 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Agent Memory and Exploration Learning via Novelty Signals
Jun 01, 2026In open-ended environments, exploration is fundamental for autonomous agents, yet current language model agents struggle with this. Effective exploration requires memory, but retaining raw interaction histories is computationally expensive over long trajectories. While latent memory offers a solution to compress interaction histories, its training lacks reliable supervisory signals. We introduce \textbf{J}oint \textbf{A}gent \textbf{M}emory and \textbf{E}xploration \textbf{L}earning (\textbf{JAMEL}), a framework that trains agentic memory and exploration policy together through novelty-driven interaction. We observe that memory and exploration form a mutually dependent loop: sustained exploration requires memory to distinguish exhausted behaviors from unseen ones, while novelty-seeking interaction provides the supervision needed to make memory useful for future exploration. By utilizing deterministic and persistent novelty signals such as code coverage in the GUI domain, we provide natural, annotation-free supervision for the memory module. Empirical evaluations demonstrate that \ours successfully generalizes to unseen environments. Its exploration capability outperforms open-weight baselines and rivals the exploration depth of a closed-source model while reducing token consumption. Our code and model are open-sourced at https://github.com/MobileLLM/JAMEL.
SimuWoB: Simulating Real-World Mobile Apps for Fast and Faithful GUI Agent Benchmarking
May 24, 2026Mobile GUI agents powered by large language models have progressed rapidly, creating urgent needs for realistic and comprehensive evaluation. Existing benchmarks prioritize reproducibility but are often limited to open-source apps or file-operation tasks for the difficulty of constructing rewards on real applications, leaving a gap between benchmark settings and real-world usage. Moreover, most benchmarks focus on basic grounding and navigation, with limited coverage of complex, long-horizon interactions. To address these limitations, we introduce SimuWoB, a fully synthetic benchmark for mobile GUI agents with 120 challenging tasks spanning diverse types and difficulty levels. We build a robust virtual environment generation framework that synthesizes high-fidelity tasks and environments, and automatically provides valid rewards for each task. Each environment is deployed as a backend-free webpage accessible via URL, enabling efficient and reproducible evaluation. We conduct comprehensive experiments on several state-of-the-art mobile GUI agents. The average success rate is only 27.92%, dropping to 17.82% on long-horizon tasks, which reveals substantial weaknesses in current agents under complex scenarios. Evaluation result comparison with real-world sample tasks demonstrate that agent assessments based on our synthetic environment generalize well. We further provide diagnostic insights across key capability dimensions and discuss implications for future mobile GUI agent development.
GRIP-VLM: Group-Relative Importance Pruning for Efficient Vision-Language Models
May 13, 2026In Vision-Language Models (VLMs), processing a massive number of visual tokens incurs prohibitive computational overhead. While recent training-aware pruning methods attempt to selectively discard redundant tokens, they largely rely on continuous-gradient relaxations. However, visual token pruning is inherently a discrete, non-convex combinatorial problem; consequently, these continuous approximations frequently trap the optimization in sub-optimal local minima, especially under aggressive compression budgets. To overcome this fundamental bottleneck, we propose GRIP-VLM, a Group-Relative Importance Pruning framework driven by Reinforcement Learning. Rather than relying on smooth-gradient assumptions, GRIP-VLM formulates pruning as a Markov Decision Process, employing a Group Relative Policy Optimization (GRPO) paradigm anchored by supervised warm-up to directly explore the discrete selection space. Integrated with a budget-aware scorer, our lightweight agent dynamically evaluates per-token importance and adapts to arbitrary compression ratios without retraining. Extensive experiments across diverse multimodal benchmarks demonstrate that GRIP-VLM consistently outperforms heuristic and supervised-learning baselines, achieving a superior Pareto frontier and delivering up to a 15\% inference speedup at equal accuracy.
