 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIMA-Q: Post-Training Quantization for Vision Transformers by Fisher Information Matrix Approximation
Jun 13, 2025Post-training quantization (PTQ) has stood out as a cost-effective and promising model compression paradigm in recent years, as it avoids computationally intensive model retraining. Nevertheless, current PTQ methods for Vision Transformers (ViTs) still suffer from significant accuracy degradation, especially under low-bit quantization. To address these shortcomings, we analyze the prevailing Hessian-guided quantization loss, and uncover certain limitations of conventional Hessian approximations. By following the block-wise reconstruction framework, we propose a novel PTQ method for ViTs, dubbed FIMA-Q. Specifically, we firstly establish the connection between KL divergence and FIM, which enables fast computation of the quantization loss during reconstruction. We further propose an efficient FIM approximation method, namely DPLR-FIM, by employing the diagonal plus low-rank principle, and formulate the ultimate quantization loss. Our extensive experiments, conducted across various vision tasks with representative ViT-based architectures on public datasets, demonstrate that our method substantially promotes the accuracy compared to the state-of-the-art approaches, especially in the case of low-bit quantization. The source code is available at https://github.com/ShiheWang/FIMA-Q.
MCPWorld: A Unified Benchmarking Testbed for API, GUI, and Hybrid Computer Use Agents
Jun 09, 2025(M)LLM-powered computer use agents (CUA) are emerging as a transformative technique to automate human-computer interaction. However, existing CUA benchmarks predominantly target GUI agents, whose evaluation methods are susceptible to UI changes and ignore function interactions exposed by application APIs, e.g., Model Context Protocol (MCP). To this end, we propose MCPWorld, the first automatic CUA testbed for API, GUI, and API-GUI hybrid agents. A key principle of MCPWorld is the use of "white-box apps", i.e., those with source code availability and can be revised/re-compiled as needed (e.g., adding MCP support), with two notable advantages: (1) It greatly broadens the design space of CUA, such as what and how the app features to be exposed/extracted as CUA-callable APIs. (2) It allows MCPWorld to programmatically verify task completion by directly monitoring application behavior through techniques like dynamic code instrumentation, offering robust, accurate CUA evaluation decoupled from specific agent implementations or UI states. Currently, MCPWorld includes 201 well curated and annotated user tasks, covering diversified use cases and difficulty levels. MCPWorld is also fully containerized with GPU acceleration support for flexible adoption on different OS/hardware environments. Our preliminary experiments, using a representative LLM-powered CUA framework, achieve 75.12% task completion accuracy, simultaneously providing initial evidence on the practical effectiveness of agent automation leveraging MCP. Overall, we anticipate MCPWorld to facilitate and standardize the benchmarking of next-generation computer use agents that can leverage rich external tools. Our code and dataset are publicly available at https://github.com/SAAgent/MCPWorld.
DroidCall: A Dataset for LLM-powered Android Intent Invocation
Nov 30, 2024



The growing capabilities of large language models in natural language understanding significantly strengthen existing agentic systems. To power performant on-device mobile agents for better data privacy, we introduce DroidCall, the first training and testing dataset for accurate Android intent invocation. With a highly flexible and reusable data generation pipeline, we constructed 10k samples in DroidCall. Given a task instruction in natural language, small language models such as Qwen2.5-3B and Gemma2-2B fine-tuned with DroidCall can approach or even surpass the capabilities of GPT-4o for accurate Android intent invocation. We also provide an end-to-end Android app equipped with these fine-tuned models to demonstrate the Android intent invocation process. The code and dataset are available at https://github.com/UbiquitousLearning/DroidCall.
