 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Convolutions, Intrinsic Dimension, and Diffusion Models
Jun 25, 2025The manifold hypothesis asserts that data of interest in high-dimensional ambient spaces, such as image data, lies on unknown low-dimensional submanifolds. Diffusion models (DMs) -- which operate by convolving data with progressively larger amounts of Gaussian noise and then learning to revert this process -- have risen to prominence as the most performant generative models, and are known to be able to learn distributions with low-dimensional support. For a given datum in one of these submanifolds, we should thus intuitively expect DMs to have implicitly learned its corresponding local intrinsic dimension (LID), i.e. the dimension of the submanifold it belongs to. Kamkari et al. (2024b) recently showed that this is indeed the case by linking this LID to the rate of change of the log marginal densities of the DM with respect to the amount of added noise, resulting in an LID estimator known as FLIPD. LID estimators such as FLIPD have a plethora of uses, among others they quantify the complexity of a given datum, and can be used to detect outliers, adversarial examples and AI-generated text. FLIPD achieves state-of-the-art performance at LID estimation, yet its theoretical underpinnings are incomplete since Kamkari et al. (2024b) only proved its correctness under the highly unrealistic assumption of affine submanifolds. In this work we bridge this gap by formally proving the correctness of FLIPD under realistic assumptions. Additionally, we show that an analogous result holds when Gaussian convolutions are replaced with uniform ones, and discuss the relevance of this result.
Textual Bayes: Quantifying Uncertainty in LLM-Based Systems
Jun 11, 2025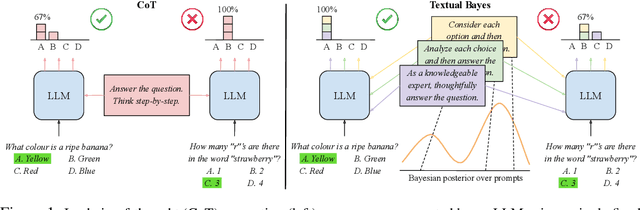
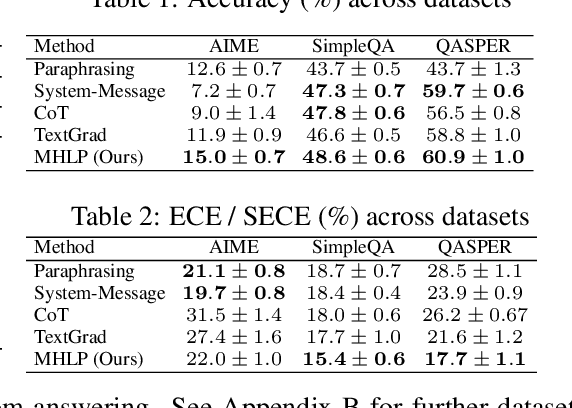
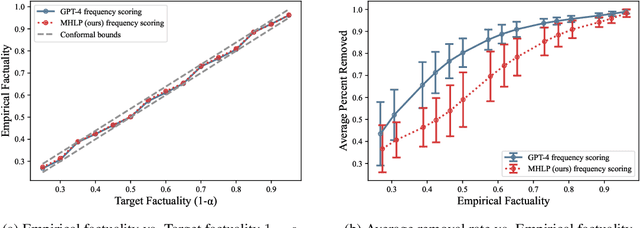
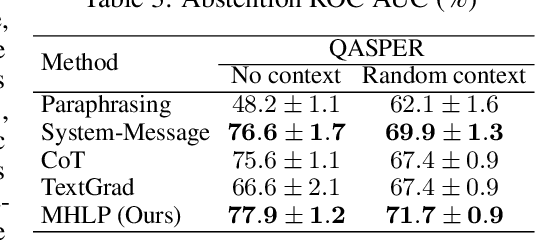
Although large language models (LLMs) are becoming increasingly capable of solving challenging real-world tasks, accurately quantifying their uncertainty remains a critical open problem, which limits their applicability in high-stakes domains. This challenge is further compounded by the closed-source, black-box nature of many state-of-the-art LLMs. Moreover, LLM-based systems can be highly sensitive to the prompts that bind them together, which often require significant manual tuning (i.e., prompt engineering). In this work, we address these challenges by viewing LLM-based systems through a Bayesian lens. We interpret prompts as textual parameters in a statistical model, allowing us to use a small training dataset to perform Bayesian inference over these prompts. This novel perspective enables principled uncertainty quantification over both the model's textual parameters and its downstream predictions, while also incorporating prior beliefs about these parameters expressed