 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing domain wall synapse with other Non Volatile Memory devices for on-chip learning in Analog Hardware Neural Network
Oct 28, 2019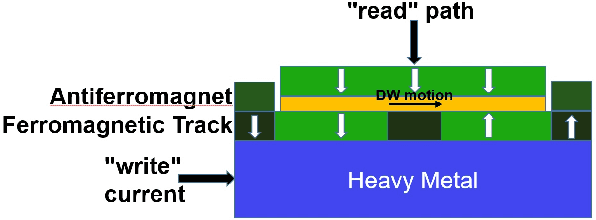

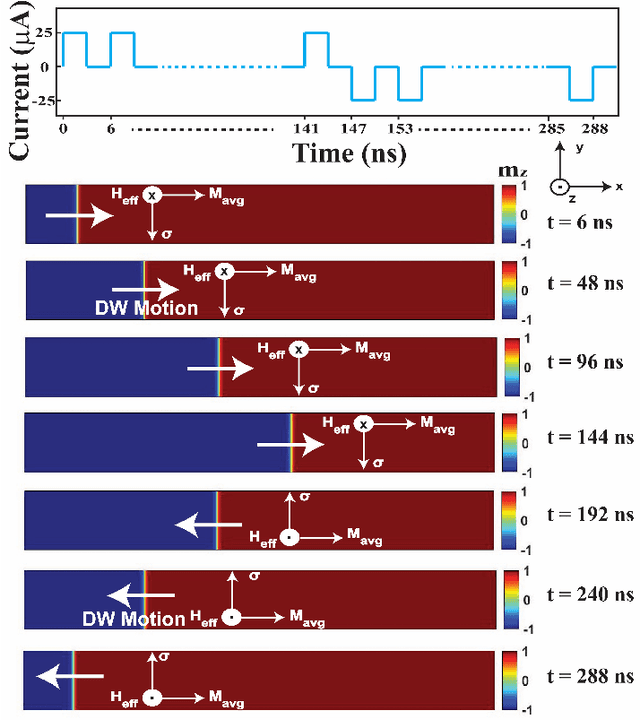
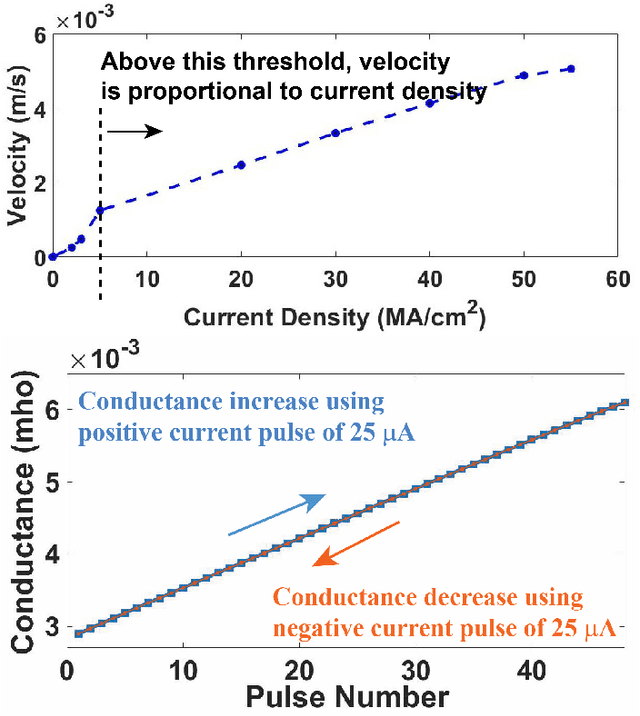
Resistive Random Access Memory (RRAM) and Phase Change Memory (PCM) devices have been popularly used as synapses in crossbar array based analog Neural Network (NN) circuit to achieve more energy and time efficient data classification compared to conventional computers. Here we demonstrate the advantages of recently proposed spin orbit torque driven Domain Wall (DW) device as synapse compared to the RRAM and PCM devices with respect to on-chip learning (training in hardware) in such NN. Synaptic characteristic of DW synapse, obtained by us from micromagnetic modeling, turns out to be much more linear and symmetric (between positive and negative update) than that of RRAM and PCM synapse. This makes design of peripheral analog circuits for on-chip learning much easier in DW synapse based NN compared to that for RRAM and PCM synapses. We next incorporate the DW synapse as a Verilog-A model in the crossbar array based NN circuit we design on SPICE circuit simulator. Successful on-chip learning is demonstrated through SPICE simulations on the popular Fisher's Iris dataset. Time and energy required for learning turn out to be orders of magnitude lower for DW synapse based NN circuit compared to that for RRAM and PCM synapse based NN circuits.