LlamaTouch: A Faithful and Scalable Testbed for Mobile UI Automation Task Evaluation
Apr 12, 2024



The emergent large language/multimodal models facilitate the evolution of mobile agents, especially in the task of mobile UI automation. However, existing evaluation approaches, which rely on human validation or established datasets to compare agent-predicted actions with predefined ones, are unscalable and unfaithful. To overcome these limitations, this paper presents LlamaTouch, a testbed for on-device agent execution and faithful, scalable agent evaluation. By observing that the task execution process only transfers UI states, LlamaTouch employs a novel evaluation approach that only assesses whether an agent traverses all manually annotated, essential application/system states. LlamaTouch comprises three key techniques: (1) On-device task execution that enables mobile agents to interact with real mobile environments for task completion. (2) Fine-grained UI component annotation that merges pixel-level screenshots and textual screen hierarchies to explicitly identify and precisely annotate essential UI components with a rich set of designed annotation primitives. (3) A multi-level state matching algorithm that utilizes exact and fuzzy matching to accurately detect critical information in each screen with unpredictable UI layout/content dynamics. LlamaTouch currently incorporates four mobile agents and 495 UI automation tasks, encompassing both tasks in the widely-used datasets and our self-constructed ones for more diverse mobile applications. Evaluation results demonstrate the LlamaTouch's high faithfulness of evaluation in real environments and its better scalability than human validation. LlamaTouch also enables easy task annotation and integration of new mobile agents. Code and dataset are publicly available at https://github.com/LlamaTouch/LlamaTouch.
A Survey of Resource-efficient LLM and Multimodal Foundation Models
Jan 16, 2024
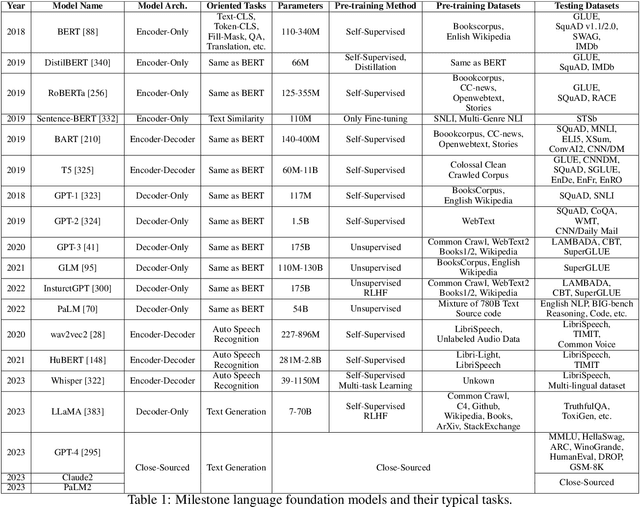
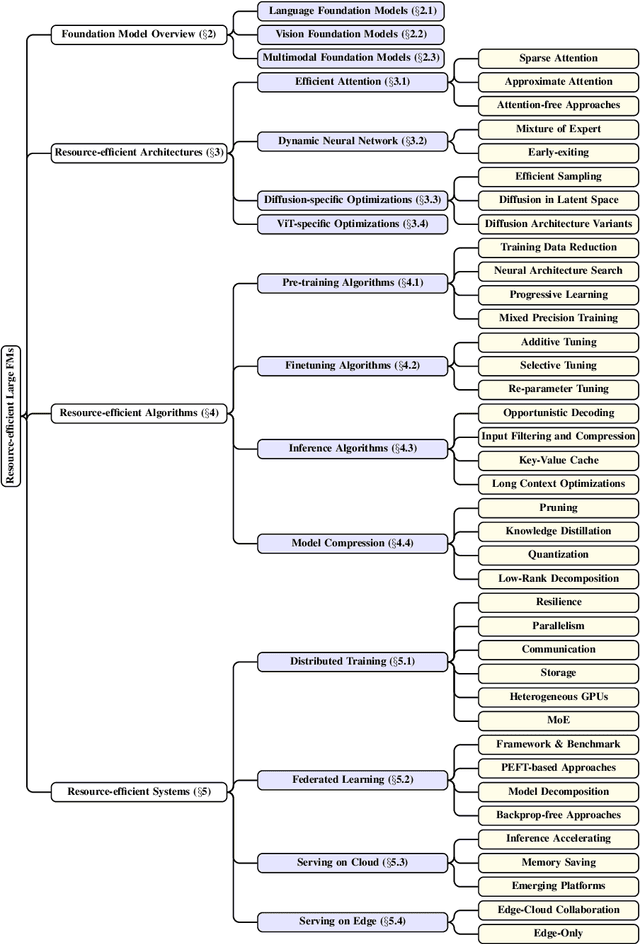
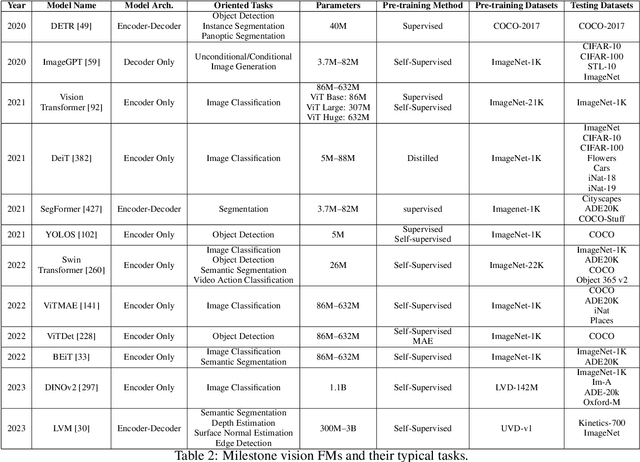