AgentProg: Empowering Long-Horizon GUI Agents with Program-Guided Context Management
Dec 11, 2025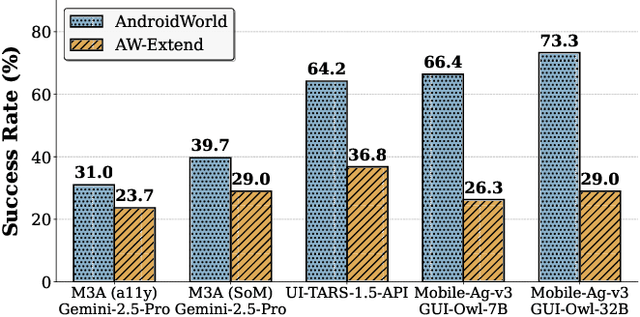

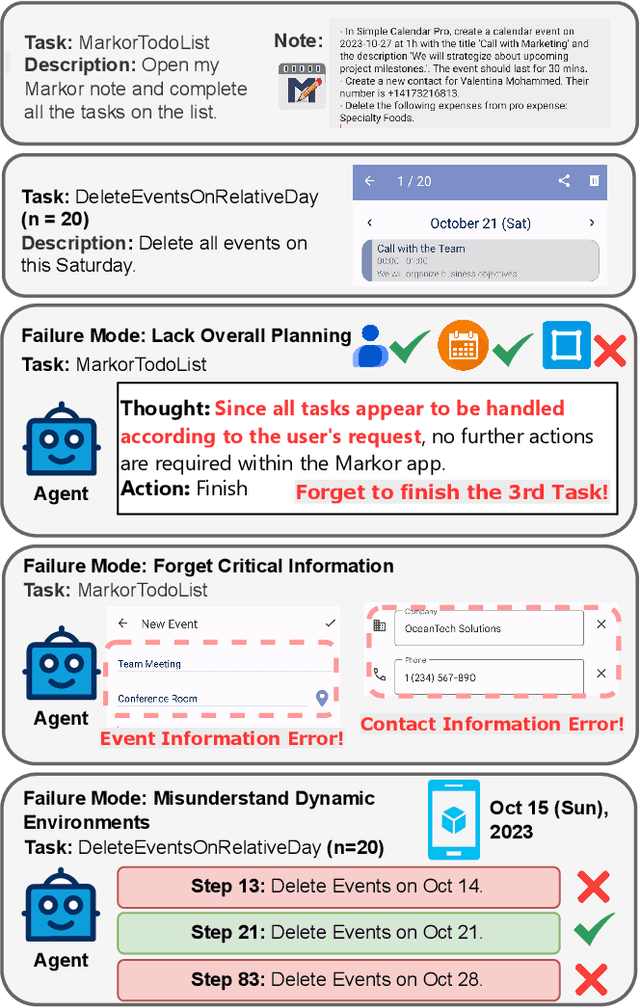

The rapid development of mobile GUI agents has stimulated growing research interest in long-horizon task automation. However, building agents for these tasks faces a critical bottleneck: the reliance on ever-expanding interaction history incurs substantial context overhead. Existing context management and compression techniques often fail to preserve vital semantic information, leading to degraded task performance. We propose AgentProg, a program-guided approach for agent context management that reframes the interaction history as a program with variables and control flow. By organizing information according to the structure of program, this structure provides a principled mechanism to determine which information should be retained and which can be discarded. We further integrate a global belief state mechanism inspired by Belief MDP framework to handle partial observability and adapt to unexpected environmental changes. Experiments on AndroidWorld and our extended long-horizon task suite demonstrate that AgentProg has achieved the state-of-the-art success rates on these benchmarks. More importantly, it maintains robust performance on long-horizon tasks while baseline methods experience catastrophic degradation. Our system is open-sourced at https://github.com/MobileLLM/AgentProg.