in free-form text. To perform Bayesian inference, a difficult problem even for well-studied data modalities, we introduce Metropolis-Hastings through LLM Proposals (MHLP), a novel Markov chain Monte Carlo (MCMC) algorithm that combines prompt optimization techniques with standard MCMC methods. MHLP is a turnkey modification to existing LLM pipelines, including those that rely exclusively on closed-source models. Empirically, we demonstrate that our method yields improvements in both predictive accuracy and uncertainty quantification (UQ) on a range of LLM benchmarks and UQ tasks. More broadly, our work demonstrates a viable path for incorporating methods from the rich Bayesian literature into the era of LLMs, paving the way for more reliable and calibrated LLM-based systems.
Inconsistencies In Consistency Models: Better ODE Solving Does Not Imply Better Samples
Nov 13, 2024



Although diffusion models can generate remarkably high-quality samples, they are intrinsically bottlenecked by their expensive iterative sampling procedure. Consistency models (CMs) have recently emerged as a promising diffusion model distillation method, reducing the cost of sampling by generating high-fidelity samples in just a few iterations. Consistency model distillation aims to solve the probability flow ordinary differential equation (ODE) defined by an existing diffusion model. CMs are not directly trained to minimize error against an ODE solver, rather they use a more computationally tractable objective. As a way to study how effectively CMs solve the probability flow ODE, and the effect that any induced error has on the quality of generated samples, we introduce Direct CMs, which \textit{directly} minimize this error. Intriguingly, we find that Direct CMs reduce the ODE solving error compared to CMs but also result in significantly worse sample quality, calling into question why exactly CMs work well in the first place. Full code is available at: https://github.com/layer6ai-labs/direct-cms.
A Geometric Framework for Understanding Memorization in Generative Models
Oct 31, 2024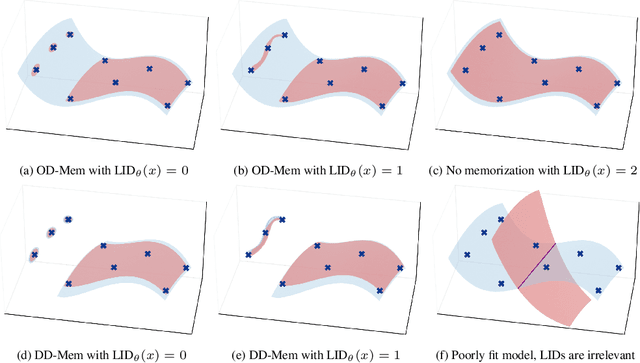

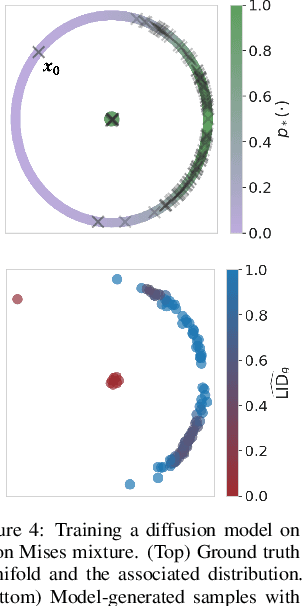
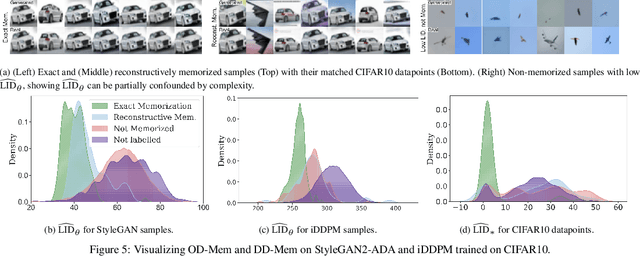
As deep generative models have progressed, recent work has shown them to be capable of memorizing and reproducing training datapoints when deployed. These findings call into question the usability of generative models, especially in light of the legal and privacy risks brought about by memorization. To better understand this phenomenon, we propose the manifold memorization hypothesis (MMH), a geometric framework which leverages the manifold hypothesis into a clear language in which to reason about memorization. We propose to analyze memorization in terms of the relationship between the dimensionalities of $(i)$ the ground truth data manifold and $(ii)$ the manifold learned by the model. This framework provides a formal