 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConf-Gen: Conformal Uncertainty Quantification for Generative Models
May 27, 2026Conformal prediction (CP) and its extension, conformal risk control (CRC), are established frameworks for quantifying uncertainty in supervised machine learning through formal guarantees. However, recent breakthroughs in artificial intelligence (AI) have been driven by unsupervised generative models, such as large language models (LLMs) and image generators, which are not directly compatible with CP or CRC. In this work we introduce conformal generation (Conf-Gen), a general framework adapting CRC to generative tasks while relaxing its theoretical assumptions. Conf-Gen unifies and generalizes previous attempts to apply CP to LLMs, and extends conformal methodology to entirely new domains. We demonstrate the flexibility of Conf-Gen through some novel applications, including obtaining conformal guarantees on: image generators producing non-memorized images, conversational AI systems having asked enough clarifying questions, and the output of AI agents being correct.
On Convolutions, Intrinsic Dimension, and Diffusion Models
Jun 25, 2025The manifold hypothesis asserts that data of interest in high-dimensional ambient spaces, such as image data, lies on unknown low-dimensional submanifolds. Diffusion models (DMs) -- which operate by convolving data with progressively larger amounts of Gaussian noise and then learning to revert this process -- have risen to prominence as the most performant generative models, and are known to be able to learn distributions with low-dimensional support. For a given datum in one of these submanifolds, we should thus intuitively expect DMs to have implicitly learned its corresponding local intrinsic dimension (LID), i.e. the dimension of the submanifold it belongs to. Kamkari et al. (2024b) recently showed that this is indeed the case by linking this LID to the rate of change of the log marginal densities of the DM with respect to the amount of added noise, resulting in an LID estimator known as FLIPD. LID estimators such as FLIPD have a plethora of uses, among others they quantify the complexity of a given datum, and can be used to detect outliers, adversarial examples and AI-generated text. FLIPD achieves state-of-the-art performance at LID estimation, yet its theoretical underpinnings are incomplete since Kamkari et al. (2024b) only proved its correctness under the highly unrealistic assumption of affine submanifolds. In this work we bridge this gap by formally proving the correctness of FLIPD under realistic assumptions. Additionally, we show that an analogous result holds when Gaussian convolutions are replaced with uniform ones, and discuss the relevance of this result.
Textual Bayes: Quantifying Uncertainty in LLM-Based Systems
Jun 11, 2025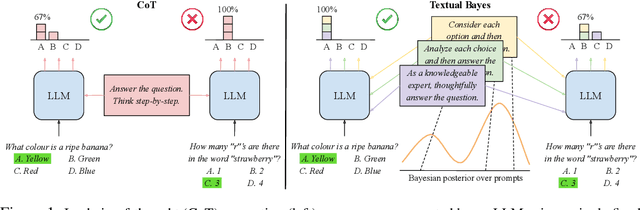
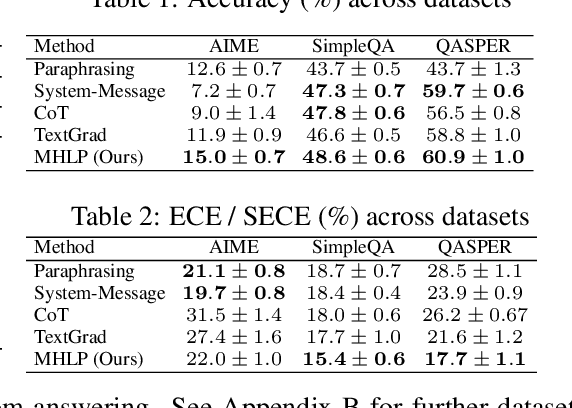
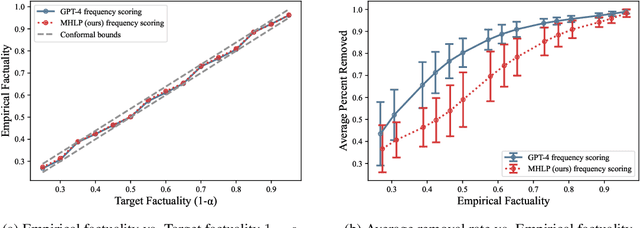
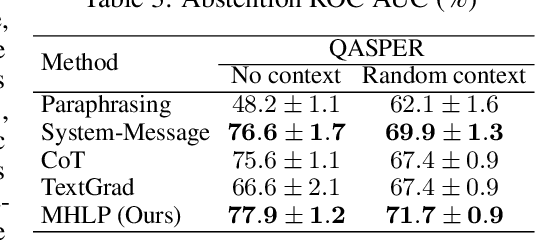
Although large language models (LLMs) are becoming increasingly capable of solving challenging real-world tasks, accurately quantifying their uncertainty remains a critical open problem, which limits their applicability in high-stakes domains. This challenge is further compounded by the closed-source, black-box nature of many state-of-the-art LLMs. Moreover, LLM-based systems can be highly sensitive to the prompts that bind them together, which often require significant manual tuning (i.e., prompt engineering). In this work, we address these challenges by viewing LLM-based systems through a Bayesian lens. We interpret prompts as textual parameters in a statistical model, allowing us to use a small training dataset to perform Bayesian inference over these prompts. This novel perspective enables principled uncertainty quantification over both the model's textual parameters and its downstream predictions, while also incorporating prior beliefs about these parameters expressed in free-form text. To perform Bayesian inference, a difficult problem even for well-studied data modalities, we introduce Metropolis-Hastings through LLM Proposals (MHLP), a novel Markov chain Monte Carlo (MCMC) algorithm that combines prompt optimization techniques with standard MCMC methods. MHLP is a turnkey modification to existing LLM pipelines, including those that rely exclusively on closed-source models. Empirically, we demonstrate that our method yields improvements in both predictive accuracy and uncertainty quantification (UQ) on a range of LLM benchmarks and UQ tasks. More broadly, our work demonstrates a viable path for incorporating methods from the rich Bayesian literature into the era of LLMs, paving the way for more reliable and calibrated LLM-based systems.
