contributions to solve these challenges. (i) A unified learning and inference architecture supports few-shot learning (FSL), continual learning (CL) and inference at only 0.5% area overhead to the inference logic. (ii) Long temporal dependencies are efficiently captured with temporal convolutional networks (TCNs), enabling the first demonstration of end-to-end on-chip FSL and CL on sequential data and inference on 16-kHz raw audio. (iii) A dual-mode, matrix-multiplication-free compute array allows either matching the power consumption of state-of-the-art inference-only keyword spotting (KWS) accelerators or enabling $4.3\times$ higher peak GOPS. Fabricated in 40-nm CMOS, Chameleon sets new accuracy records on Omniglot for end-to-end on-chip FSL (96.8%, 5-way 1-shot, 98.8%, 5-way 5-shot) and CL (82.2% final accuracy for learning 250 classes with 10 shots), while maintaining an inference accuracy of 93.3% on the 12-class Google Speech Commands dataset at an extreme-edge power budget of 3.1 $\mu$W.
TESS: A Scalable Temporally and Spatially Local Learning Rule for Spiking Neural Networks
Feb 03, 2025The demand for low-power inference and training of deep neural networks (DNNs) on edge devices has intensified the need for algorithms that are both scalable and energy-efficient. While spiking neural networks (SNNs) allow for efficient inference by processing complex spatio-temporal dynamics in an event-driven fashion, training them on resource-constrained devices remains challenging due to the high computational and memory demands of conventional error backpropagation (BP)-based approaches. In this work, we draw inspiration from biological mechanisms such as eligibility traces, spike-timing-dependent plasticity, and neural activity synchronization to introduce TESS, a temporally and spatially local learning rule for training SNNs. Our approach addresses both temporal and spatial credit assignments by relying solely on locally available signals within each neuron, thereby allowing computational and memory overheads to scale linearly with the number of neurons, independently of the number of time steps. Despite relying on local mechanisms, we demonstrate performance comparable to the backpropagation through time (BPTT) algorithm, within $\sim1.4$ accuracy points on challenging computer vision scenarios relevant at the edge, such as the IBM DVS Gesture dataset, CIFAR10-DVS, and temporal versions of CIFAR10, and CIFAR100. Being able to produce comparable performance to BPTT while keeping low time and memory complexity, TESS enables efficient and scalable on-device learning at the edge.
An Event-Based Digital Compute-In-Memory Accelerator with Flexible Operand Resolution and Layer-Wise Weight/Output Stationarity
Oct 30, 2024Compute-in-memory (CIM) accelerators for spiking neural networks (SNNs) are promising solutions to enable $\mu$s-level inference latency and ultra-low energy in edge vision applications. Yet, their current lack of flexibility at both the circuit and system levels prevents their deployment in a wide range of real-life scenarios. In this work, we propose a novel digital CIM macro that supports arbitrary operand resolution and shape, with a unified CIM storage for weights and membrane potentials. These circuit-level techniques enable a hybrid weight- and output-stationary dataflow at the system level to maximize operand reuse, thereby minimizing costly on- and off-chip data movements during the SNN execution. Measurement results of a fabricated FlexSpIM prototype in 40-nm CMOS demonstrate a 2$\times$ increase in bit-normalized energy efficiency compared to prior fixed-precision digital CIM-SNNs, while providing resolution reconfiguration with bitwise granularity. Our approach can save up to 90% energy in large-scale systems, while reaching a state-of-the-art classification accuracy of 95.8% on the IBM DVS gesture dataset.
