 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDamage-TriageFormer: A Foundation-Model Framework for Typology-Based Building Damage Assessment from Mono-Temporal Imagery
Jun 10, 2026Decision-relevant building damage assessment is critical for prioritizing resources and recovery after a disaster, yet most automated methods either flatten damage into a single severity scale (no damage, minor, major, destroyed) or require paired pre- and post-event imagery that is often unavailable for emerging hazards. This paper presents Damage-TriageFormer, a single-image, post-event, footprint-conditioned model that produces a damage typology rather than a severity scale. We contribute: (1) DamageTriage-Bench, a new benchmark built from NOAA Emergency Response Imagery across Hurricane Michael (2018), Hurricane Helene (2024), and the 2025 Los Angeles wildfire complex, with five typology classes that distinguish roof damage from structural damage and, within each, partial from total extent; and (2) Damage-TriageFormer, which extends a DINOv3 ViT-L backbone with a Simple Feature Pyramid for higher-resolution instance pooling, a two-stage gated damage head, and an auxiliary severity-regression objective. Our model achieves macro F1 of 0.624 on validation and 0.619 on a held-out stratified test set, performing strongest where operational triage needs it most, with per-class F1 of 0.91 and 0.84 on undamaged buildings and total structural collapse, respectively. While the rare Total Roof Damage class remains difficult due to its limited examples and an inherently ambiguous label boundary, our results show that single-image post-event imagery can support actionable building damage typing, enabling targeted emergency response and resource allocation without a pre-event reference.
Data-efficient flood depth prediction through domain-aware coreset selection and tabular foundation models
Jun 03, 2026Near-real-time flood depth prediction demands surrogate models that are accurate, fast, and transferable across watersheds. Supervised surrogates can match physics-based simulators in accuracy but need millions of training rows per watershed and cannot extrapolate beyond their original mesh. We propose a domain-aware coreset construction pipeline that conditions a tabular foundation model at inference time. The pipeline stratifies storms by return period and most-affected watershed, then samples hexagons with a target-aware spatial selector. With 0.7% of the per-watershed training pool, the model attains a mean $R^2$ of 0.663 across nine Houston-area watersheds, within 98.5% of the supervised reference ($R^2$ = 0.673). It transfers to held-out watersheds without task-specific retraining, staying ahead of a coreset-trained supervised baseline. On real storms it exceeds the supervised reference on a far out-of-distribution case and trails it on a mostly in-distribution one. Domain-aware coreset construction lets tabular foundation models deliver data-efficient, watershed-transferable flood predictions without per-watershed training.
DisastQA: A Comprehensive Benchmark for Evaluating Question Answering in Disaster Management
Jan 07, 2026Accurate question answering (QA) in disaster management requires reasoning over uncertain and conflicting information, a setting poorly captured by existing benchmarks built on clean evidence. We introduce DisastQA, a large-scale benchmark of 3,000 rigorously verified questions (2,000 multiple-choice and 1,000 open-ended) spanning eight disaster types. The benchmark is constructed via a human-LLM collaboration pipeline with stratified sampling to ensure balanced coverage. Models are evaluated under varying evidence conditions, from closed-book to noisy evidence integration, enabling separation of internal knowledge from reasoning under imperfect information. For open-ended QA, we propose a human-verified keypoint-based evaluation protocol emphasizing factual completeness over verbosity. Experiments with 20 models reveal substantial divergences from general-purpose leaderboards such as MMLU-Pro. While recent open-weight models approach proprietary systems in clean settings, performance degrades sharply under realistic noise, exposing critical reliability gaps for disaster response. All code, data, and evaluation resources are available at https://github.com/TamuChen18/DisastQA_open.
Generalization Can Emerge in Tabular Foundation Models From a Single Table
Nov 12, 2025



Deep tabular modelling increasingly relies on in-context learning where, during inference, a model receives a set of $(x,y)$ pairs as context and predicts labels for new inputs without weight updates. We challenge the prevailing view that broad generalization here requires pre-training on large synthetic corpora (e.g., TabPFN priors) or a large collection of real data (e.g., TabDPT training datasets), discovering that a relatively small amount of data suffices for generalization. We find that simple self-supervised pre-training on just a \emph{single} real table can produce surprisingly strong transfer across heterogeneous benchmarks. By systematically pre-training and evaluating on many diverse datasets, we analyze what aspects of the data are most important for building a Tabular Foundation Model (TFM) generalizing across domains. We then connect this to the pre-training procedure shared by most TFMs and show that the number and quality of \emph{tasks} one can construct from a dataset is key to downstream performance.
