 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiabetes Mellitus Forecasting Using Population Health Data in Ontario, Canada
Paper and Code
Apr 08, 2019
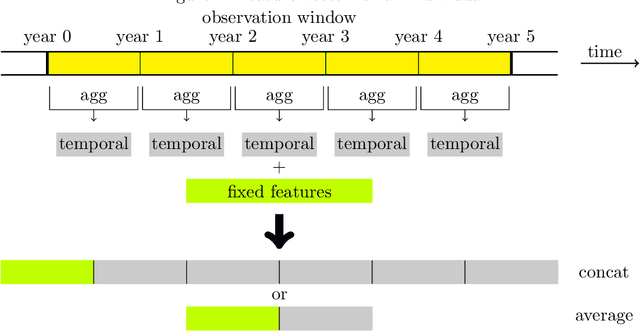
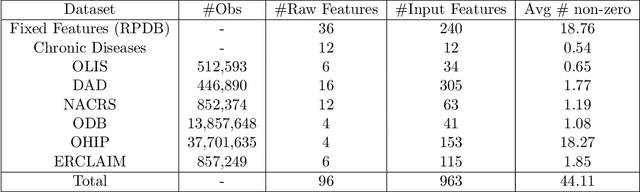

Leveraging health administrative data (HAD) datasets for predicting the risk of chronic diseases including diabetes has gained a lot of attention in the machine learning community recently. In this paper, we use the largest health records datasets of patients in Ontario,Canada. Provided by the Institute of Clinical Evaluative Sciences (ICES), this database is age, gender and ethnicity-diverse. The datasets include demographics, lab measurements,drug benefits, healthcare system interactions, ambulatory and hospitalizations records. We perform one of the first large-scale machine learning studies with this data to study the task of predicting diabetes in a range of 1-10 years ahead, which requires no additional screening of individuals.In the best setup, we reach a test AUC of 80.3 with a single-model trained on an observation window of 5 years with a one-year buffer using all datasets. A subset of top 15 features alone (out of a total of 963) could provide a test AUC of 79.1. In this paper, we provide extensive machine learning model performance and feature contribution analysis, which enables us to narrow down to the most important features useful for diabetes forecasting. Examples include chronic conditions such as asthma and hypertension, lab results, diagnostic codes in insurance claims, age and geographical information.