 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRIM: Token-wise Attention-Derived Saliency for Data-Efficient Instruction Tuning
Oct 08, 2025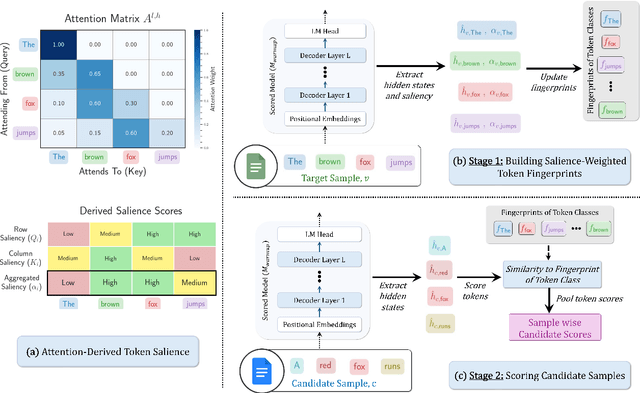
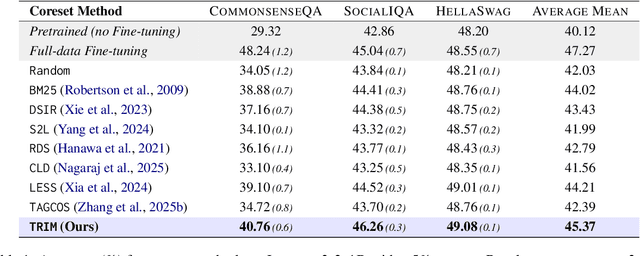
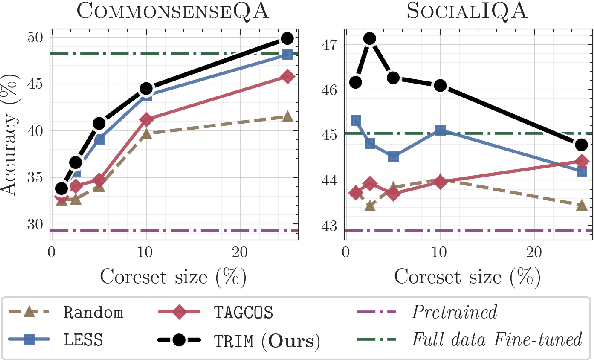

Instruction tuning is essential for aligning large language models (LLMs) to downstream tasks and commonly relies on large, diverse corpora. However, small, high-quality subsets, known as coresets, can deliver comparable or superior results, though curating them remains challenging. Existing methods often rely on coarse, sample-level signals like gradients, an approach that is computationally expensive and overlooks fine-grained features. To address this, we introduce TRIM (Token Relevance via Interpretable Multi-layer Attention), a forward-only, token-centric framework. Instead of using gradients, TRIM operates by matching underlying representational patterns identified via attention-based "fingerprints" from a handful of target samples. Such an approach makes TRIM highly efficient and uniquely sensitive to the structural features that define a task. Coresets selected by our method consistently outperform state-of-the-art baselines by up to 9% on downstream tasks and even surpass the performance of full-data fine-tuning in some settings. By avoiding expensive backward passes, TRIM achieves this at a fraction of the computational cost. These findings establish TRIM as a scalable and efficient alternative for building high-quality instruction-tuning datasets.