Large foundation models, including large language models (LLMs), vision transformers (ViTs), diffusion, and LLM-based multimodal models, are revolutionizing the entire machine learning lifecycle, from training to deployment. However, the substantial advancements in versatility and performance these models offer come at a significant cost in terms of hardware resources. To support the growth of these large models in a scalable and environmentally sustainable way, there has been a considerable focus on developing resource-efficient strategies. This survey delves into the critical importance of such research, examining both algorithmic and systemic aspects. It offers a comprehensive analysis and valuable insights gleaned from existing literature, encompassing a broad array of topics from cutting-edge model architectures and training/serving algorithms to practical system designs and implementations. The goal of this survey is to provide an overarching understanding of how current approaches are tackling the resource challenges posed by large foundation models and to potentially inspire future breakthroughs in this field.
Rethinking Mobile AI Ecosystem in the LLM Era
Aug 28, 2023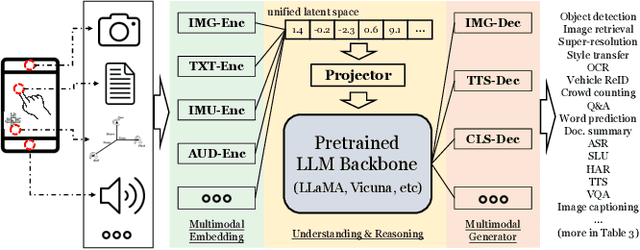
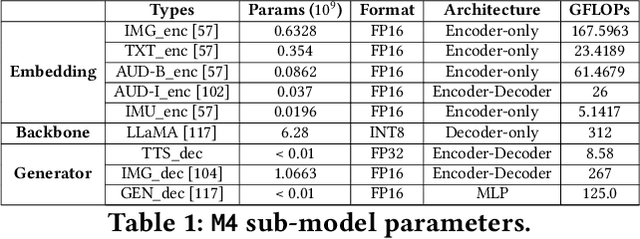
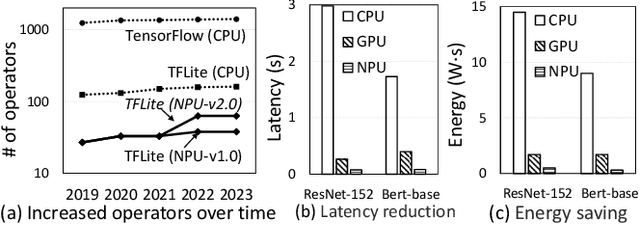
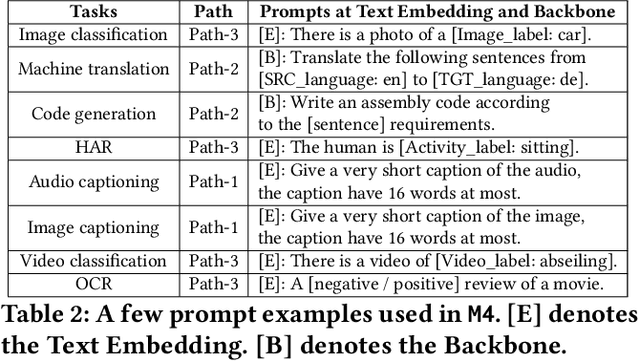
In today's landscape, smartphones have evolved into hubs for hosting a multitude of deep learning models aimed at local execution. A key realization driving this work is the notable fragmentation among these models, characterized by varied architectures, operators, and implementations. This fragmentation imposes a significant burden on the comprehensive optimization of hardware, system settings, and algorithms. Buoyed by the recent strides in large foundation models, this work introduces a pioneering paradigm for mobile AI: a collaborative management approach between the mobile OS and hardware, overseeing a foundational model capable of serving a broad spectrum of mobile AI tasks, if not all. This foundational model resides within the NPU and remains impervious to app or OS revisions, akin to firmware. Concurrently, each