 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeshMimic: Geometry-Aware Humanoid Motion Learning through 3D Scene Reconstruction
Feb 17, 2026Humanoid motion control has witnessed significant breakthroughs in recent years, with deep reinforcement learning (RL) emerging as a primary catalyst for achieving complex, human-like behaviors. However, the high dimensionality and intricate dynamics of humanoid robots make manual motion design impractical, leading to a heavy reliance on expensive motion capture (MoCap) data. These datasets are not only costly to acquire but also frequently lack the necessary geometric context of the surrounding physical environment. Consequently, existing motion synthesis frameworks often suffer from a decoupling of motion and scene, resulting in physical inconsistencies such as contact slippage or mesh penetration during terrain-aware tasks. In this work, we present MeshMimic, an innovative framework that bridges 3D scene reconstruction and embodied intelligence to enable humanoid robots to learn coupled "motion-terrain" interactions directly from video. By leveraging state-of-the-art 3D vision models, our framework precisely segments and reconstructs both human trajectories and the underlying 3D geometry of terrains and objects. We introduce an optimization algorithm based on kinematic consistency to extract high-quality motion data from noisy visual reconstructions, alongside a contact-invariant retargeting method that transfers human-environment interaction features to the humanoid agent. Experimental results demonstrate that MeshMimic achieves robust, highly dynamic performance across diverse and challenging terrains. Our approach proves that a low-cost pipeline utilizing only consumer-grade monocular sensors can facilitate the training of complex physical interactions, offering a scalable path toward the autonomous evolution of humanoid robots in unstructured environments.
SARMAE: Masked Autoencoder for SAR Representation Learning
Dec 18, 2025Synthetic Aperture Radar (SAR) imagery plays a critical role in all-weather, day-and-night remote sensing applications. However, existing SAR-oriented deep learning is constrained by data scarcity, while the physically grounded speckle noise in SAR imagery further hampers fine-grained semantic representation learning. To address these challenges, we propose SARMAE, a Noise-Aware Masked Autoencoder for self-supervised SAR representation learning. Specifically, we construct SAR-1M, the first million-scale SAR dataset, with additional paired optical images, to enable large-scale pre-training. Building upon this, we design Speckle-Aware Representation Enhancement (SARE), which injects SAR-specific speckle noise into masked autoencoders to facilitate noise-aware and robust representation learning. Furthermore, we introduce Semantic Anchor Representation Constraint (SARC), which leverages paired optical priors to align SAR features and ensure semantic consistency. Extensive experiments across multiple SAR datasets demonstrate that SARMAE achieves state-of-the-art performance on classification, detection, and segmentation tasks. Code and models will be available at https://github.com/MiliLab/SARMAE.
SimCast: Enhancing Precipitation Nowcasting with Short-to-Long Term Knowledge Distillation
