 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRESS: Disentangled Representation-based Self-Supervised Meta-Learning for Diverse Tasks
Mar 12, 2025Meta-learning represents a strong class of approaches for solving few-shot learning tasks. Nonetheless, recent research suggests that simply pre-training a generic encoder can potentially surpass meta-learning algorithms. In this paper, we first discuss the reasons why meta-learning fails to stand out in these few-shot learning experiments, and hypothesize that it is due to the few-shot learning tasks lacking diversity. We propose DRESS, a task-agnostic Disentangled REpresentation-based Self-Supervised meta-learning approach that enables fast model adaptation on highly diversified few-shot learning tasks. Specifically, DRESS utilizes disentangled representation learning to create self-supervised tasks that can fuel the meta-training process. Furthermore, we also propose a class-partition based metric for quantifying the task diversity directly on the input space. We validate the effectiveness of DRESS through experiments on datasets with multiple factors of variation and varying complexity. The results suggest that DRESS is able to outperform competing methods on the majority of the datasets and task setups. Through this paper, we advocate for a re-examination of proper setups for task adaptation studies, and aim to reignite interest in the potential of meta-learning for solving few-shot learning tasks via disentangled representations.
A Geometric Framework for Understanding Memorization in Generative Models
Oct 31, 2024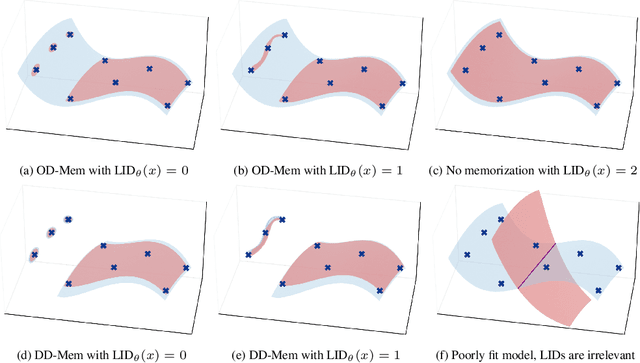

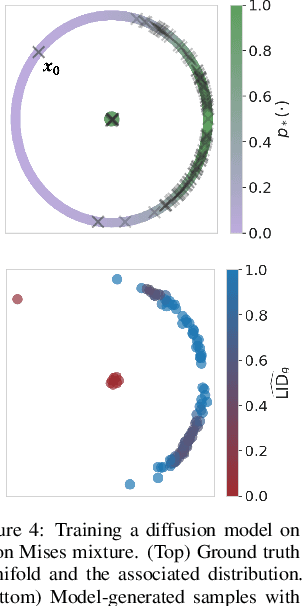
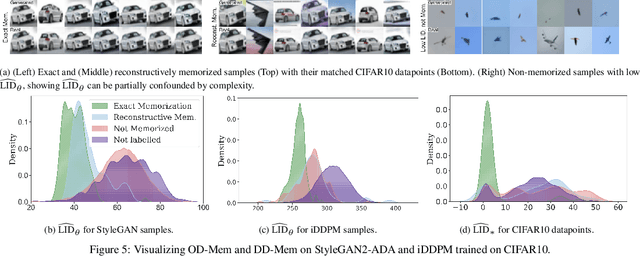
As deep generative models have progressed, recent work has shown them to be capable of memorizing and reproducing training datapoints when deployed. These findings call into question the usability of generative models, especially in light of the legal and privacy risks brought about by memorization. To better understand this phenomenon, we propose the manifold memorization hypothesis (MMH), a geometric framework which leverages the manifold hypothesis into a clear language in which to reason about memorization. We propose to analyze memorization in terms of the relationship between the dimensionalities of $(i)$ the ground truth data manifold and $(ii)$ the manifold learned by the model. This framework provides a formal standard for "how memorized" a datapoint is and systematically categorizes memorized data into two types: memorization driven by overfitting and memorization driven by the underlying data distribution. By analyzing prior work in the context of the MMH, we explain and unify assorted observations in the literature. We empirically validate the MMH using synthetic data and image datasets up to the scale of Stable Diffusion, developing new tools for detecting and preventing generation of memorized samples in the process.
Tabular Data Contrastive Learning via Class-Conditioned and Feature-Correlation Based Augmentation
Apr 30, 2024
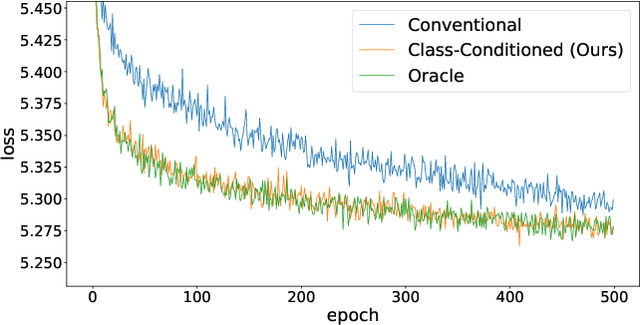