CausalPFN: Amortized Causal Effect Estimation via In-Context Learning
Jun 09, 2025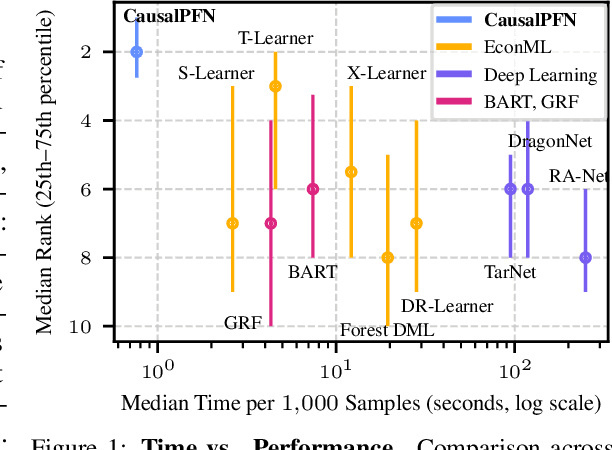
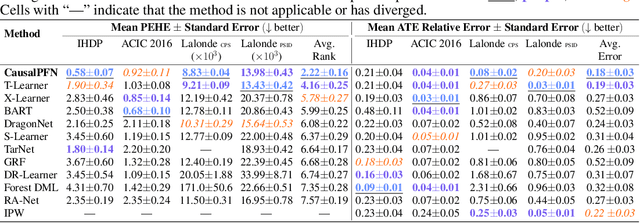
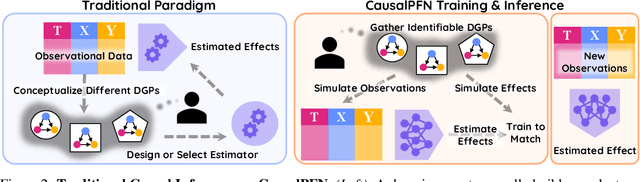
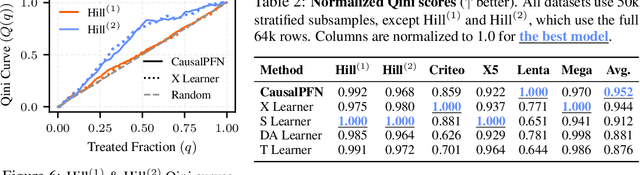
Causal effect estimation from observational data is fundamental across various applications. However, selecting an appropriate estimator from dozens of specialized methods demands substantial manual effort and domain expertise. We present CausalPFN, a single transformer that amortizes this workflow: trained once on a large library of simulated data-generating processes that satisfy ignorability, it infers causal effects for new observational datasets out-of-the-box. CausalPFN combines ideas from Bayesian causal inference with the large-scale training protocol of prior-fitted networks (PFNs), learning to map raw observations directly to causal effects without any task-specific adjustment. Our approach achieves superior average performance on heterogeneous and average treatment effect estimation benchmarks (IHDP, Lalonde, ACIC). Moreover, it shows competitive performance for real-world policy making on uplift modeling tasks. CausalPFN provides calibrated uncertainty estimates to support reliable decision-making based on Bayesian principles. This ready-to-use model does not require any further training or tuning and takes a step toward automated causal inference (https://github.com/vdblm/CausalPFN).
TabDPT: Scaling Tabular Foundation Models
Oct 23, 2024



The challenges faced by neural networks on tabular data are well-documented and have hampered the progress of tabular foundation models. Techniques leveraging in-context learning (ICL) have shown promise here, allowing for dynamic adaptation to unseen data. ICL can provide predictions for entirely new datasets without further training or hyperparameter tuning, therefore providing very fast inference when encountering a novel task. However, scaling ICL for tabular data remains an issue: approaches based on large language models cannot efficiently process numeric tables, and tabular-specific techniques have not been able to effectively harness the power of real data to improve performance and generalization. We are able to overcome these challenges by training tabular-specific ICL-based architectures on real data with self-supervised learning and retrieval, combining the best of both worlds. Our resulting model -- the Tabular Discriminative Pre-trained Transformer (TabDPT) -- achieves state-of-the-art performance on the CC18 (classification) and CTR23 (regression) benchmarks with no task-specific fine-tuning, demonstrating the adapatability and speed of ICL once the model is pre-trained. TabDPT also demonstrates strong scaling as both model size and amount of available data increase, pointing towards future improvements simply through the curation of larger tabular pre-training datasets and training larger models.