Oct 09, 2025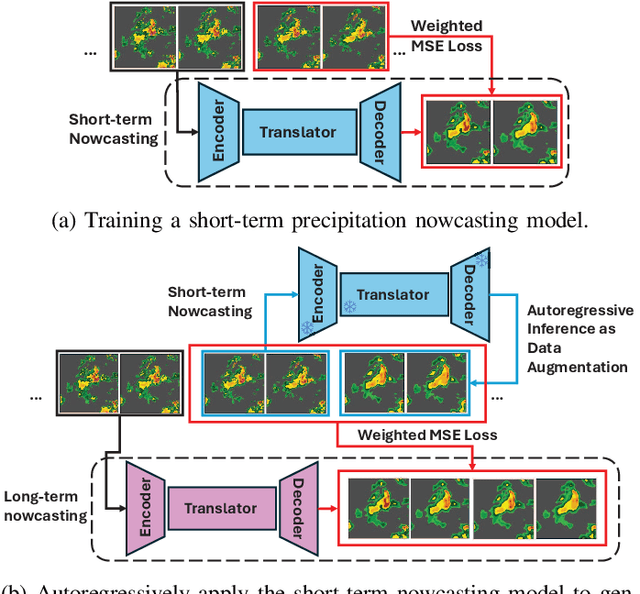
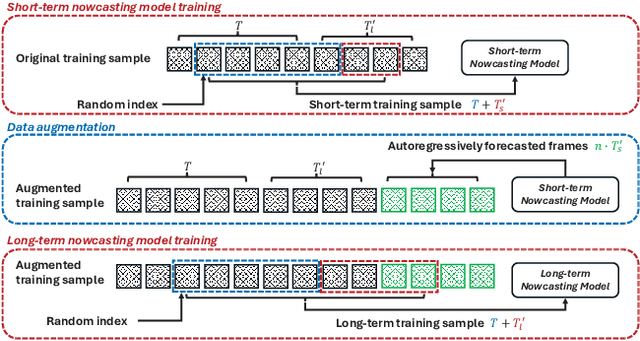
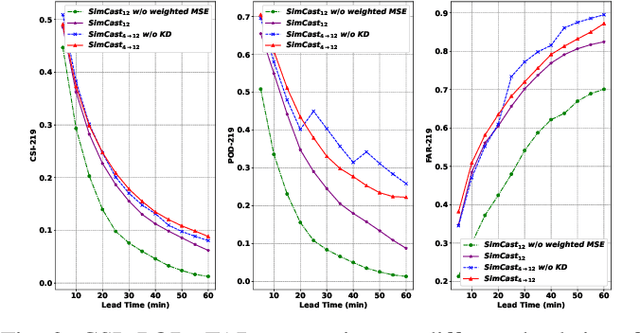
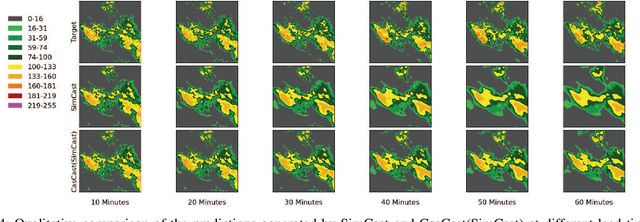
Precipitation nowcasting predicts future radar sequences based on current observations, which is a highly challenging task driven by the inherent complexity of the Earth system. Accurate nowcasting is of utmost importance for addressing various societal needs, including disaster management, agriculture, transportation, and energy optimization. As a complementary to existing non-autoregressive nowcasting approaches, we investigate the impact of prediction horizons on nowcasting models and propose SimCast, a novel training pipeline featuring a short-to-long term knowledge distillation technique coupled with a weighted MSE loss to prioritize heavy rainfall regions. Improved nowcasting predictions can be obtained without introducing additional overhead during inference. As SimCast generates deterministic predictions, we further integrate it into a diffusion-based framework named CasCast, leveraging the strengths from probabilistic models to overcome limitations such as blurriness and distribution shift in deterministic outputs. Extensive experimental results on three benchmark datasets validate the effectiveness of the proposed framework, achieving mean CSI scores of 0.452 on SEVIR, 0.474 on HKO-7, and 0.361 on MeteoNet, which outperforms existing approaches by a significant margin.
* accepted by ICME 2025
Humanoid Occupancy: Enabling A Generalized Multimodal Occupancy Perception System on Humanoid Robots
Jul 27, 2025Humanoid robot technology is advancing rapidly, with manufacturers introducing diverse heterogeneous visual perception modules tailored to specific scenarios. Among various perception paradigms, occupancy-based representation has become widely recognized as particularly suitable for humanoid robots, as it provides both rich semantic and 3D geometric information essential for comprehensive environmental understanding. In this work, we present Humanoid Occupancy, a generalized multimodal occupancy perception system that integrates hardware and software components, data acquisition devices, and a dedicated annotation pipeline. Our framework employs advanced multi-modal fusion techniques to generate grid-based occupancy outputs encoding both occupancy status and semantic labels, thereby enabling holistic environmental understanding for downstream tasks such as task planning and navigation. To address the unique challenges of humanoid robots, we overcome issues such as kinematic interference and occlusion, and establish an effective sensor layout strategy. Furthermore, we have developed the first panoramic occupancy dataset specifically for humanoid robots, offering a valuable benchmark and resource for future research and development in this domain. The network architecture incorporates multi-modal feature fusion and temporal information integration to ensure robust perception. Overall, Humanoid Occupancy delivers effective environmental perception for humanoid robots and establishes a technical foundation for standardizing universal visual modules, paving the way for the widespread deployment of humanoid robots in complex real-world scenarios.