ResQ: Mixed-Precision Quantization of Large Language Models with Low-Rank Residuals
Dec 18, 2024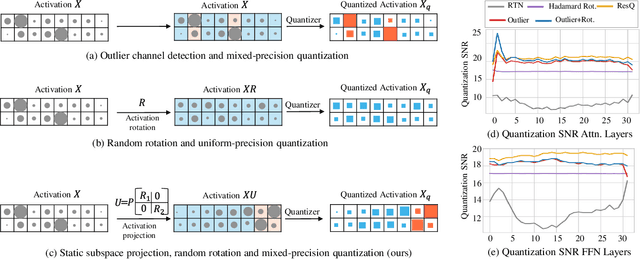
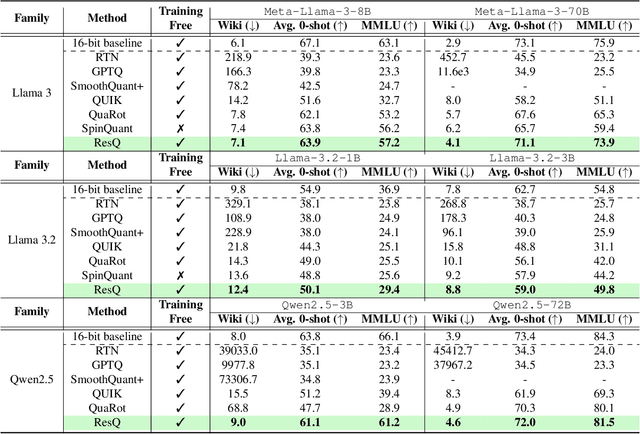
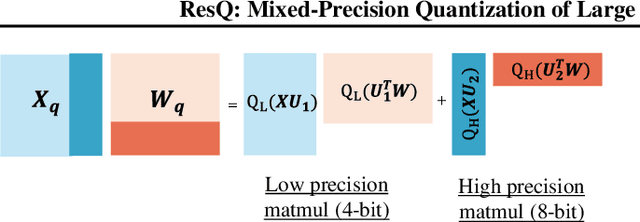

Post-training quantization (PTQ) of large language models (LLMs) holds the promise in reducing the prohibitive computational cost at inference time. Quantization of all weight, activation and key-value (KV) cache tensors to 4-bit without significantly degrading generalizability is challenging, due to the high quantization error caused by extreme outliers in activations. To tackle this problem, we propose ResQ, a PTQ method that pushes further the state-of-the-art. By means of principal component analysis (PCA), it identifies a low-rank subspace (in practice 1/8 of the hidden dimension) in which activation variances are highest, and keep the coefficients within this subspace in high precision, e.g. 8-bit, while quantizing the rest to 4-bit. Within each subspace, invariant random rotation is applied to further suppress outliers. We show that this is a provably optimal mixed precision quantization scheme that minimizes error. With the Llama families of models, we demonstrate that ResQ outperforms recent uniform and mixed precision PTQ methods on a variety of benchmarks, achieving up to 33% lower perplexity on Wikitext than the next best method SpinQuant, and a 2.4x speedup over 16-bit baseline. Code is available at https://github.com/utkarsh-dmx/project-resq.
Eigen Attention: Attention in Low-Rank Space for KV Cache Compression
Aug 10, 2024



Large language models (LLMs) represent a groundbreaking advancement in the domain of natural language processing due to their impressive reasoning abilities. Recently, there has been considerable interest in increasing the context lengths for these models to enhance their applicability to complex tasks. However, at long context lengths and large batch sizes, the key-value (KV) cache, which stores the attention keys and values, emerges as the new bottleneck in memory usage during inference. To address this, we propose Eigen Attention, which performs the attention operation in a low-rank space, thereby reducing the KV cache memory overhead. Our proposed approach is orthogonal to existing KV cache compression techniques and can be used synergistically with them. Through extensive experiments over OPT, MPT, and Llama model families, we demonstrate that Eigen Attention results in up to 40% reduction in KV cache sizes and up to 60% reduction in attention operation latency with minimal drop in performance.
Hardware/Software co-design with ADC-Less In-memory Computing Hardware for Spiking Neural Networks
Nov 03, 2022Spiking Neural Networks (SNNs) are bio-plausible models that hold great potential for realizing energy-efficient implementations of sequential tasks on resource-constrained edge devices. However, commercial edge platforms based on standard GPUs are not optimized to deploy SNNs, resulting in high energy and latency. While analog In-Memory Computing (IMC) platforms can serve as energy-efficient inference engines, they are accursed by the immense energy, latency, and area requirements of high-precision ADCs (HP-ADC), overshadowing the benefits of in-memory computations. We propose a hardware/software co-design methodology to deploy SNNs into an ADC-Less IMC architecture using sense-amplifiers as 1-bit ADCs replacing conventional HP-ADCs and alleviating the above issues. Our proposed framework incurs minimal accuracy degradation by performing hardware-aware training and is able to scale beyond simple image classification tasks to more complex sequential regression tasks. Experiments on complex tasks of optical flow estimation and gesture recognition show that progressively increasing the hardware awareness during SNN training allows the model to adapt and learn the errors due to the non-idealities associated with ADC-Less IMC. Also, the proposed ADC-Less IMC offers significant energy and latency improvements, $2-7\times$ and $8.9-24.6\times$, respectively, depending on the SNN model and the workload, compared to HP-ADC IMC.
