 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabPFGen -- Tabular Data Generation with TabPFN
Jun 07, 2024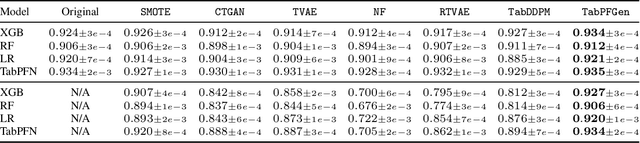
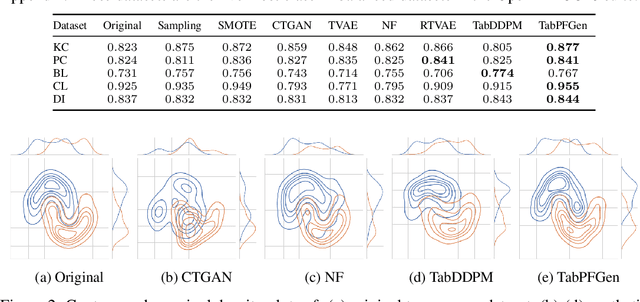
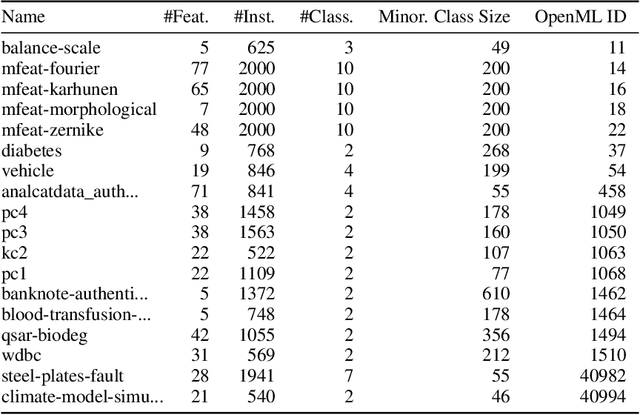
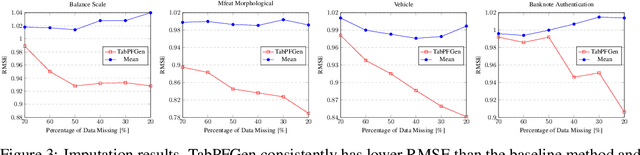
Advances in deep generative modelling have not translated well to tabular data. We argue that this is caused by a mismatch in structure between popular generative models and discriminative models of tabular data. We thus devise a technique to turn TabPFN -- a highly performant transformer initially designed for in-context discriminative tabular tasks -- into an energy-based generative model, which we dub TabPFGen. This novel framework leverages the pre-trained TabPFN as part of the energy function and does not require any additional training or hyperparameter tuning, thus inheriting TabPFN's in-context learning capability. We can sample from TabPFGen analogously to other energy-based models. We demonstrate strong results on standard generative modelling tasks, including data augmentation, class-balancing, and imputation, unlocking a new frontier of tabular data generation.
Improving Knowledge Distillation for BERT Models: Loss Functions, Mapping Methods, and Weight Tuning
Aug 26, 2023The use of large transformer-based models such as BERT, GPT, and T5 has led to significant advancements in natural language processing. However, these models are computationally expensive, necessitating model compression techniques that reduce their size and complexity while maintaining accuracy. This project investigates and applies knowledge distillation for BERT model compression, specifically focusing on the TinyBERT student model. We explore various techniques to improve knowledge distillation, including experimentation with loss functions, transformer layer mapping methods, and tuning the weights of attention and representation loss and evaluate our proposed techniques on a selection of downstream tasks from the GLUE benchmark. The goal of this work is to improve the efficiency and effectiveness of knowledge distillation, enabling the development of more efficient and accurate models for a range of natural language processing tasks.