standard for "how memorized" a datapoint is and systematically categorizes memorized data into two types: memorization driven by overfitting and memorization driven by the underlying data distribution. By analyzing prior work in the context of the MMH, we explain and unify assorted observations in the literature. We empirically validate the MMH using synthetic data and image datasets up to the scale of Stable Diffusion, developing new tools for detecting and preventing generation of memorized samples in the process.
TabDPT: Scaling Tabular Foundation Models
Oct 23, 2024



The challenges faced by neural networks on tabular data are well-documented and have hampered the progress of tabular foundation models. Techniques leveraging in-context learning (ICL) have shown promise here, allowing for dynamic adaptation to unseen data. ICL can provide predictions for entirely new datasets without further training or hyperparameter tuning, therefore providing very fast inference when encountering a novel task. However, scaling ICL for tabular data remains an issue: approaches based on large language models cannot efficiently process numeric tables, and tabular-specific techniques have not been able to effectively harness the power of real data to improve performance and generalization. We are able to overcome these challenges by training tabular-specific ICL-based architectures on real data with self-supervised learning and retrieval, combining the best of both worlds. Our resulting model -- the Tabular Discriminative Pre-trained Transformer (TabDPT) -- achieves state-of-the-art performance on the CC18 (classification) and CTR23 (regression) benchmarks with no task-specific fine-tuning, demonstrating the adapatability and speed of ICL once the model is pre-trained. TabDPT also demonstrates strong scaling as both model size and amount of available data increase, pointing towards future improvements simply through the curation of larger tabular pre-training datasets and training larger models.
MSc-SQL: Multi-Sample Critiquing Small Language Models For Text-To-SQL Translation
Oct 16, 2024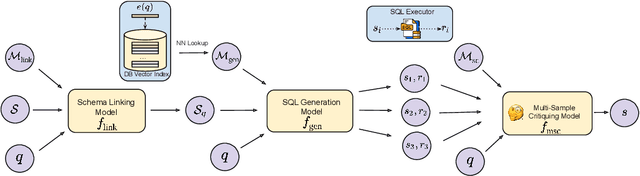
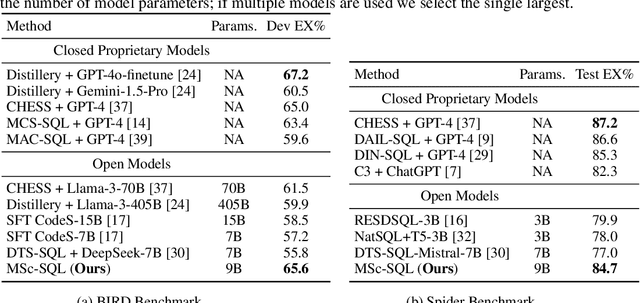


Text-to-SQL generation enables non-experts to interact with databases via natural language. Recent advances rely on large closed-source models like GPT-4 that present challenges in accessibility, privacy, and latency. To address these issues, we focus on developing small, efficient, and open-source text-to-SQL models. We demonstrate the benefits of sampling multiple candidate SQL generations and propose our method, MSc-SQL, to critique them using associated metadata. Our sample critiquing model evaluates multiple outputs simultaneously, achieving state-of-the-art performance compared to other open-source models while remaining competitive with larger models at a much lower cost. Full code can be found at github.com/layer6ai-labs/msc-sql.