Temporal Dependencies in Feature Importance for Time Series Predictions
Jul 29, 2021
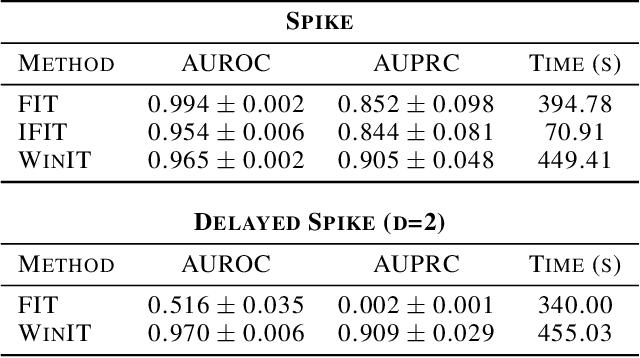
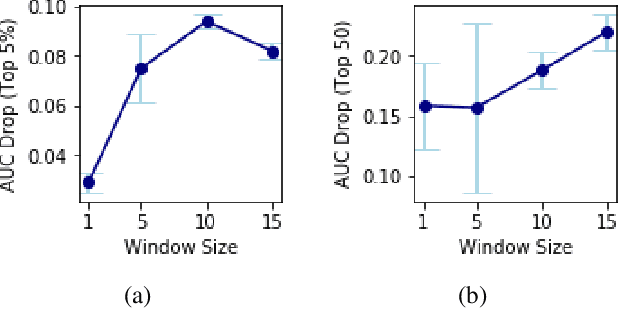
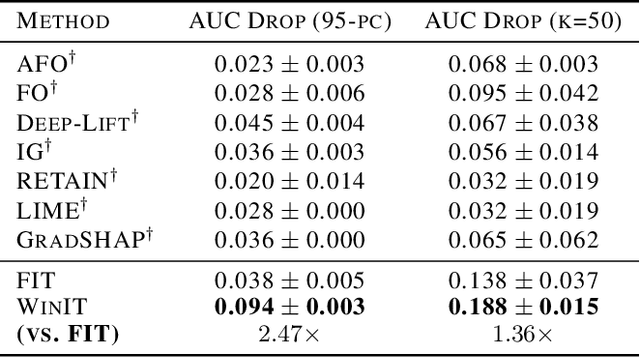
Explanation methods applied to sequential models for multivariate time series prediction are receiving more attention in machine learning literature. While current methods perform well at providing instance-wise explanations, they struggle to efficiently and accurately make attributions over long periods of time and with complex feature interactions. We propose WinIT, a framework for evaluating feature importance in time series prediction settings by quantifying the shift in predictive distribution over multiple instances in a windowed setting. Comprehensive empirical evidence shows our method improves on the previous state-of-the-art, FIT, by capturing temporal dependencies in feature importance. We also demonstrate how the solution improves the appropriate attribution of features within time steps, which existing interpretability methods often fail to do. We compare with baselines on simulated and real-world clinical data. WinIT achieves 2.47x better performance than FIT and other feature importance methods on real-world clinical MIMIC-mortality task. The code for this work is available at https://github.com/layer6ai-labs/WinIT.
Diabetes Mellitus Forecasting Using Population Health Data in Ontario, Canada
Apr 08, 2019
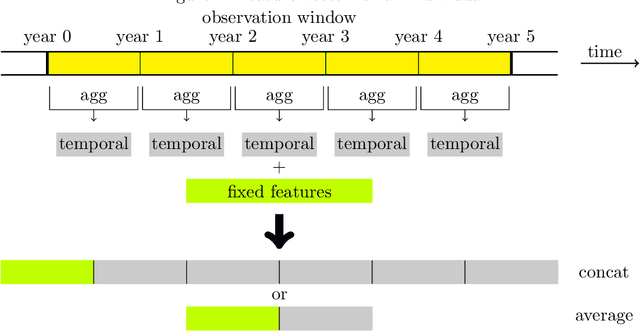
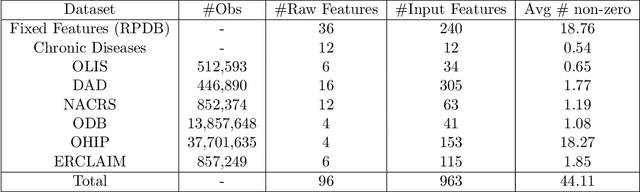

Leveraging health administrative data (HAD) datasets for predicting the risk of chronic diseases including diabetes has gained a lot of attention in the machine learning community recently. In this paper, we use the largest health records datasets of patients in Ontario,Canada. Provided by the Institute of Clinical Evaluative Sciences (ICES), this database is age, gender and ethnicity-diverse. The datasets include demographics, lab measurements,drug benefits, healthcare system interactions, ambulatory and hospitalizations records. We perform one of the first large-scale machine learning studies with this data to study the task of predicting diabetes in a range of 1-10 years ahead, which requires no additional screening of individuals.In the best setup, we reach a test AUC of 80.3 with a single-model trained on an observation window of 5 years with a one-year buffer using all datasets. A subset of top 15 features alone (out of a total of 963) could provide a test AUC of 79.1. In this paper, we provide extensive machine learning model performance and feature contribution analysis, which enables us to narrow down to the most important features useful for diabetes forecasting. Examples include chronic conditions such as asthma and hypertension, lab results, diagnostic codes in insurance claims, age and geographical information.