On-chip learning in a conventional silicon MOSFET based Analog Hardware Neural Network
Jul 01, 2019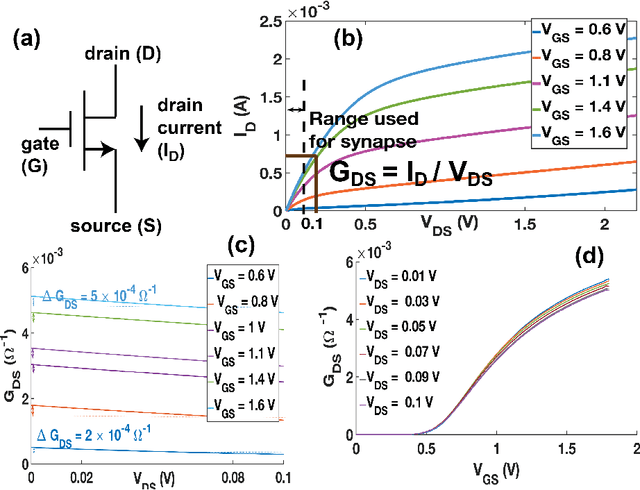
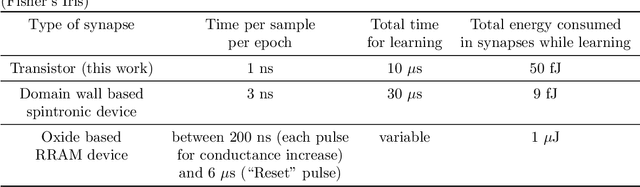
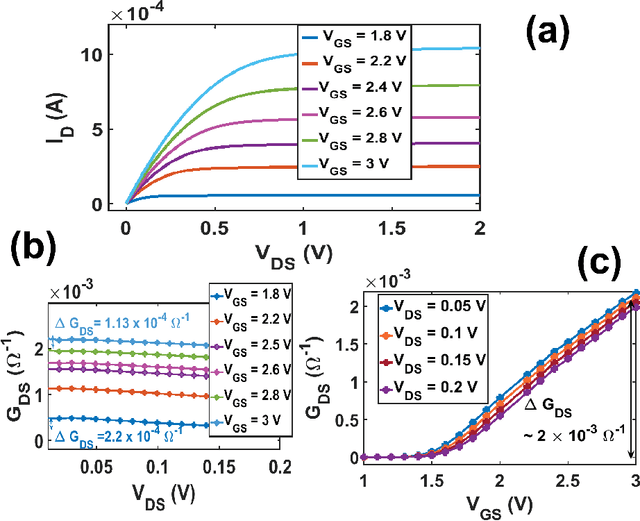
On-chip learning in a crossbar array based analog hardware Neural Network (NN) has been shown to have major advantages in terms of speed and energy compared to training NN on a traditional computer. However analog hardware NN proposals and implementations thus far have mostly involved Non Volatile Memory (NVM) devices like Resistive Random Access Memory (RRAM), Phase Change Memory (PCM), spintronic devices or floating gate transistors as synapses. Fabricating systems based on RRAM, PCM or spintronic devices need in-house laboratory facilities and cannot be done through merchant foundries, unlike conventional silicon based CMOS chips. Floating gate transistors need large voltage pulses for weight update, making on-chip learning in such systems energy inefficient. This paper proposes and implements through SPICE simulations on-chip learning in analog hardware NN using only conventional silicon based MOSFETs (without any floating gate) as synapses since they are easy to fabricate. We first model the synaptic characteristic of our single transistor synapse using SPICE circuit simulator and benchmark it against experimentally obtained current-voltage characteristics of a transistor. Next we design a Fully Connected Neural Network (FCNN) crossbar array using such transistor synapses. We also design analog peripheral circuits for neuron and synaptic weight update calculation, needed for on-chip learning, again using conventional transistors. Simulating the entire system on SPICE simulator, we obtain high training and test accuracy on the standard Fisher's Iris dataset, widely used in machine learning. We also compare the speed and energy performance of our transistor based implementation of analog hardware NN with some previous implementations of NN with NVM devices and show comparable performance with respect to on-chip learning.
