 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGBFRS: Robust Fuzzy Rough Sets via Granular-ball Computing
Jan 30, 2025



Fuzzy rough set theory is effective for processing datasets with complex attributes, supported by a solid mathematical foundation and closely linked to kernel methods in machine learning. Attribute reduction algorithms and classifiers based on fuzzy rough set theory exhibit promising performance in the analysis of high-dimensional multivariate complex data. However, most existing models operate at the finest granularity, rendering them inefficient and sensitive to noise, especially for high-dimensional big data. Thus, enhancing the robustness of fuzzy rough set models is crucial for effective feature selection. Muiti-garanularty granular-ball computing, a recent development, uses granular-balls of different sizes to adaptively represent and cover the sample space, performing learning based on these granular-balls. This paper proposes integrating multi-granularity granular-ball computing into fuzzy rough set theory, using granular-balls to replace sample points. The coarse-grained characteristics of granular-balls make the model more robust. Additionally, we propose a new method for generating granular-balls, scalable to the entire supervised method based on granular-ball computing. A forward search algorithm is used to select feature sequences by defining the correlation between features and categories through dependence functions. Experiments demonstrate the proposed model's effectiveness and superiority over baseline methods.
Boosting the Discriminant Power of Naive Bayes
Sep 20, 2022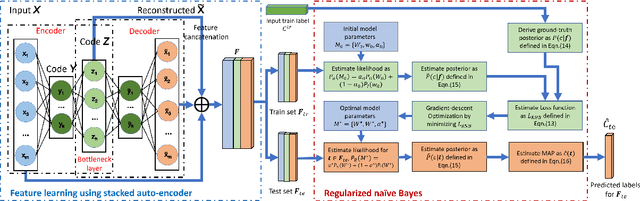
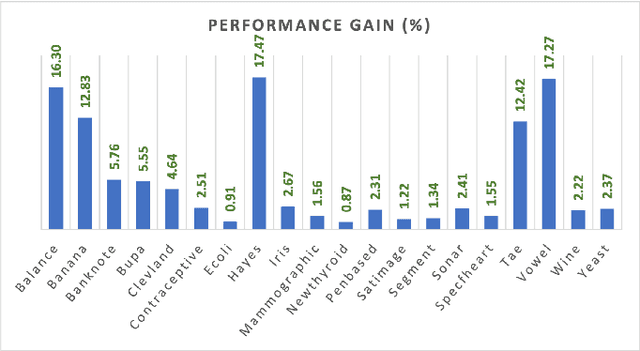
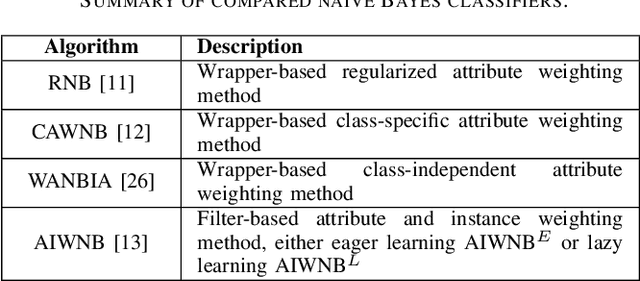
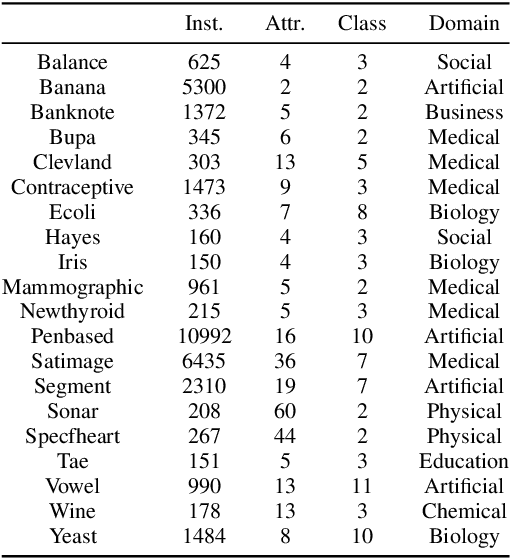
Naive Bayes has been widely used in many applications because of its simplicity and ability in handling both numerical data and categorical data. However, lack of modeling of correlations between features limits its performance. In addition, noise and outliers in the real-world dataset also greatly degrade the classification performance. In this paper, we propose a feature augmentation method employing a stack auto-encoder to reduce the noise in the data and boost the discriminant power of naive Bayes. The proposed stack auto-encoder consists of two auto-encoders for different purposes. The first encoder shrinks the initial features to derive a compact feature representation in order to remove the noise and redundant information. The second encoder boosts the discriminant power of the features by expanding them into a higher-dimensional space so that different classes of samples could be better separated in the higher-dimensional space. By integrating the proposed feature augmentation method with the regularized naive Bayes, the discrimination power of the model is greatly enhanced. The proposed method is evaluated on a set of machine-learning benchmark datasets. The experimental results show that the proposed method significantly and consistently outperforms the state-of-the-art naive Bayes classifiers.