BudgetThinker: Empowering Budget-aware LLM Reasoning with Control Tokens
Aug 24, 2025Recent advancements in Large Language Models (LLMs) have leveraged increased test-time computation to enhance reasoning capabilities, a strategy that, while effective, incurs significant latency and resource costs, limiting their applicability in real-world time-constrained or cost-sensitive scenarios. This paper introduces BudgetThinker, a novel framework designed to empower LLMs with budget-aware reasoning, enabling precise control over the length of their thought processes. We propose a methodology that periodically inserts special control tokens during inference to continuously inform the model of its remaining token budget. This approach is coupled with a comprehensive two-stage training pipeline, beginning with Supervised Fine-Tuning (SFT) to familiarize the model with budget constraints, followed by a curriculum-based Reinforcement Learning (RL) phase that utilizes a length-aware reward function to optimize for both accuracy and budget adherence. We demonstrate that BudgetThinker significantly surpasses strong baselines in maintaining performance across a variety of reasoning budgets on challenging mathematical benchmarks. Our method provides a scalable and effective solution for developing efficient and controllable LLM reasoning, making advanced models more practical for deployment in resource-constrained and real-time environments.
GRAIL:Learning to Interact with Large Knowledge Graphs for Retrieval Augmented Reasoning
Aug 07, 2025Large Language Models (LLMs) integrated with Retrieval-Augmented Generation (RAG) techniques have exhibited remarkable performance across a wide range of domains. However, existing RAG approaches primarily operate on unstructured data and demonstrate limited capability in handling structured knowledge such as knowledge graphs. Meanwhile, current graph retrieval methods fundamentally struggle to capture holistic graph structures while simultaneously facing precision control challenges that manifest as either critical information gaps or excessive redundant connections, collectively undermining reasoning performance. To address this challenge, we propose GRAIL: Graph-Retrieval Augmented Interactive Learning, a framework designed to interact with large-scale graphs for retrieval-augmented reasoning. Specifically, GRAIL integrates LLM-guided random exploration with path filtering to establish a data synthesis pipeline, where a fine-grained reasoning trajectory is automatically generated for each task. Based on the synthesized data, we then employ a two-stage training process to learn a policy that dynamically decides the optimal actions at each reasoning step. The overall objective of precision-conciseness balance in graph retrieval is decoupled into fine-grained process-supervised rewards to enhance data efficiency and training stability. In practical deployment, GRAIL adopts an interactive retrieval paradigm, enabling the model to autonomously explore graph paths while dynamically balancing retrieval breadth and precision. Extensive experiments have shown that GRAIL achieves an average accuracy improvement of 21.01% and F1 improvement of 22.43% on three knowledge graph question-answering datasets. Our source code and datasets is available at https://github.com/Changgeww/GRAIL.