Retrieval & Fine-Tuning for In-Context Tabular Models
Jun 07, 2024Tabular data is a pervasive modality spanning a wide range of domains, and the inherent diversity poses a considerable challenge for deep learning. Recent advancements using transformer-based in-context learning have shown promise on smaller and less complex datasets, but have struggled to scale to larger and more complex ones. To address this limitation, we propose a combination of retrieval and fine-tuning: we can adapt the transformer to a local subset of the data by collecting nearest neighbours, and then perform task-specific fine-tuning with this retrieved set of neighbours in context. Using TabPFN as the base model -- currently the best tabular in-context learner -- and applying our retrieval and fine-tuning scheme on top results in what we call a locally-calibrated PFN, or LoCalPFN. We conduct extensive evaluation on 95 datasets curated by TabZilla from OpenML, upon which we establish a new state-of-the-art with LoCalPFN -- even with respect to tuned tree-based models. Notably, we show a significant boost in performance compared to the base in-context model, demonstrating the efficacy of our approach and advancing the frontier of deep learning in tabular data.
A Geometric View of Data Complexity: Efficient Local Intrinsic Dimension Estimation with Diffusion Models
Jun 05, 2024

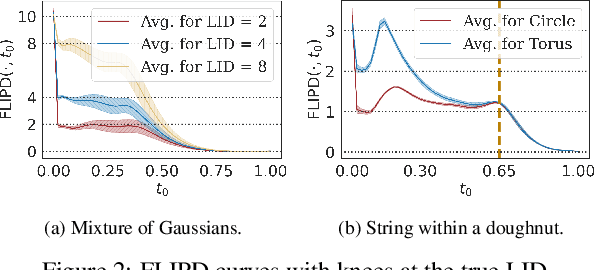
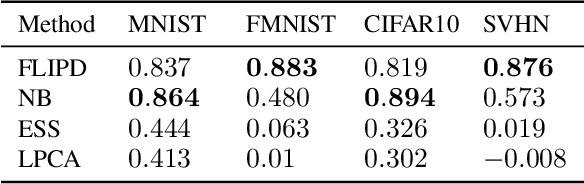
High-dimensional data commonly lies on low-dimensional submanifolds, and estimating the local intrinsic dimension (LID) of a datum -- i.e. the dimension of the submanifold it belongs to -- is a longstanding problem. LID can be understood as the number of local factors of variation: the more factors of variation a datum has, the more complex it tends to be. Estimating this quantity has proven useful in contexts ranging from generalization in neural networks to detection of out-of-distribution data, adversarial examples, and AI-generated text. The recent successes of deep generative models present an opportunity to leverage them for LID estimation, but current methods based on generative models produce inaccurate estimates, require more than a single pre-trained model, are computationally intensive, or do not exploit the best available deep generative models, i.e. diffusion models (DMs). In this work, we show that the Fokker-Planck equation associated with a DM can provide a LID estimator which addresses all the aforementioned deficiencies. Our estimator, called FLIPD, is compatible with all popular DMs, and outperforms existing baselines on LID estimation benchmarks. We also apply FLIPD on natural images where the true LID is unknown. Compared to competing estimators, FLIPD exhibits a higher correlation with non-LID measures of complexity, better matches a qualitative assessment of complexity, and is the only estimator to remain tractable with high-resolution images at the scale of Stable Diffusion.