On-chip learning in a conventional silicon MOSFET based Analog Hardware Neural Network
Jul 01, 2019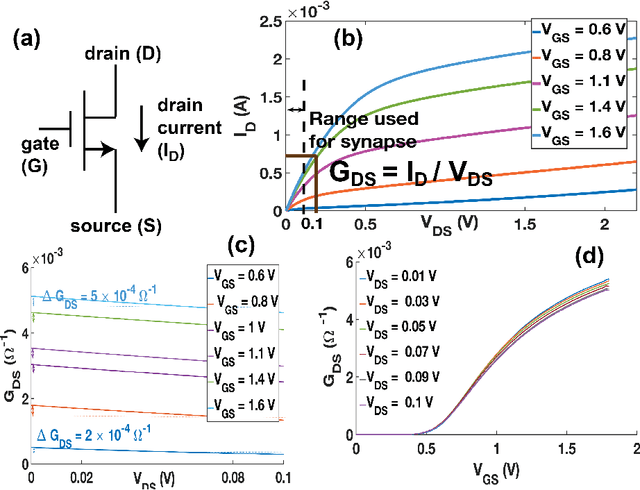
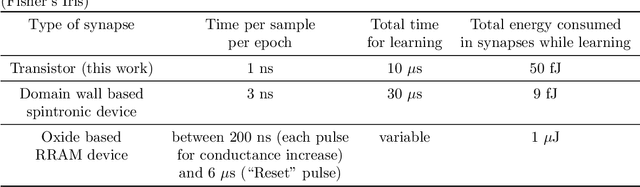
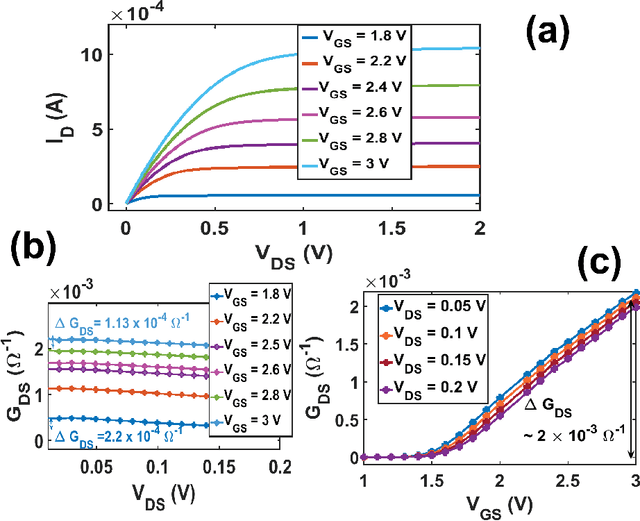
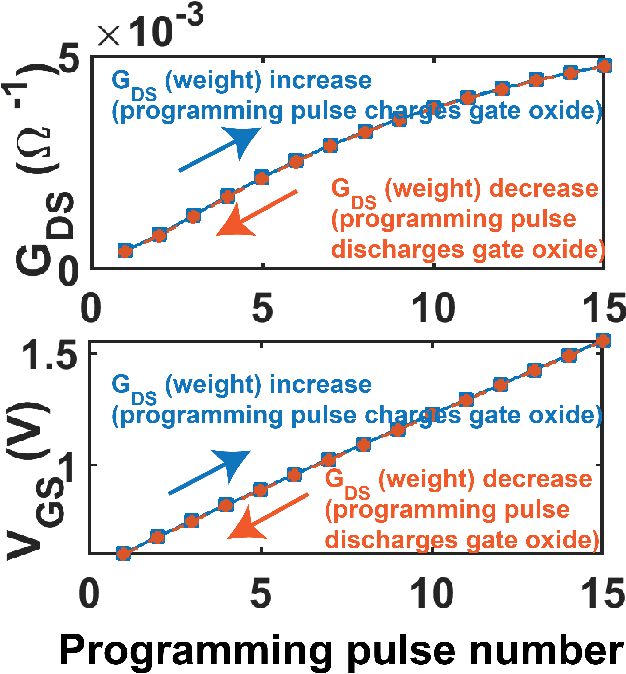
On-chip learning in a crossbar array based analog hardware Neural Network (NN) has been shown to have major advantages in terms of speed and energy compared to training NN on a traditional computer. However analog hardware NN proposals and implementations thus far have mostly involved Non Volatile Memory (NVM) devices like Resistive Random Access Memory (RRAM), Phase Change Memory (PCM), spintronic devices or floating gate transistors as synapses. Fabricating systems based on RRAM, PCM or spintronic devices need in-house laboratory facilities and cannot be done through merchant foundries, unlike conventional silicon based CMOS chips. Floating gate transistors need large voltage pulses for weight update, making on-chip learning in such systems energy inefficient. This paper proposes and implements through SPICE simulations on-chip learning in analog hardware NN using only conventional silicon based MOSFETs (without any floating gate) as synapses since they are easy to fabricate. We first model the synaptic characteristic of our single transistor synapse using SPICE circuit simulator and benchmark it against experimentally obtained current-voltage characteristics of a transistor. Next we design a Fully Connected Neural Network (FCNN) crossbar array using such transistor synapses. We also design analog peripheral circuits for neuron and synaptic weight update calculation, needed for on-chip learning, again using conventional transistors. Simulating the entire system on SPICE simulator, we obtain high training and test accuracy on the standard Fisher's Iris dataset, widely used in machine learning. We also compare the speed and energy performance of our transistor based implementation of analog hardware NN with some previous implementations of NN with NVM devices and show comparable performance with respect to on-chip learning.