Contrastive learning is a model pre-training technique by first creating similar views of the original data, and then encouraging the data and its corresponding views to be close in the embedding space. Contrastive learning has witnessed success in image and natural language data, thanks to the domain-specific augmentation techniques that are both intuitive and effective. Nonetheless, in tabular domain, the predominant augmentation technique for creating views is through corrupting tabular entries via swapping values, which is not as sound or effective. We propose a simple yet powerful improvement to this augmentation technique: corrupting tabular data conditioned on class identity. Specifically, when corrupting a specific tabular entry from an anchor row, instead of randomly sampling a value in the same feature column from the entire table uniformly, we only sample from rows that are identified to be within the same class as the anchor row. We assume the semi-supervised learning setting, and adopt the pseudo labeling technique for obtaining class identities over all table rows. We also explore the novel idea of selecting features to be corrupted based on feature correlation structures. Extensive experiments show that the proposed approach consistently outperforms the conventional corruption method for tabular data classification tasks. Our code is available at https://github.com/willtop/Tabular-Class-Conditioned-SSL.
Self-supervised Representation Learning From Random Data Projectors
Oct 11, 2023

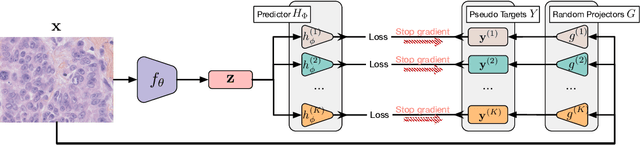
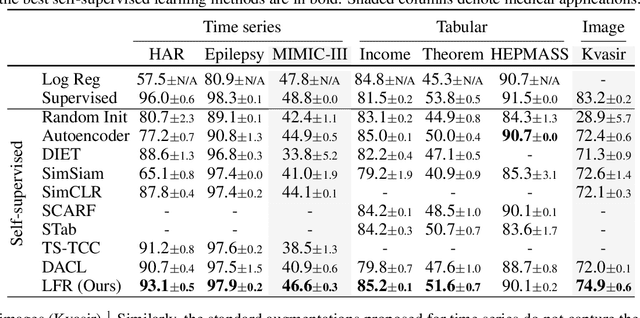
Self-supervised representation learning~(SSRL) has advanced considerably by exploiting the transformation invariance assumption under artificially designed data augmentations. While augmentation-based SSRL algorithms push the boundaries of performance in computer vision and natural language processing, they are often not directly applicable to other data modalities, and can conflict with application-specific data augmentation constraints. This paper presents an SSRL approach that can be applied to any data modality and network architecture because it does not rely on augmentations or masking. Specifically, we show that high-quality data representations can be learned by reconstructing random data projections. We evaluate the proposed approach on a wide range of representation learning tasks that span diverse modalities and real-world applications. We show that it outperforms multiple state-of-the-art SSRL baselines. Due to its wide applicability and strong empirical results, we argue that learning from randomness is a fruitful research direction worthy of attention and further study.
HiCu: Leveraging Hierarchy for Curriculum Learning in Automated ICD Coding
Aug 03, 2022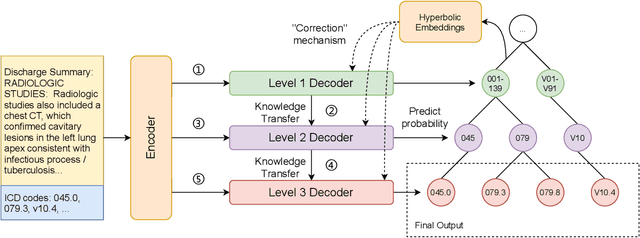
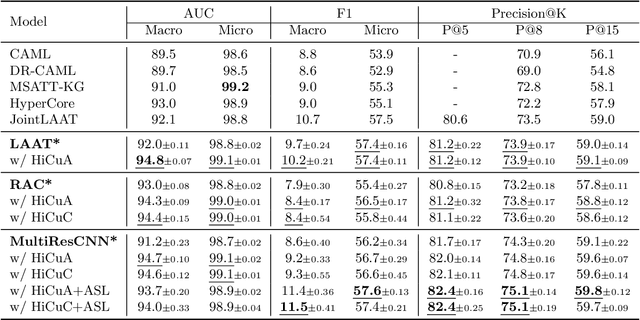
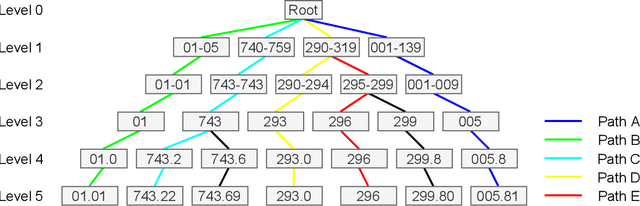
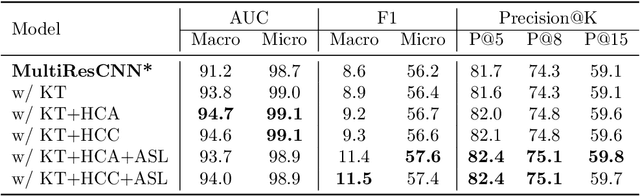
There are several opportunities for automation in healthcare that can improve clinician throughput. One such example is assistive tools to document diagnosis codes when clinicians write notes. We study the automation of medical code prediction using curriculum learning, which is a training strategy for machine learning models that gradually increases the hardness of the learning tasks from easy to difficult. One of the challenges in curriculum learning is the design of curricula -- i.e., in the sequential design of tasks that gradually increase in difficulty. We propose Hierarchical Curriculum Learning (HiCu), an algorithm that uses graph structure in the space of outputs to design curricula for multi-label classification. We create curricula for multi-label classification models that predict ICD diagnosis and procedure codes from natural language descriptions of patients. By leveraging the hierarchy of ICD codes, which groups diagnosis codes based on various organ systems in the human body, we find that our proposed curricula improve the generalization of neural network-based predictive models across recurrent, convolutional, and transformer-based architectures. Our code is available at https://github.com/wren93/HiCu-ICD.