Occupancy World Model for Robots
May 07, 2025Understanding and forecasting the scene evolutions deeply affect the exploration and decision of embodied agents. While traditional methods simulate scene evolutions through trajectory prediction of potential instances, current works use the occupancy world model as a generative framework for describing fine-grained overall scene dynamics. However, existing methods cluster on the outdoor structured road scenes, while ignoring the exploration of forecasting 3D occupancy scene evolutions for robots in indoor scenes. In this work, we explore a new framework for learning the scene evolutions of observed fine-grained occupancy and propose an occupancy world model based on the combined spatio-temporal receptive field and guided autoregressive transformer to forecast the scene evolutions, called RoboOccWorld. We propose the Conditional Causal State Attention (CCSA), which utilizes camera poses of next state as conditions to guide the autoregressive transformer to adapt and understand the indoor robotics scenarios. In order to effectively exploit the spatio-temporal cues from historical observations, Hybrid Spatio-Temporal Aggregation (HSTA) is proposed to obtain the combined spatio-temporal receptive field based on multi-scale spatio-temporal windows. In addition, we restructure the OccWorld-ScanNet benchmark based on local annotations to facilitate the evaluation of the indoor 3D occupancy scene evolution prediction task. Experimental results demonstrate that our RoboOccWorld outperforms state-of-the-art methods in indoor 3D occupancy scene evolution prediction task. The code will be released soon.
RoboOcc: Enhancing the Geometric and Semantic Scene Understanding for Robots
Apr 20, 20253D occupancy prediction enables the robots to obtain spatial fine-grained geometry and semantics of the surrounding scene, and has become an essential task for embodied perception. Existing methods based on 3D Gaussians instead of dense voxels do not effectively exploit the geometry and opacity properties of Gaussians, which limits the network's estimation of complex environments and also limits the description of the scene by 3D Gaussians. In this paper, we propose a 3D occupancy prediction method which enhances the geometric and semantic scene understanding for robots, dubbed RoboOcc. It utilizes the Opacity-guided Self-Encoder (OSE) to alleviate the semantic ambiguity of overlapping Gaussians and the Geometry-aware Cross-Encoder (GCE) to accomplish the fine-grained geometric modeling of the surrounding scene. We conduct extensive experiments on Occ-ScanNet and EmbodiedOcc-ScanNet datasets, and our RoboOcc achieves state-of the-art performance in both local and global camera settings. Further, in ablation studies of Gaussian parameters, the proposed RoboOcc outperforms the state-of-the-art methods by a large margin of (8.47, 6.27) in IoU and mIoU metric, respectively. The codes will be released soon.
HumanoidPano: Hybrid Spherical Panoramic-LiDAR Cross-Modal Perception for Humanoid Robots
Mar 13, 2025The perceptual system design for humanoid robots poses unique challenges due to inherent structural constraints that cause severe self-occlusion and limited field-of-view (FOV). We present HumanoidPano, a novel hybrid cross-modal perception framework that synergistically integrates panoramic vision and LiDAR sensing to overcome these limitations. Unlike conventional robot perception systems that rely on monocular cameras or standard multi-sensor configurations, our method establishes geometrically-aware modality alignment through a spherical vision transformer, enabling seamless fusion of 360 visual context with LiDAR's precise depth measurements. First, Spherical Geometry-aware Constraints (SGC) leverage panoramic camera ray properties to guide distortion-regularized sampling offsets for geometric alignment. Second, Spatial Deformable Attention (SDA) aggregates hierarchical 3D features via spherical offsets, enabling efficient 360{\deg}-to-BEV fusion with geometrically complete object representations. Third, Panoramic Augmentation (AUG) combines cross-view transformations and semantic alignment to enhance BEV-panoramic feature consistency during data augmentation. Extensive evaluations demonstrate state-of-the-art performance on the 360BEV-Matterport benchmark. Real-world deployment on humanoid platforms validates the system's capability to generate accurate BEV segmentation maps through panoramic-LiDAR co-perception, directly enabling downstream navigation tasks in complex environments. Our work establishes a new paradigm for embodied perception in humanoid robotics.