app contributes a concise, offline fine-tuned "adapter" tailored to distinct downstream tasks. From this concept emerges a concrete instantiation known as \sys. It amalgamates a curated selection of publicly available Large Language Models (LLMs) and facilitates dynamic data flow. This concept's viability is substantiated through the creation of an exhaustive benchmark encompassing 38 mobile AI tasks spanning 50 datasets, including domains such as Computer Vision (CV), Natural Language Processing (NLP), audio, sensing, and multimodal inputs. Spanning this benchmark, \sys unveils its impressive performance. It attains accuracy parity in 85\% of tasks, demonstrates improved scalability in terms of storage and memory, and offers satisfactory inference speed on Commercial Off-The-Shelf (COTS) mobile devices fortified with NPU support. This stands in stark contrast to task-specific models tailored for individual applications.
Boosting the Discriminant Power of Naive Bayes
Sep 20, 2022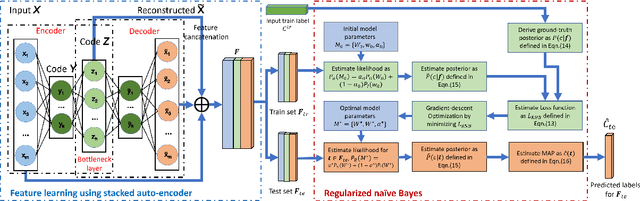
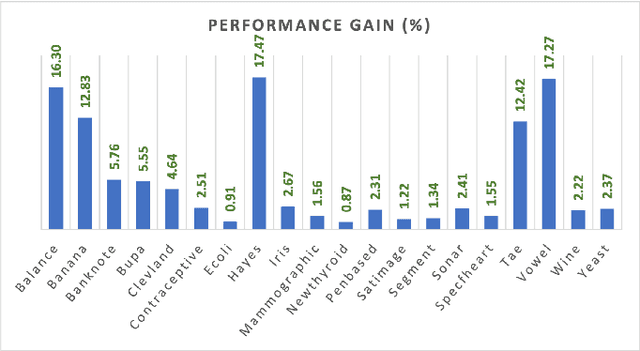
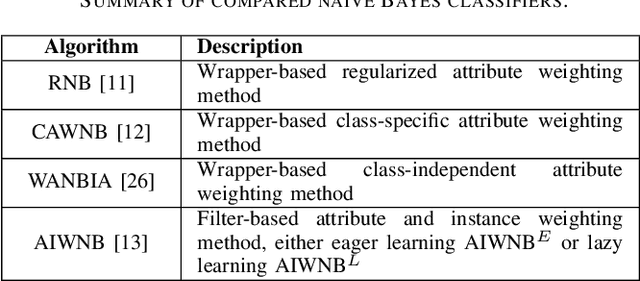
Naive Bayes has been widely used in many applications because of its simplicity and ability in handling both numerical data and categorical data. However, lack of modeling of correlations between features limits its performance. In addition, noise and outliers in the real-world dataset also greatly degrade the classification performance. In this paper, we propose a feature augmentation method employing a stack auto-encoder to reduce the noise in the data and boost the discriminant power of naive Bayes. The proposed stack auto-encoder consists of two auto-encoders for different purposes. The first encoder shrinks the initial features to derive a compact feature representation in order to remove the noise and redundant information. The second encoder boosts the discriminant power of the features by expanding them into a higher-dimensional space so that different classes of samples could be better separated in the higher-dimensional space. By integrating the proposed feature augmentation method with the regularized naive Bayes, the discrimination power of the model is greatly enhanced. The proposed method is evaluated on a set of machine-learning benchmark datasets. The experimental results show that the proposed method significantly and consistently outperforms the state-of-the-art naive Bayes classifiers.
