 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTESS: A Scalable Temporally and Spatially Local Learning Rule for Spiking Neural Networks
Feb 03, 2025The demand for low-power inference and training of deep neural networks (DNNs) on edge devices has intensified the need for algorithms that are both scalable and energy-efficient. While spiking neural networks (SNNs) allow for efficient inference by processing complex spatio-temporal dynamics in an event-driven fashion, training them on resource-constrained devices remains challenging due to the high computational and memory demands of conventional error backpropagation (BP)-based approaches. In this work, we draw inspiration from biological mechanisms such as eligibility traces, spike-timing-dependent plasticity, and neural activity synchronization to introduce TESS, a temporally and spatially local learning rule for training SNNs. Our approach addresses both temporal and spatial credit assignments by relying solely on locally available signals within each neuron, thereby allowing computational and memory overheads to scale linearly with the number of neurons, independently of the number of time steps. Despite relying on local mechanisms, we demonstrate performance comparable to the backpropagation through time (BPTT) algorithm, within $\sim1.4$ accuracy points on challenging computer vision scenarios relevant at the edge, such as the IBM DVS Gesture dataset, CIFAR10-DVS, and temporal versions of CIFAR10, and CIFAR100. Being able to produce comparable performance to BPTT while keeping low time and memory complexity, TESS enables efficient and scalable on-device learning at the edge.
CODE-CL: COnceptor-Based Gradient Projection for DEep Continual Learning
Nov 21, 2024Continual learning, or the ability to progressively integrate new concepts, is fundamental to intelligent beings, enabling adaptability in dynamic environments. In contrast, artificial deep neural networks face the challenge of catastrophic forgetting when learning new tasks sequentially. To alleviate the problem of forgetting, recent approaches aim to preserve essential weight subspaces for previous tasks by limiting updates to orthogonal subspaces via gradient projection. While effective, this approach can lead to suboptimal performance, particularly when tasks are highly correlated. In this work, we introduce COnceptor-based gradient projection for DEep Continual Learning (CODE-CL), a novel method that leverages conceptor matrix representations, a computational model inspired by neuroscience, to more flexibly handle highly correlated tasks. CODE-CL encodes directional importance within the input space of past tasks, allowing new knowledge integration in directions modulated by $1-S$, where $S$ represents the direction's relevance for prior tasks. Additionally, we analyze task overlap using conceptor-based representations to identify highly correlated tasks, facilitating efficient forward knowledge transfer through scaled projection within their intersecting subspace. This strategy enhances flexibility, allowing learning in correlated tasks without significantly disrupting previous knowledge. Extensive experiments on continual learning image classification benchmarks validate CODE-CL's efficacy, showcasing superior performance with minimal forgetting, outperforming most state-of-the-art methods.
LLS: Local Learning Rule for Deep Neural Networks Inspired by Neural Activity Synchronization
May 24, 2024
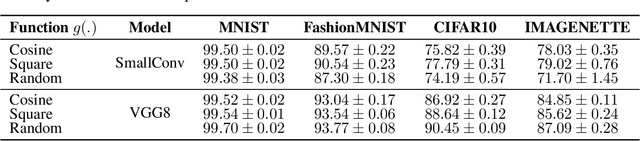
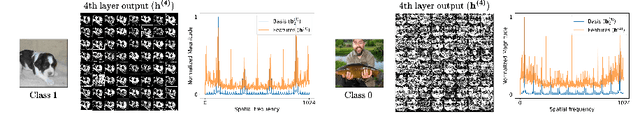

Training deep neural networks (DNNs) using traditional backpropagation (BP) presents challenges in terms of computational complexity and energy consumption, particularly for on-device learning where computational resources are limited. Various alternatives to BP, including random feedback alignment, forward-forward, and local classifiers, have been explored to address these challenges. These methods have their advantages, but they can encounter difficulties when dealing with intricate visual tasks or demand considerable computational resources. In this paper, we propose a novel Local Learning rule inspired by neural activity Synchronization phenomena (LLS) observed in the brain. LLS utilizes fixed periodic basis vectors to synchronize neuron activity within each layer, enabling efficient training without the need for additional trainable parameters. We demonstrate the effectiveness of LLS and its variations, LLS-M and LLS-MxM, on multiple image classification datasets, achieving accuracy comparable to BP with reduced computational complexity and minimal additional parameters. Furthermore, the performance of LLS on the Visual Wake Word (VWW) dataset highlights its suitability for on-device learning tasks, making it a promising candidate for edge hardware implementations.
S-TLLR: STDP-inspired Temporal Local Learning Rule for Spiking Neural Networks
Jun 27, 2023Spiking Neural Networks (SNNs) are biologically plausible models that have been identified as potentially apt for the deployment for energy-efficient intelligence at the edge, particularly for sequential learning tasks. However, training of SNNs poses a significant challenge due to the necessity for precise temporal and spatial credit assignment. Back-propagation through time (BPTT) algorithm, whilst being the most widely used method for addressing these issues, incurs a high computational cost due to its temporal dependency. Moreover, BPTT and its approximations solely utilize causal information derived from the spiking activity to compute the synaptic updates, thus neglecting non-causal relationships. In this work, we propose S-TLLR, a novel three-factor temporal local learning rule inspired by the Spike-Timing Dependent Plasticity (STDP) mechanism, aimed at training SNNs on event-based learning tasks. S-TLLR considers both causal and non-causal relationships between pre and post-synaptic activities, achieving performance comparable to BPTT and enhancing performance relative to methods using only causal information. Furthermore, S-TLLR has low memory and time complexity, which is independent of the number of time steps, rendering it suitable for online learning on low-power devices. To demonstrate the scalability of our proposed method, we have conducted extensive evaluations on event-based datasets spanning a wide range of applications, such as image and gesture recognition, audio classification, and optical flow estimation. In all the experiments, S-TLLR achieved high accuracy with a reduction in the number of computations between $1.1-10\times$.
Hardware/Software co-design with ADC-Less In-memory Computing Hardware for Spiking Neural Networks
Nov 03, 2022Spiking Neural Networks (SNNs) are bio-plausible models that hold great potential for realizing energy-efficient implementations of sequential tasks on resource-constrained edge devices. However, commercial edge platforms based on standard GPUs are not optimized to deploy SNNs, resulting in high energy and latency. While analog In-Memory Computing (IMC) platforms can serve as energy-efficient inference engines, they are accursed by the immense energy, latency, and area requirements of high-precision ADCs (HP-ADC), overshadowing the benefits of in-memory computations. We propose a hardware/software co-design methodology to deploy SNNs into an ADC-Less IMC architecture using sense-amplifiers as 1-bit ADCs replacing conventional HP-ADCs and alleviating the above issues. Our proposed framework incurs minimal accuracy degradation by performing hardware-aware training and is able to scale beyond simple image classification tasks to more complex sequential regression tasks. Experiments on complex tasks of optical flow estimation and gesture recognition show that progressively increasing the hardware awareness during SNN training allows the model to adapt and learn the errors due to the non-idealities associated with ADC-Less IMC. Also, the proposed ADC-Less IMC offers significant energy and latency improvements, $2-7\times$ and $8.9-24.6\times$, respectively, depending on the SNN model and the workload, compared to HP-ADC IMC.