Training and inference in the ReckON RSNN architecture implemented on a MPSoC
May 21, 2024

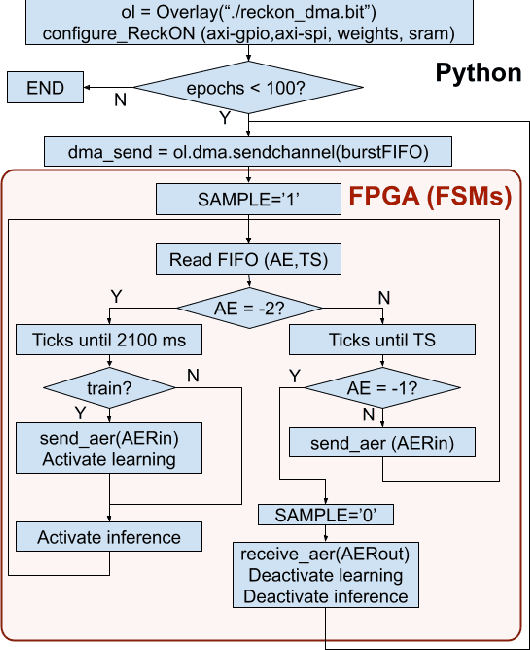

With the rise of artificial intelligence, biological neuron models are being used to implement neural networks that can learn certain tasks after a training phase. One type of such networks are spiking neural networks (SNNs) that rely on a simplified model for biological neurons, the Integrate and Fire neuron. Several accelerators have emerged to implement SNNs with this kind of neuron. The ReckON system is one of these that allows both the training and execution of a recurrent SNN. The ReckON architecture, implemented on a custom ASIC, can be fully described using a hardware description language. In this work, we adapt the Verilog description to implement it on a Xilinx Multiprocessor System on Chip system (MPSoC). We present the circuits required for the efficient operation of the system, and a Python framework to use it on the Pynq ZU platform. We validate the architecture and implementation in two different scenarios, and show how the simulated accuracy is preserved with a peak performance of 3.8M events processed per second.
EvGNN: An Event-driven Graph Neural Network Accelerator for Edge Vision
Apr 30, 2024



Edge vision systems combining sensing and embedded processing promise low-latency, decentralized, and energy-efficient solutions that forgo reliance on the cloud. As opposed to conventional frame-based vision sensors, event-based cameras deliver a microsecond-scale temporal resolution with sparse information encoding, thereby outlining new opportunities for edge vision systems. However, mainstream algorithms for frame-based vision, which mostly rely on convolutional neural networks (CNNs), can hardly exploit the advantages of event-based vision as they are typically optimized for dense matrix-vector multiplications. While event-driven graph neural networks (GNNs) have recently emerged as a promising solution for sparse event-based vision, their irregular structure is a challenge that currently hinders the design of efficient hardware accelerators. In this paper, we propose EvGNN, the first event-driven GNN accelerator for low-footprint, ultra-low-latency, and high-accuracy edge vision with event-based cameras. It relies on three central ideas: (i) directed dynamic graphs exploiting single-hop nodes with edge-free storage, (ii) event queues for the efficient identification of local neighbors within a spatiotemporally decoupled search range, and (iii) a novel layer-parallel processing scheme enabling the low-latency execution of multi-layer GNNs. We deployed EvGNN on a Xilinx KV260 Ultrascale+ MPSoC platform and benchmarked it on the N-CARS dataset for car recognition, demonstrating a classification accuracy of 87.8% and an average latency per event of 16$\mu$s, thereby enabling real-time, microsecond-resolution event-based vision at the edge.