A Max-relevance-min-divergence Criterion for Data Discretization with Applications on Naive Bayes
Sep 20, 2022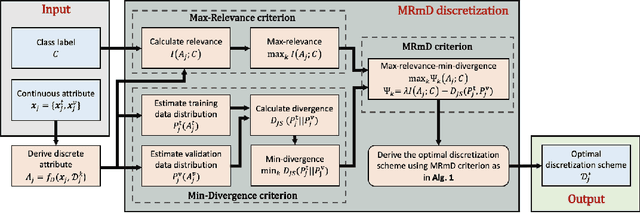
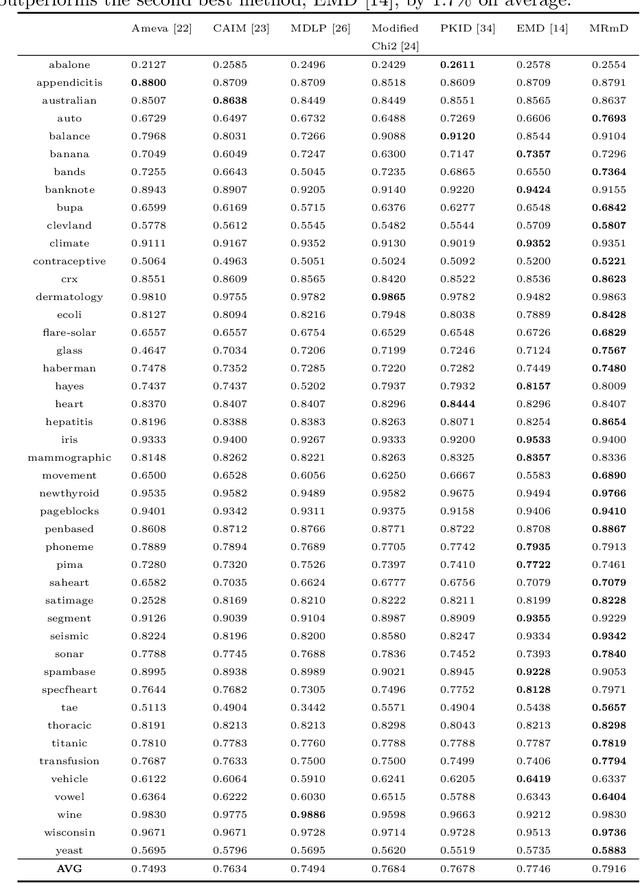
In many classification models, data is discretized to better estimate its distribution. Existing discretization methods often target at maximizing the discriminant power of discretized data, while overlooking the fact that the primary target of data discretization in classification is to improve the generalization performance. As a result, the data tend to be over-split into many small bins since the data without discretization retain the maximal discriminant information. Thus, we propose a Max-Dependency-Min-Divergence (MDmD) criterion that maximizes both the discriminant information and generalization ability of the discretized data. More specifically, the Max-Dependency criterion maximizes the statistical dependency between the discretized data and the classification variable while the Min-Divergence criterion explicitly minimizes the JS-divergence between the training data and the validation data for a given discretization scheme. The proposed MDmD criterion is technically appealing, but it is difficult to reliably estimate the high-order joint distributions of attributes and the classification variable. We hence further propose a more practical solution, Max-Relevance-Min-Divergence (MRmD) discretization scheme, where each attribute is discretized separately, by simultaneously maximizing the discriminant information and the generalization ability of the discretized data. The proposed MRmD is compared with the state-of-the-art discretization algorithms under the naive Bayes classification framework on 45 machine-learning benchmark datasets. It significantly outperforms all the compared methods on most of the datasets.