Mobile-Bench-v2: A More Realistic and Comprehensive Benchmark for VLM-based Mobile Agents
May 17, 2025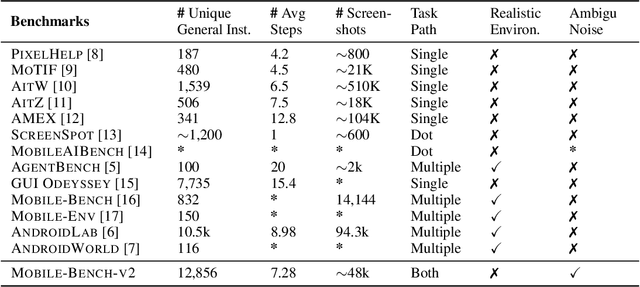
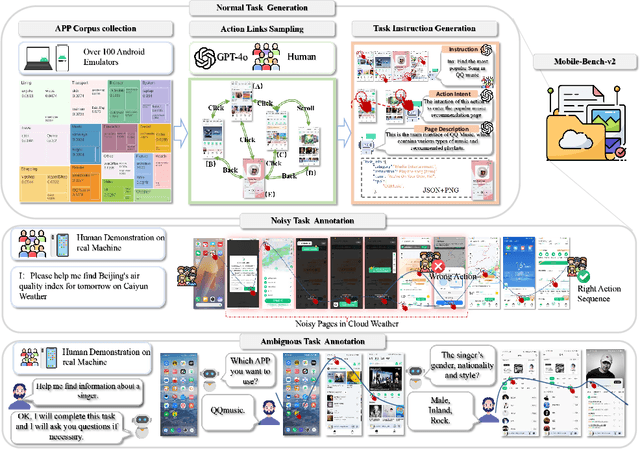
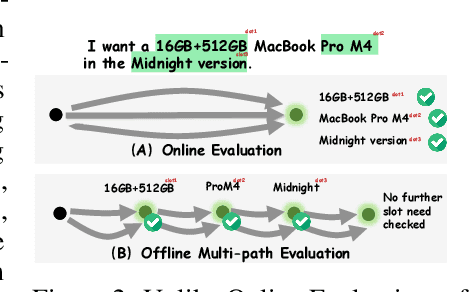
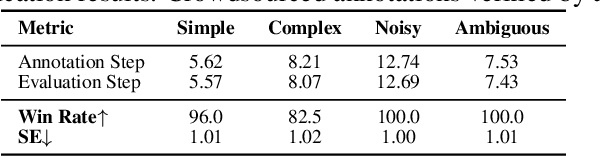
VLM-based mobile agents are increasingly popular due to their capabilities to interact with smartphone GUIs and XML-structured texts and to complete daily tasks. However, existing online benchmarks struggle with obtaining stable reward signals due to dynamic environmental changes. Offline benchmarks evaluate the agents through single-path trajectories, which stands in contrast to the inherently multi-solution characteristics of GUI tasks. Additionally, both types of benchmarks fail to assess whether mobile agents can handle noise or engage in proactive interactions due to a lack of noisy apps or overly full instructions during the evaluation process. To address these limitations, we use a slot-based instruction generation method to construct a more realistic and comprehensive benchmark named Mobile-Bench-v2. Mobile-Bench-v2 includes a common task split, with offline multi-path evaluation to assess the agent's ability to obtain step rewards during task execution. It contains a noisy split based on pop-ups and ads apps, and a contaminated split named AITZ-Noise to formulate a real noisy environment. Furthermore, an ambiguous instruction split with preset Q\&A interactions is released to evaluate the agent's proactive interaction capabilities. We conduct evaluations on these splits using the single-agent framework AppAgent-v1, the multi-agent framework Mobile-Agent-v2, as well as other mobile agents such as UI-Tars and OS-Atlas. Code and data are available at https://huggingface.co/datasets/xwk123/MobileBench-v2.
LLM-Explorer: Towards Efficient and Affordable LLM-based Exploration for Mobile Apps
May 15, 2025Large language models (LLMs) have opened new opportunities for automated mobile app exploration, an important and challenging problem that used to suffer from the difficulty of generating meaningful UI interactions. However, existing LLM-based exploration approaches rely heavily on LLMs to generate actions in almost every step, leading to a huge cost of token fees and computational resources. We argue that such extensive usage of LLMs is neither necessary nor effective, since many actions during exploration do not require, or may even be biased by the abilities of LLMs. Further, based on the insight that a precise and compact knowledge plays the central role for effective exploration, we introduce LLM-Explorer, a new exploration agent designed for efficiency and affordability. LLM-Explorer uses LLMs primarily for maintaining the knowledge instead of generating actions, and knowledge is used to guide action generation in a LLM-less manner. Based on a comparison with 5 strong baselines on 20 typical apps, LLM-Explorer was able to achieve the fastest and highest coverage among all automated app explorers, with over 148x lower cost than the state-of-the-art LLM-based approach.