DRESS: Disentangled Representation-based Self-Supervised Meta-Learning for Diverse Tasks
Mar 12, 2025Meta-learning represents a strong class of approaches for solving few-shot learning tasks. Nonetheless, recent research suggests that simply pre-training a generic encoder can potentially surpass meta-learning algorithms. In this paper, we first discuss the reasons why meta-learning fails to stand out in these few-shot learning experiments, and hypothesize that it is due to the few-shot learning tasks lacking diversity. We propose DRESS, a task-agnostic Disentangled REpresentation-based Self-Supervised meta-learning approach that enables fast model adaptation on highly diversified few-shot learning tasks. Specifically, DRESS utilizes disentangled representation learning to create self-supervised tasks that can fuel the meta-training process. Furthermore, we also propose a class-partition based metric for quantifying the task diversity directly on the input space. We validate the effectiveness of DRESS through experiments on datasets with multiple factors of variation and varying complexity. The results suggest that DRESS is able to outperform competing methods on the majority of the datasets and task setups. Through this paper, we advocate for a re-examination of proper setups for task adaptation studies, and aim to reignite interest in the potential of meta-learning for solving few-shot learning tasks via disentangled representations.
Tabular Data Contrastive Learning via Class-Conditioned and Feature-Correlation Based Augmentation
Apr 30, 2024
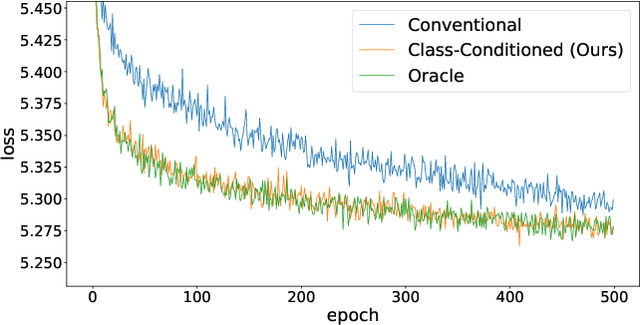


Contrastive learning is a model pre-training technique by first creating similar views of the original data, and then encouraging the data and its corresponding views to be close in the embedding space. Contrastive learning has witnessed success in image and natural language data, thanks to the domain-specific augmentation techniques that are both intuitive and effective. Nonetheless, in tabular domain, the predominant augmentation technique for creating views is through corrupting tabular entries via swapping values, which is not as sound or effective. We propose a simple yet powerful improvement to this augmentation technique: corrupting tabular data conditioned on class identity. Specifically, when corrupting a specific tabular entry from an anchor row, instead of randomly sampling a value in the same feature column from the entire table uniformly, we only sample from rows that are identified to be within the same class as the anchor row. We assume the semi-supervised learning setting, and adopt the pseudo labeling technique for obtaining class identities over all table rows. We also explore the novel idea of selecting features to be corrupted based on feature correlation structures. Extensive experiments show that the proposed approach consistently outperforms the conventional corruption method for tabular data classification tasks. Our code is available at https://github.com/willtop/Tabular-Class-Conditioned-SSL.