A Semi-Supervised Adaptive Discriminative Discretization Method Improving Discrimination Power of Regularized Naive Bayes
Nov 22, 2021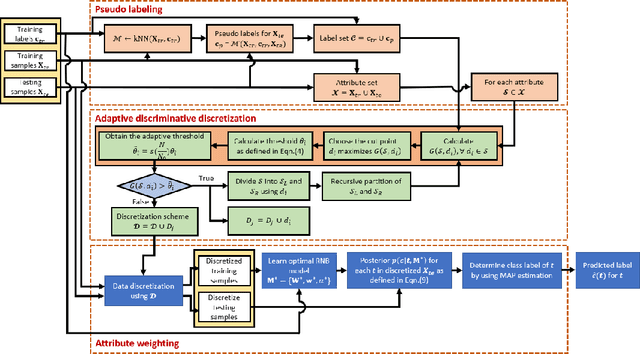
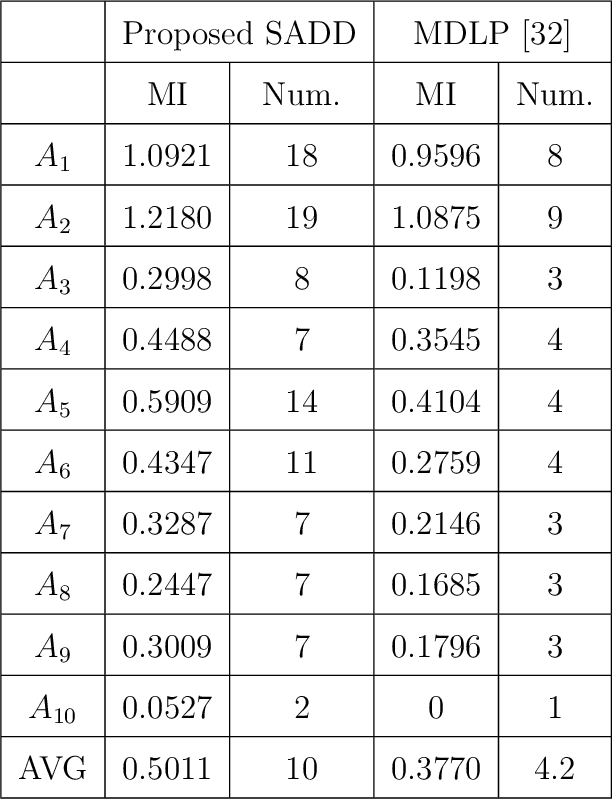
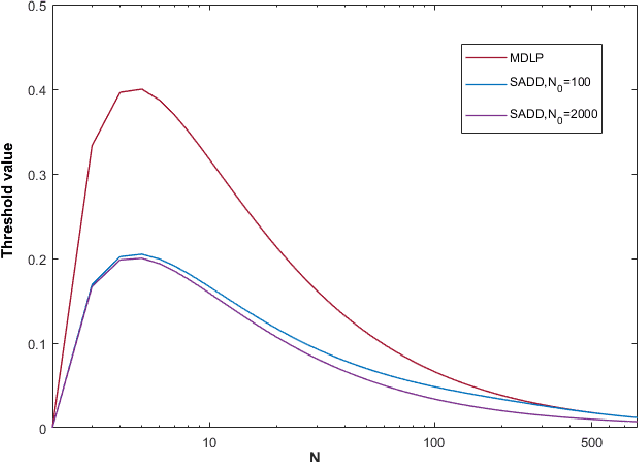
Recently, many improved naive Bayes methods have been developed with enhanced discrimination capabilities. Among them, regularized naive Bayes (RNB) produces excellent performance by balancing the discrimination power and generalization capability. Data discretization is important in naive Bayes. By grouping similar values into one interval, the data distribution could be better estimated. However, existing methods including RNB often discretize the data into too few intervals, which may result in a significant information loss. To address this problem, we propose a semi-supervised adaptive discriminative discretization framework for naive Bayes, which could better estimate the data distribution by utilizing both labeled data and unlabeled data through pseudo-labeling techniques. The proposed method also significantly reduces the information loss during discretization by utilizing an adaptive discriminative discretization scheme, and hence greatly improves the discrimination power of classifiers. The proposed