Time's Up! An Empirical Study of LLM Reasoning Ability Under Output Length Constraint
Apr 22, 2025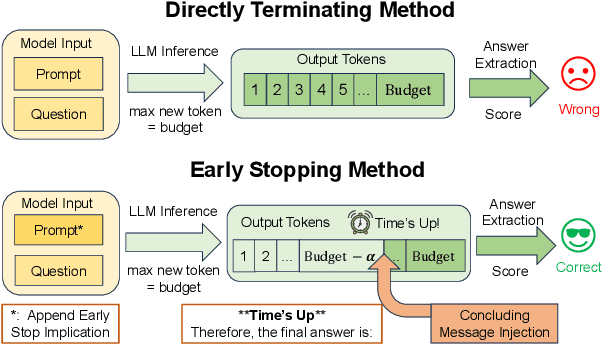
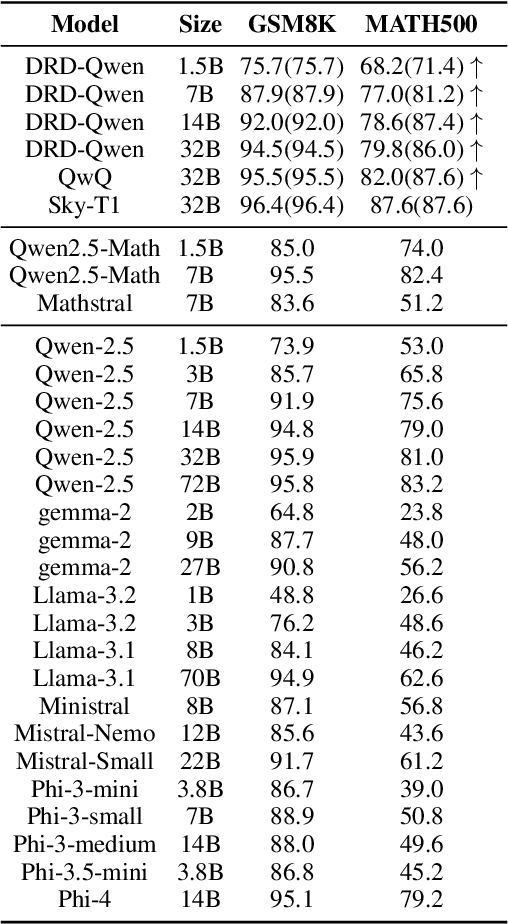
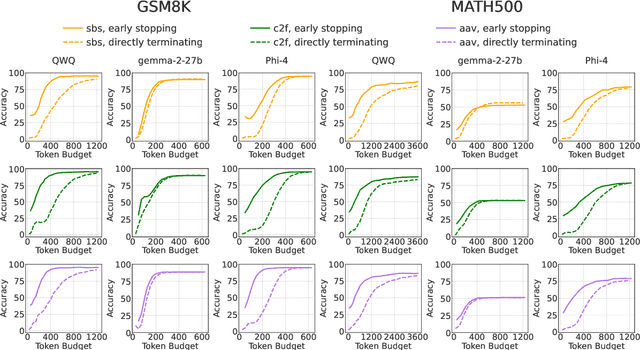
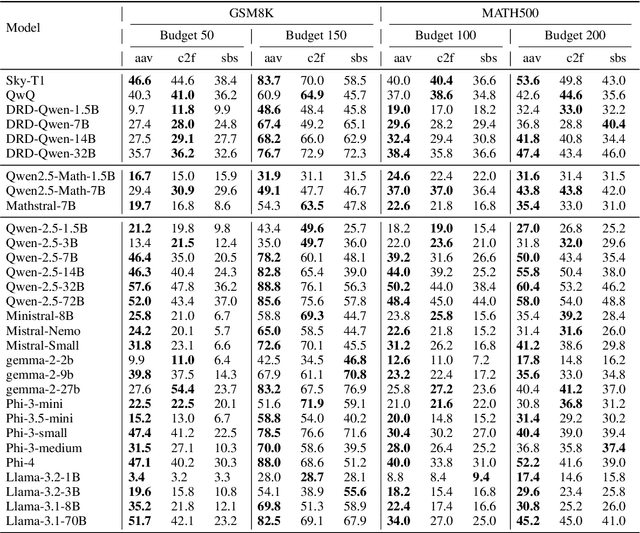
Recent work has demonstrated the remarkable potential of Large Language Models (LLMs) in test-time scaling. By making the models think before answering, they are able to achieve much higher accuracy with extra inference computation. However, in many real-world scenarios, models are used under time constraints, where an answer should be given to the user within a certain output length. It is unclear whether and how the reasoning abilities of LLMs remain effective under such constraints. We take a first look at this problem by conducting an in-depth empirical study. Specifically, we test more than 25 LLMs on common reasoning datasets under a wide range of output length budgets, and we analyze the correlation between the inference accuracy and various properties including model type, model size, prompt style, etc. We also consider the mappings between the token budgets and the actual on-device latency budgets. The results have demonstrated several interesting findings regarding the budget-aware LLM reasoning that differ from the unconstrained situation, e.g. the optimal choices of model sizes and prompts change under different budgets. These findings offer practical guidance for users to deploy LLMs under real-world latency constraints.