On-chip learning for domain wall synapse based Fully Connected Neural Network
Nov 25, 2018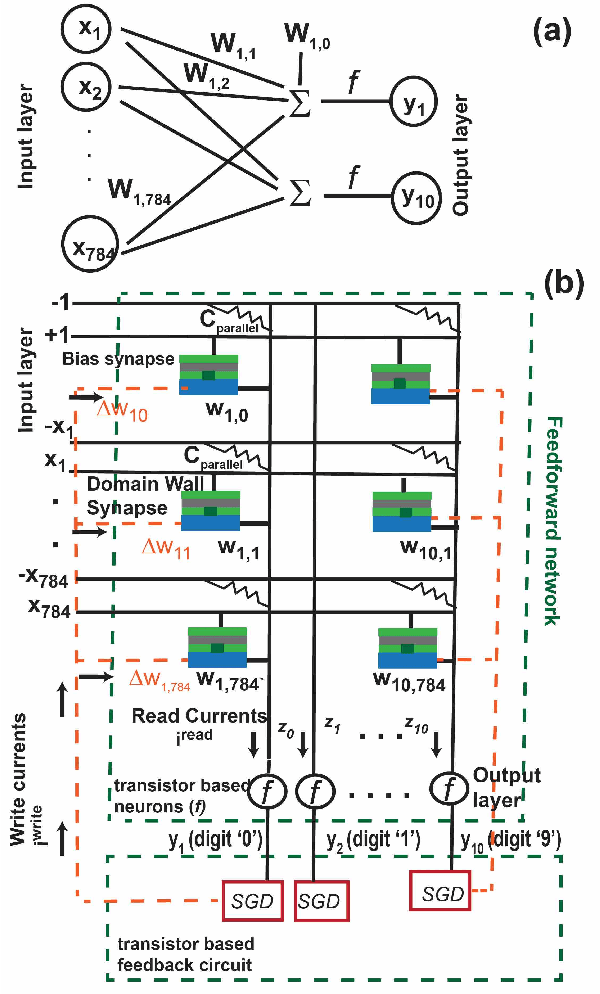
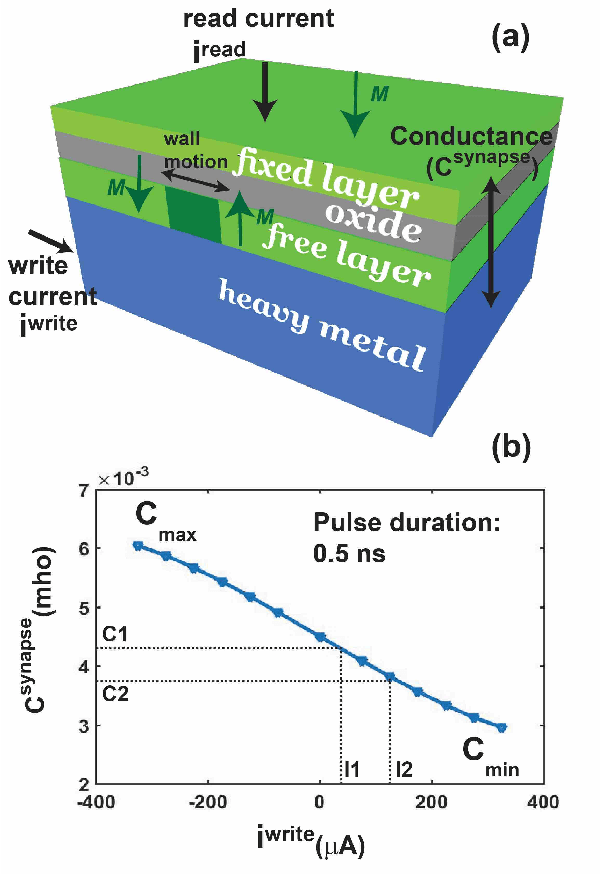
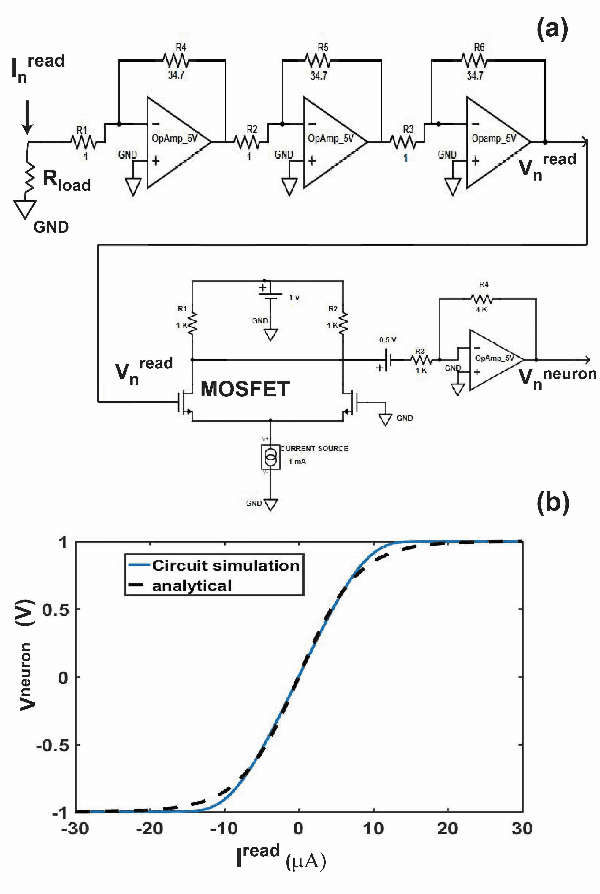
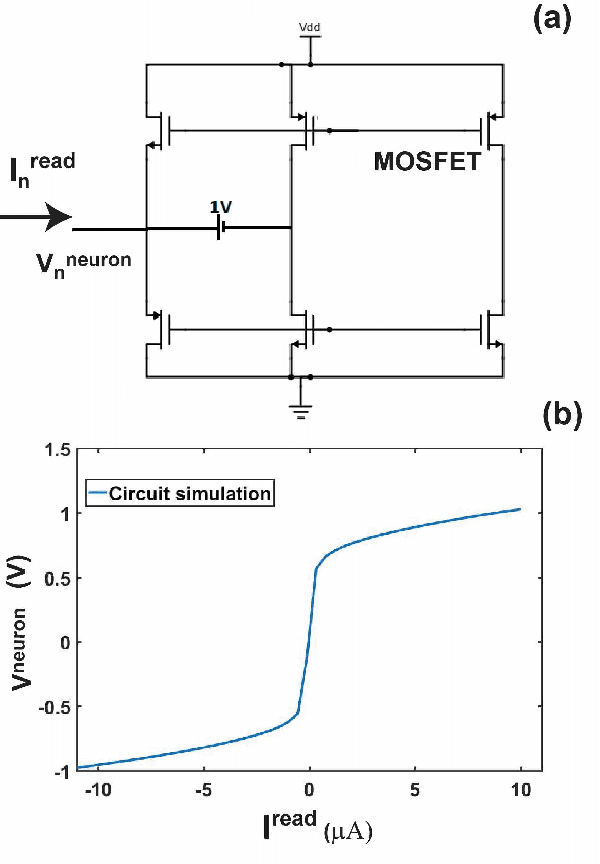
Spintronic devices are considered as promising candidates in implementing neuromorphic systems or hardware neural networks, which are expected to perform better than other existing computing systems for certain data classification and regression tasks. In this paper, we have designed a feedforward Fully Connected Neural Network (FCNN) with no hidden layer using spin orbit torque driven domain wall devices as synapses and transistor based analog circuits as neurons. A feedback circuit is also designed using transistors, which at every iteration computes the change in weights of the synapses needed to train the network using Stochastic Gradient Descent (SGD) method. Subsequently it sends write current pulses to the domain wall based synaptic devices which move the domain walls and updates the weights of the synapses. Through a combination of micromagnetic simulations, analog circuit simulations and numerically solving FCNN training equations, we demonstrate "on-chip" training of the designed FCNN on the MNIST database of handwritten digits in this paper. We report the training and test accuracies, energy consumed in the synaptic devices for the training and possible issues with hardware implementation of FCNN that can limit its test accuracy.