RNB+, i.e., regularized naive Bayes utilizing the proposed discretization framework, is systematically evaluated on a wide range of machine-learning datasets. It significantly and consistently outperforms state-of-the-art NB classifiers.
A Data Augmentation Method by Mixing Up Negative Candidate Answers for Solving Raven's Progressive Matrices
Mar 09, 2021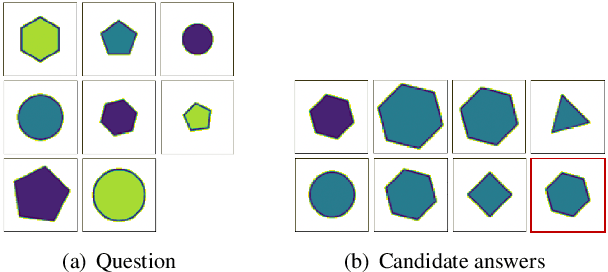

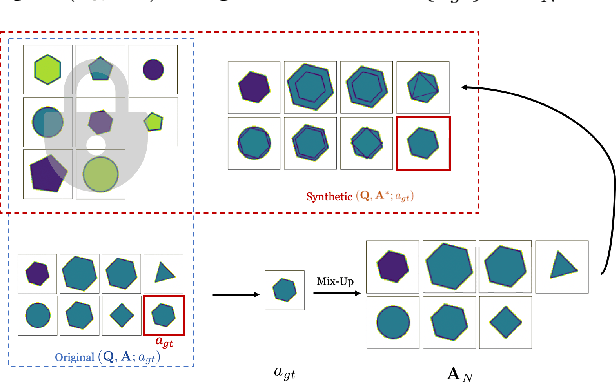
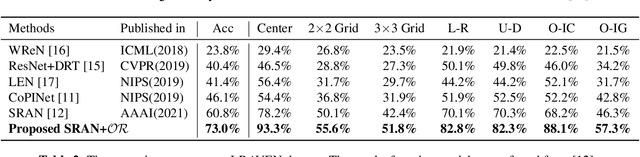
Raven's Progressive Matrices (RPMs) are frequently-used in testing human's visual reasoning ability. Recently developed RPM-like datasets and solution models transfer this kind of problems from cognitive science to computer science. In view of the poor generalization performance due to insufficient samples in RPM datasets, we propose a data augmentation strategy by image mix-up, which is generalizable to a variety of multiple-choice problems, especially for image-based RPM-like problems. By focusing on potential functionalities of negative candidate answers, the visual reasoning capability of the model is enhanced. By applying the proposed data augmentation method, we achieve significant and consistent improvement on various RPM-like datasets compared with the state-of-the-art models.