Advancing Mobile GUI Agents: A Verifier-Driven Approach to Practical Deployment
Mar 21, 2025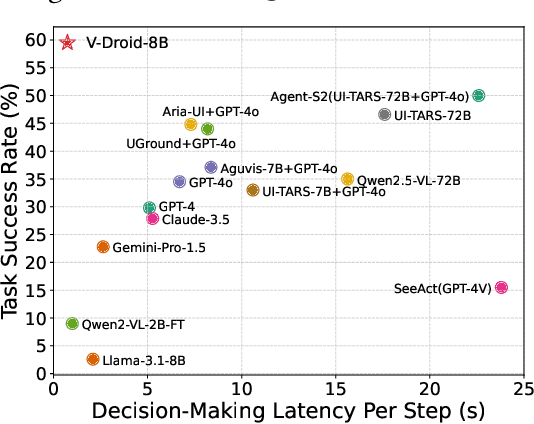
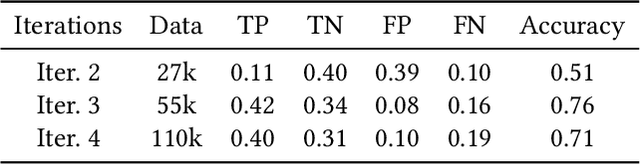
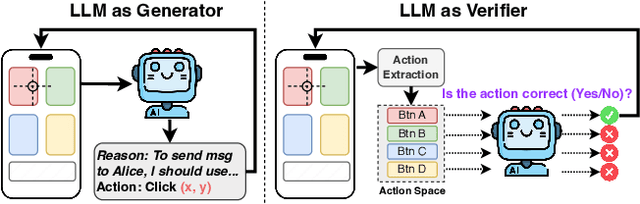
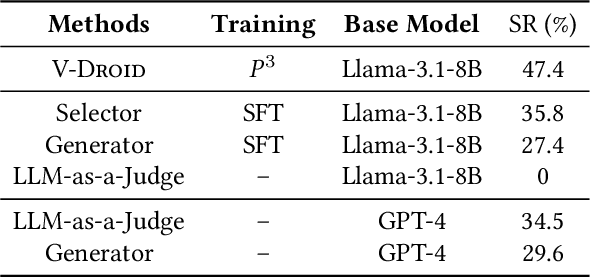
We propose V-Droid, a mobile GUI task automation agent. Unlike previous mobile agents that utilize Large Language Models (LLMs) as generators to directly generate actions at each step, V-Droid employs LLMs as verifiers to evaluate candidate actions before making final decisions. To realize this novel paradigm, we introduce a comprehensive framework for constructing verifier-driven mobile agents: the discretized action space construction coupled with the prefilling-only workflow to accelerate the verification process, the pair-wise progress preference training to significantly enhance the verifier's decision-making capabilities, and the scalable human-agent joint annotation scheme to efficiently collect the necessary data at scale. V-Droid sets a new state-of-the-art task success rate across several public mobile task automation benchmarks: 59.5% on AndroidWorld, 38.3% on AndroidLab, and 49% on MobileAgentBench, surpassing existing agents by 9.5%, 2.1%, and 9%, respectively. Furthermore, V-Droid achieves an impressively low latency of 0.7 seconds per step, making it the first mobile agent capable of delivering near-real-time, effective decision-making capabilities.