On-chip learning for domain wall synapse based Fully Connected Neural Network
Nov 25, 2018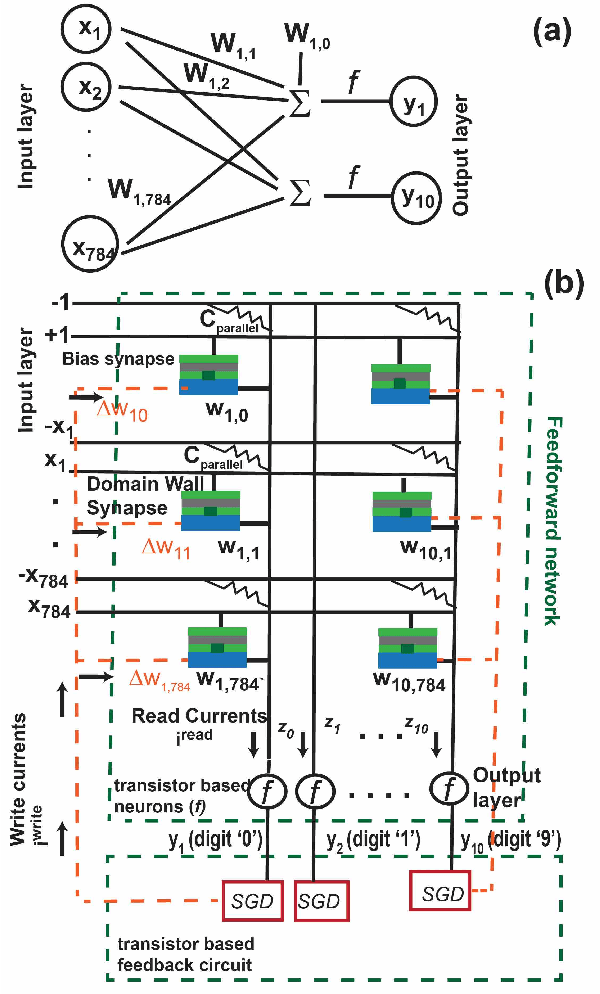
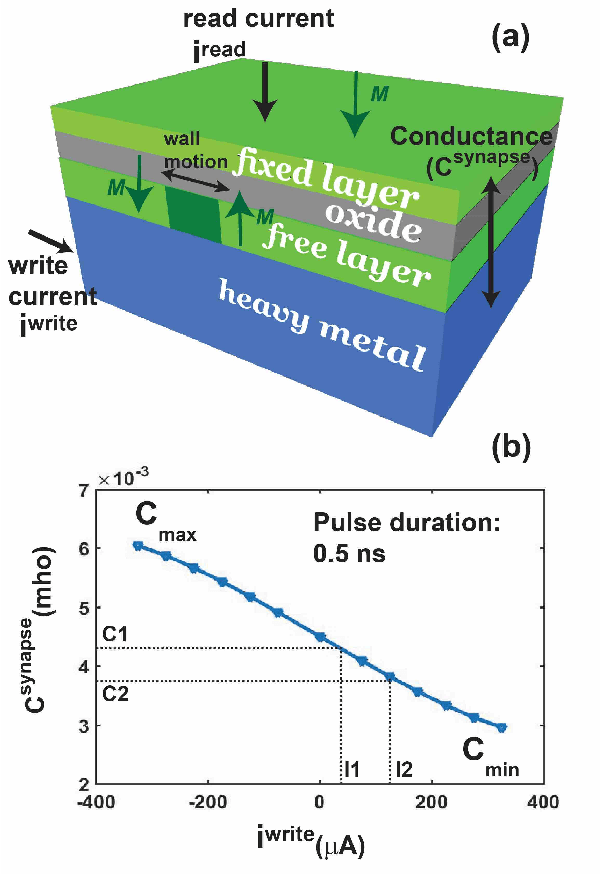
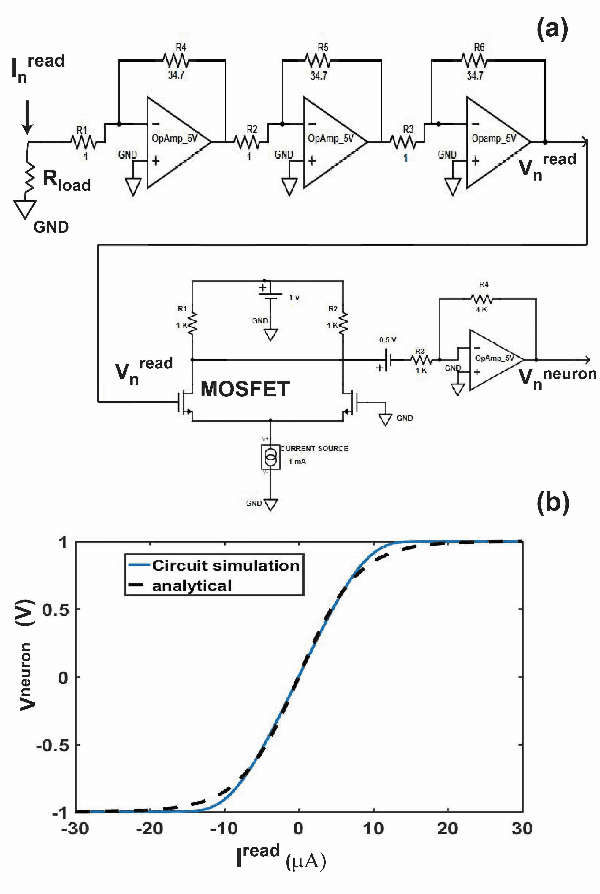
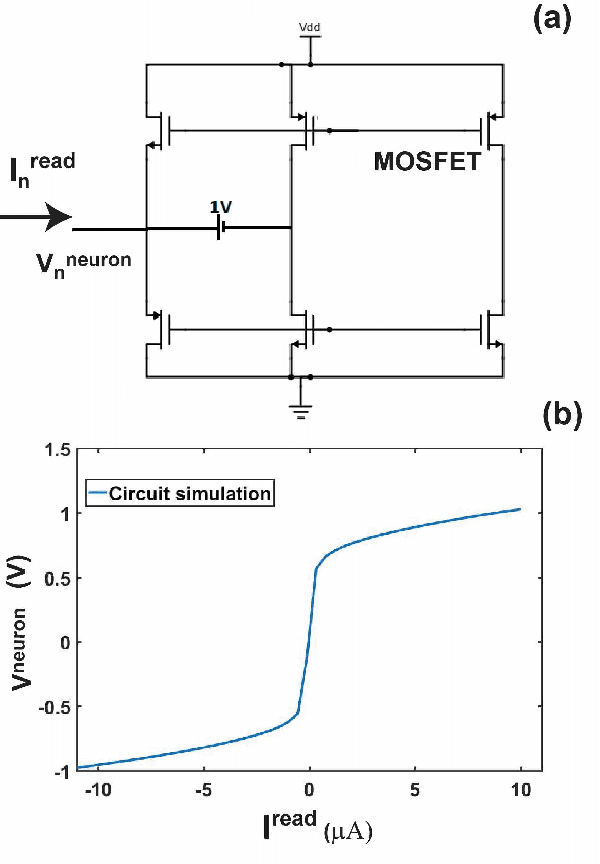
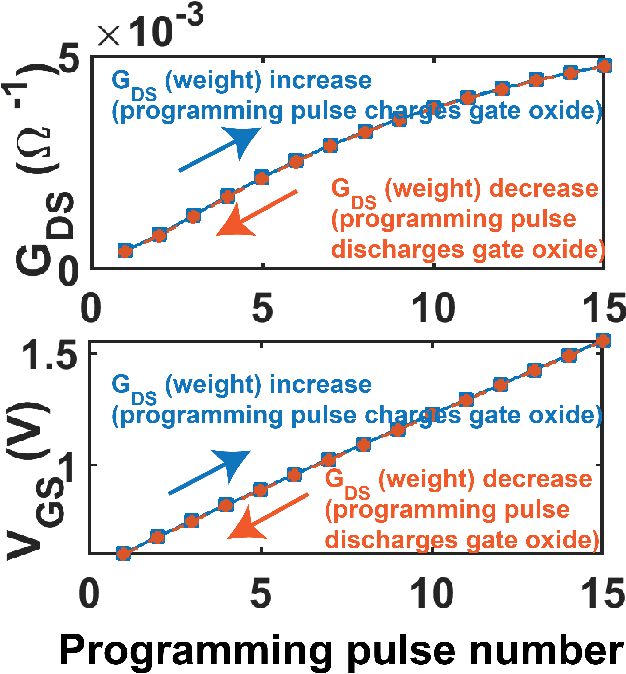
Spintronic devices are considered as promising candidates in implementing neuromorphic systems or hardware neural networks, which are expected to perform better than other existing computing systems for certain data classification and regression tasks. In this paper, we have designed a feedforward Fully Connected Neural Network (FCNN) with no hidden layer using spin orbit torque driven domain wall devices as synapses and transistor based analog circuits as neurons. A feedback circuit is also designed using transistors, which at every iteration computes the change in weights of the synapses needed to train the network using Stochastic Gradient Descent (SGD) method. Subsequently it sends write current pulses to the domain wall based synaptic devices which move the domain walls and updates the weights of the synapses. Through a combination of micromagnetic simulations, analog circuit simulations and numerically solving FCNN training equations, we demonstrate "on-chip" training of the designed FCNN on the MNIST database of handwritten digits in this paper. We report the training and test accuracies, energy consumed in the synaptic devices for the training and possible issues with hardware implementation of FCNN that can limit its test accuracy.