Tabular Data Contrastive Learning via Class-Conditioned and Feature-Correlation Based Augmentation
Apr 30, 2024
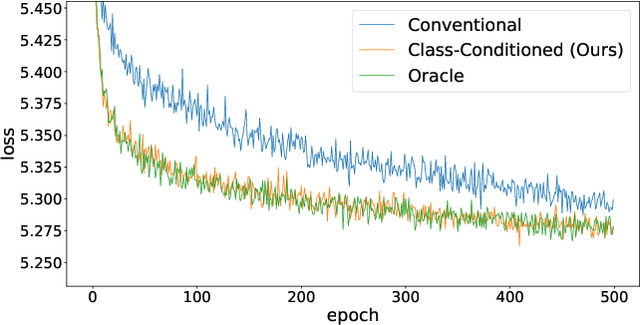


Contrastive learning is a model pre-training technique by first creating similar views of the original data, and then encouraging the data and its corresponding views to be close in the embedding space. Contrastive learning has witnessed success in image and natural language data, thanks to the domain-specific augmentation techniques that are both intuitive and effective. Nonetheless, in tabular domain, the predominant augmentation technique for creating views is through corrupting tabular entries via swapping values, which is not as sound or effective. We propose a simple yet powerful improvement to this augmentation technique: corrupting tabular data conditioned on class identity. Specifically, when corrupting a specific tabular entry from an anchor row, instead of randomly sampling a value in the same feature column from the entire table uniformly, we only sample from rows that are identified to be within the same class as the anchor row. We assume the semi-supervised learning setting, and adopt the pseudo labeling technique for obtaining class identities over all table rows. We also explore the novel idea of selecting features to be corrupted based on feature correlation structures. Extensive experiments show that the proposed approach consistently outperforms the conventional corruption method for tabular data classification tasks. Our code is available at https://github.com/willtop/Tabular-Class-Conditioned-SSL.
Deep Generative Models through the Lens of the Manifold Hypothesis: A Survey and New Connections
Apr 03, 2024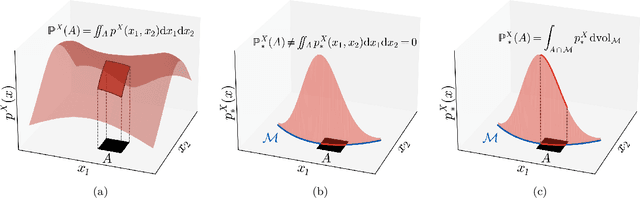


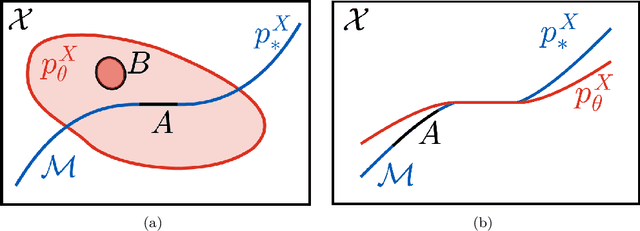
In recent years there has been increased interest in understanding the interplay between deep generative models (DGMs) and the manifold hypothesis. Research in this area focuses on understanding the reasons why commonly-used DGMs succeed or fail at learning distributions supported on unknown low-dimensional manifolds, as well as developing new models explicitly designed to account for manifold-supported data. This manifold lens provides both clarity as to why some DGMs (e.g. diffusion models and some generative adversarial networks) empirically surpass others (e.g. likelihood-based models such as variational autoencoders, normalizing flows, or energy-based models) at sample generation, and guidance for devising more performant DGMs. We carry out the first survey of DGMs viewed through this lens, making two novel contributions along the way. First, we formally establish that numerical instability of high-dimensional likelihoods is unavoidable when modelling low-dimensional data. We then show that DGMs on learned representations of autoencoders can be interpreted as approximately minimizing Wasserstein distance: this result, which applies to latent diffusion models, helps justify their outstanding empirical results. The manifold lens provides a rich perspective from which to understand DGMs, which we aim to make more accessible and widespread.