TabPFGen -- Tabular Data Generation with TabPFN
Jun 07, 2024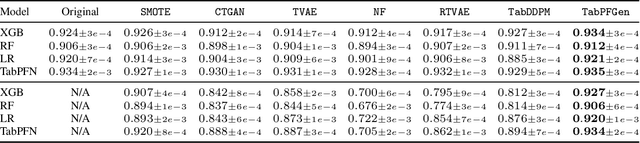
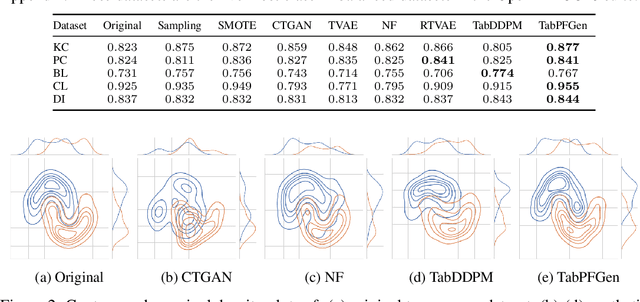
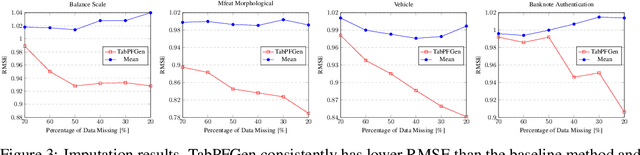
Advances in deep generative modelling have not translated well to tabular data. We argue that this is caused by a mismatch in structure between popular generative models and discriminative models of tabular data. We thus devise a technique to turn TabPFN -- a highly performant transformer initially designed for in-context discriminative tabular tasks -- into an energy-based generative model, which we dub TabPFGen. This novel framework leverages the pre-trained TabPFN as part of the energy function and does not require any additional training or hyperparameter tuning, thus inheriting TabPFN's in-context learning capability. We can sample from TabPFGen analogously to other energy-based models. We demonstrate strong results on standard generative modelling tasks, including data augmentation, class-balancing, and imputation, unlocking a new frontier of tabular data generation.
Retrieval & Fine-Tuning for In-Context Tabular Models
Jun 07, 2024Tabular data is a pervasive modality spanning a wide range of domains, and the inherent diversity poses a considerable challenge for deep learning. Recent advancements using transformer-based in-context learning have shown promise on smaller and less complex datasets, but have struggled to scale to larger and more complex ones. To address this limitation, we propose a combination of retrieval and fine-tuning: we can adapt the transformer to a local subset of the data by collecting nearest neighbours, and then perform task-specific fine-tuning with this retrieved set of neighbours in context. Using TabPFN as the base model -- currently the best tabular in-context learner -- and applying our retrieval and fine-tuning scheme on top results in what we call a locally-calibrated PFN, or LoCalPFN. We conduct extensive evaluation on 95 datasets curated by TabZilla from OpenML, upon which we establish a new state-of-the-art with LoCalPFN -- even with respect to tuned tree-based models. Notably, we show a significant boost in performance compared to the base in-context model, demonstrating the efficacy of our approach and advancing the frontier of deep learning in tabular data.
Tabular Data Contrastive Learning via Class-Conditioned and Feature-Correlation Based Augmentation
Apr 30, 2024
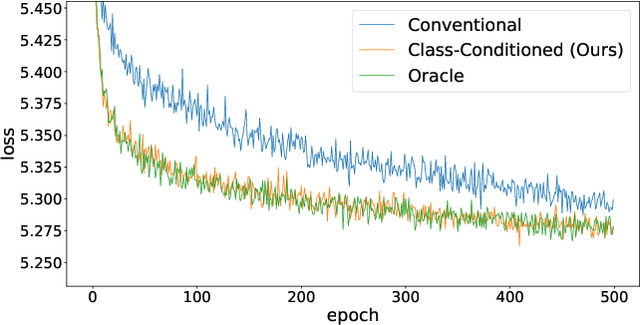


Contrastive learning is a model pre-training technique by first creating similar views of the original data, and then encouraging the data and its corresponding views to be close in the embedding space. Contrastive learning has witnessed success in image and natural language data, thanks to the domain-specific augmentation techniques that are both intuitive and effective. Nonetheless, in tabular domain, the predominant augmentation technique for creating views is through corrupting tabular entries via swapping values, which is not as sound or effective. We propose a simple yet powerful improvement to this augmentation technique: corrupting tabular data conditioned on class identity. Specifically, when corrupting a specific tabular entry from an anchor row, instead of randomly sampling a value in the same feature column from the entire table uniformly, we only sample from rows that are identified to be within the same class as the anchor row. We assume the semi-supervised learning setting, and adopt the pseudo labeling technique for obtaining class identities over all table rows. We also explore the novel idea of selecting features to be corrupted based on feature correlation structures. Extensive experiments show that the proposed approach consistently outperforms the conventional corruption method for tabular data classification tasks. Our code is available at https://github.com/willtop/Tabular-Class-Conditioned-SSL.
In-Context Data Distillation with TabPFN
Feb 10, 2024Foundation models have revolutionized tasks in computer vision and natural language processing. However, in the realm of tabular data, tree-based models like XGBoost continue to dominate. TabPFN, a transformer model tailored for tabular data, mirrors recent foundation models in its exceptional in-context learning capability, being competitive with XGBoost's performance without the need for task-specific training or hyperparameter tuning. Despite its promise, TabPFN's applicability is hindered by its data size constraint, limiting its use in real-world scenarios. To address this, we present in-context data distillation (ICD), a novel methodology that effectively eliminates these constraints by optimizing TabPFN's context. ICD efficiently enables TabPFN to handle significantly larger datasets with a fixed memory budget, improving TabPFN's quadratic memory complexity but at the cost of a linear number of tuning steps. Notably, TabPFN, enhanced with ICD, demonstrates very strong performance against established tree-based models and modern deep learning methods on 48 large tabular datasets from OpenML.