On-chip learning for domain wall synapse based Fully Connected Neural Network
Nov 25, 2018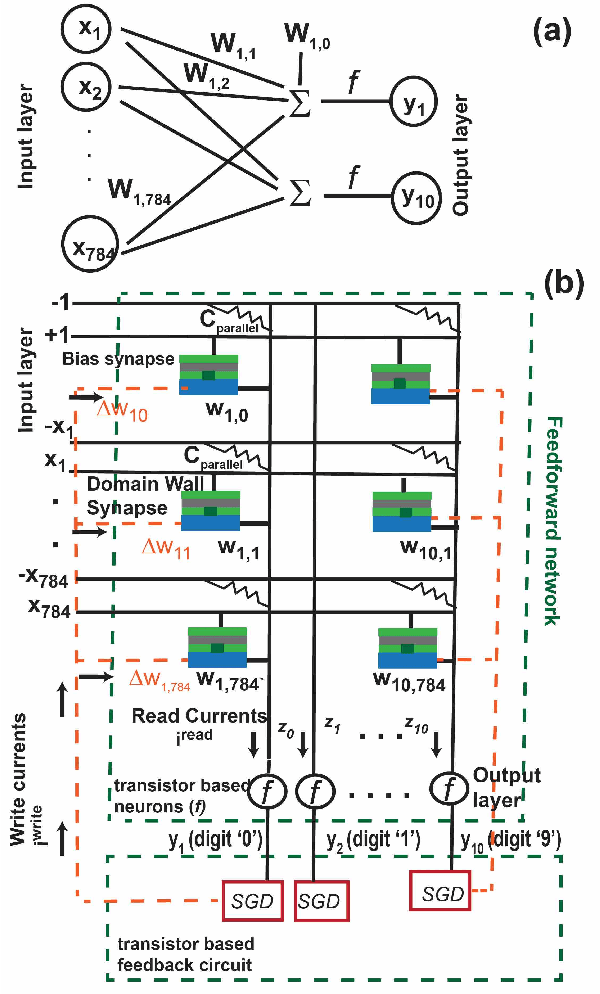
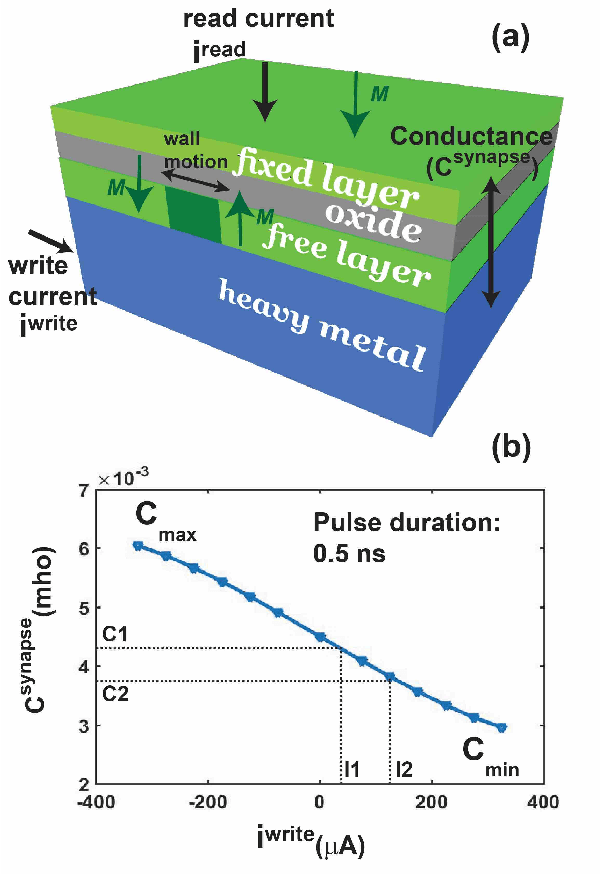
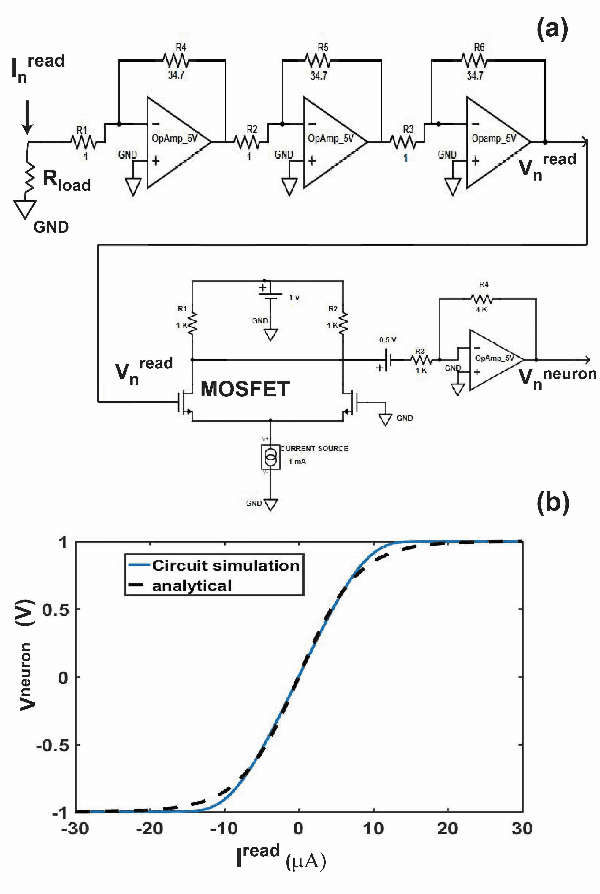
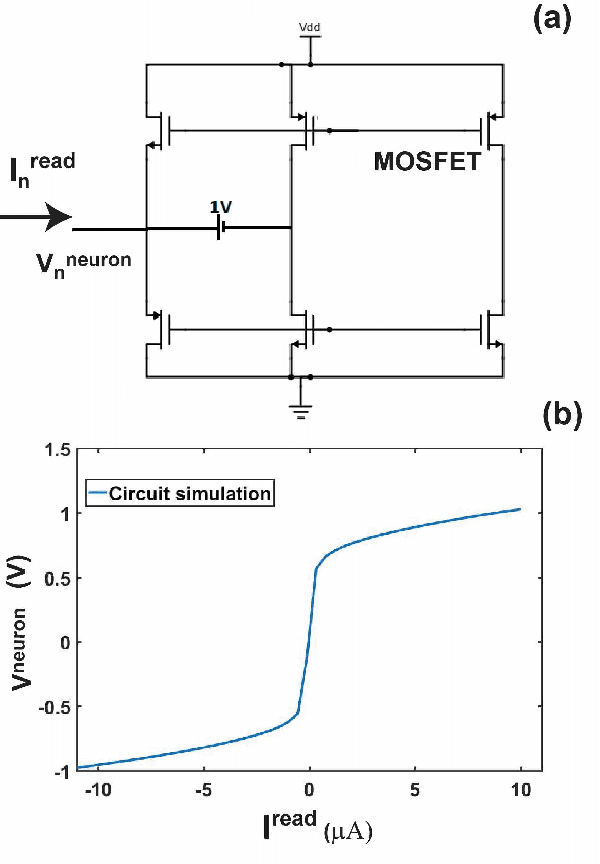
Spintronic devices are considered as promising candidates in implementing neuromorphic systems or hardware neural networks, which are expected to perform better than other existing computing systems for certain data classification and regression tasks. In this paper, we have designed a feedforward Fully Connected Neural Network (FCNN) with no hidden layer using spin orbit torque driven domain wall devices as synapses and transistor based analog circuits as neurons. A feedback circuit is also designed using transistors, which at every iteration computes the change in weights of the synapses needed to train the network using Stochastic Gradient Descent (SGD) method. Subsequently it sends write current pulses to the domain wall based synaptic devices which move the domain walls and updates the weights of the synapses. Through a combination of micromagnetic simulations, analog circuit simulations and numerically solving FCNN training equations, we demonstrate "on-chip" training of the designed FCNN on the MNIST database of handwritten digits in this paper. We report the training and test accuracies, energy consumed in the synaptic devices for the training and possible issues with hardware implementation of FCNN that can limit its test accuracy.