Active Dendrites Enable Efficient Continual Learning in Time-To-First-Spike Neural Networks
Apr 30, 2024
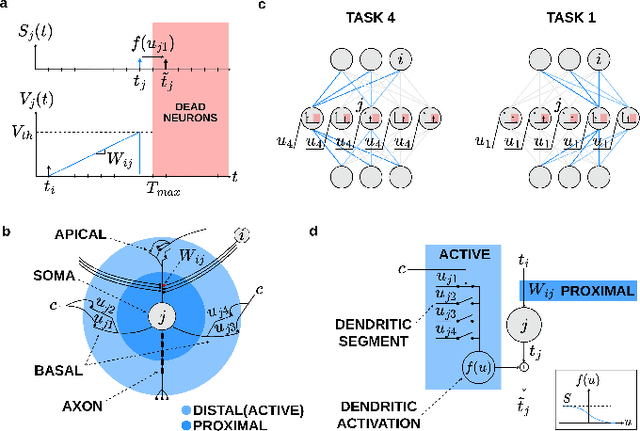
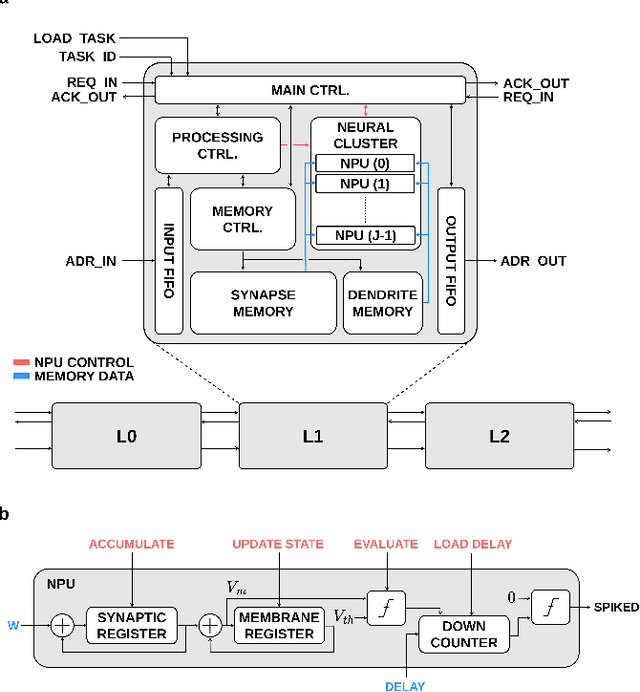
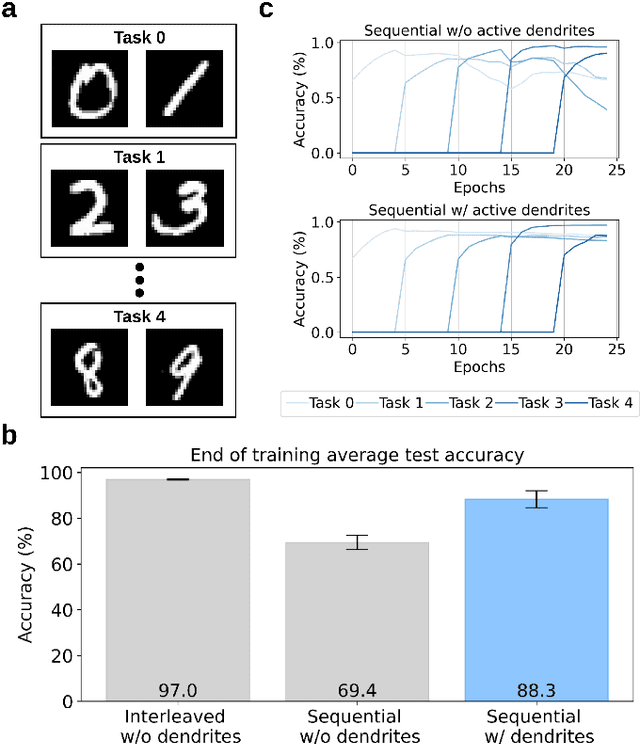
While the human brain efficiently adapts to new tasks from a continuous stream of information, neural network models struggle to learn from sequential information without catastrophically forgetting previously learned tasks. This limitation presents a significant hurdle in deploying edge devices in real-world scenarios where information is presented in an inherently sequential manner. Active dendrites of pyramidal neurons play an important role in the brain ability to learn new tasks incrementally. By exploiting key properties of time-to-first-spike encoding and leveraging its high sparsity, we present a novel spiking neural network model enhanced with active dendrites. Our model can efficiently mitigate catastrophic forgetting in temporally-encoded SNNs, which we demonstrate with an end-of-training accuracy across tasks of 88.3% on the test set using the Split MNIST dataset. Furthermore, we provide a novel digital hardware architecture that paves the way for real-world deployment in edge devices. Using a Xilinx Zynq-7020 SoC FPGA, we demonstrate a 100-% match with our quantized software model, achieving an average inference time of 37.3 ms and an 80.0% accuracy.
SPAIC: A sub-$μ$W/Channel, 16-Channel General-Purpose Event-Based Analog Front-End with Dual-Mode Encoders
Aug 31, 2023



Low-power event-based analog front-ends (AFE) are a crucial component required to build efficient end-to-end neuromorphic processing systems for edge computing. Although several neuromorphic chips have been developed for implementing spiking neural networks (SNNs) and solving a wide range of sensory processing tasks, there are only a few general-purpose analog front-end devices that can be used to convert analog sensory signals into spikes and interfaced to neuromorphic processors. In this work, we present a novel, highly configurable analog front-end chip, denoted as SPAIC (signal-to-spike converter for analog AI computation), that offers a general-purpose dual-mode analog signal-to-spike encoding with delta modulation and pulse frequency modulation, with tunable frequency bands. The ASIC is designed in a 180 nm process. It supports and encodes a wide variety of signals spanning 4 orders of magnitude in frequency, and provides an event-based output that is compatible with existing neuromorphic processors. We validated the ASIC for its functions and present initial silicon measurement results characterizing the basic building blocks of the chip.