Transfer Learning with Reconstruction Loss
Apr 12, 2024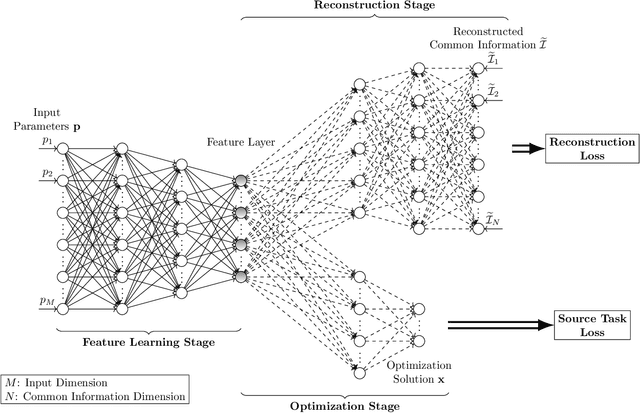
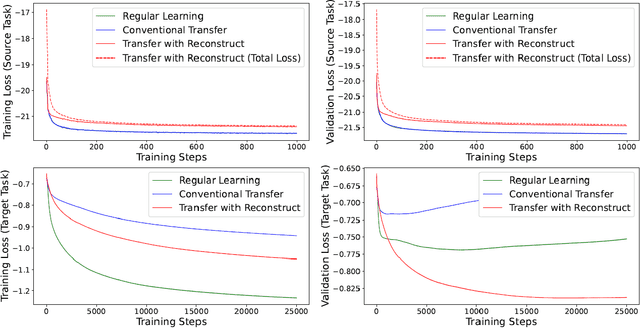
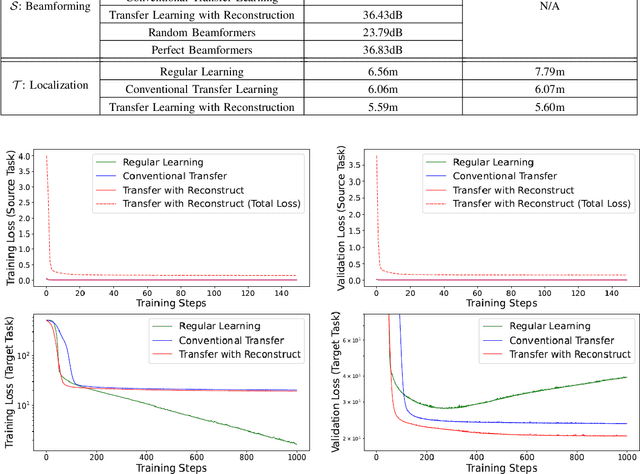
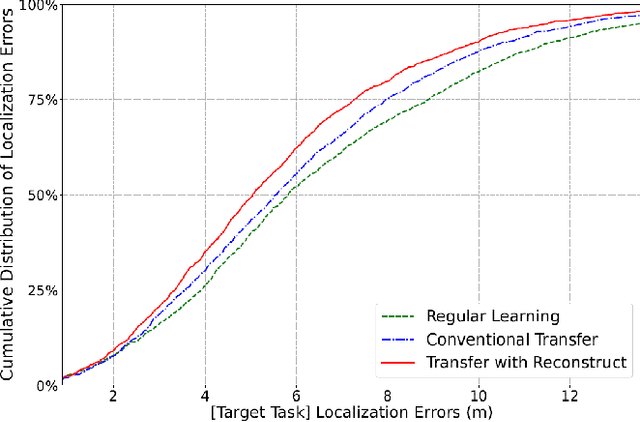
In most applications of utilizing neural networks for mathematical optimization, a dedicated model is trained for each specific optimization objective. However, in many scenarios, several distinct yet correlated objectives or tasks often need to be optimized on the same set of problem inputs. Instead of independently training a different neural network for each problem separately, it would be more efficient to exploit the correlations between these objectives and to train multiple neural network models with shared model parameters and feature representations. To achieve this, this paper first establishes the concept of common information: the shared knowledge required for solving the correlated tasks, then proposes a novel approach for model training by adding into the model an additional reconstruction stage associated with a new reconstruction loss. This loss is for reconstructing the common information starting from a selected hidden layer in the model. The proposed approach encourages the learned features to be general and transferable, and therefore can be readily used for efficient transfer learning. For numerical simulations, three applications are studied: transfer learning on classifying MNIST handwritten digits, the device-to-device wireless network power allocation, and the multiple-input-single-output network downlink beamforming and localization. Simulation results suggest that the proposed approach is highly efficient in data and model complexity, is resilient to over-fitting, and has competitive performances.