 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeddle: A Distributed Orchestration System for Agentic RL Rollout
Mar 30, 2026Agentic Reinforcement Learning (RL) enables LLMs to solve complex tasks by alternating between a data-collection rollout phase and a policy training phase. During rollout, the agent generates trajectories, i.e., multi-step interactions between LLMs and external tools. Yet, frequent tool calls induce long-tailed trajectory generation that bottlenecks rollouts. This stems from step-centric designs that ignore trajectory context, triggering three system problems for long-tail trajectory generation: queueing delays, interference overhead, and inflated per-token time. We propose Heddle, a trajectory-centric system to optimize the when, where, and how of agentic rollout execution. Heddle integrates three core mechanisms: trajectory-level scheduling using runtime prediction and progressive priority to minimize cumulative queueing; trajectory-aware placement via presorted dynamic programming and opportunistic migration during idle tool call intervals to minimize interference; and trajectory-adaptive resource manager that dynamically tunes model parallelism to accelerate the per-token time of long-tail trajectories while maintaining high throughput for short trajectories. Evaluations across diverse agentic RL workloads demonstrate that Heddle effectively neutralizes the long-tail bottleneck, achieving up to 2.5$\times$ higher end-to-end rollout throughput compared to state-of-the-art baselines.
Bohrium + SciMaster: Building the Infrastructure and Ecosystem for Agentic Science at Scale
Dec 23, 2025



AI agents are emerging as a practical way to run multi-step scientific workflows that interleave reasoning with tool use and verification, pointing to a shift from isolated AI-assisted steps toward \emph{agentic science at scale}. This shift is increasingly feasible, as scientific tools and models can be invoked through stable interfaces and verified with recorded execution traces, and increasingly necessary, as AI accelerates scientific output and stresses the peer-review and publication pipeline, raising the bar for traceability and credible evaluation. However, scaling agentic science remains difficult: workflows are hard to observe and reproduce; many tools and laboratory systems are not agent-ready; execution is hard to trace and govern; and prototype AI Scientist systems are often bespoke, limiting reuse and systematic improvement from real workflow signals. We argue that scaling agentic science requires an infrastructure-and-ecosystem approach, instantiated in Bohrium+SciMaster. Bohrium acts as a managed, traceable hub for AI4S assets -- akin to a HuggingFace of AI for Science -- that turns diverse scientific data, software, compute, and laboratory systems into agent-ready capabilities. SciMaster orchestrates these capabilities into long-horizon scientific workflows, on which scientific agents can be composed and executed. Between infrastructure and orchestration, a \emph{scientific intelligence substrate} organizes reusable models, knowledge, and components into executable building blocks for workflow reasoning and action, enabling composition, auditability, and improvement through use. We demonstrate this stack with eleven representative master agents in real workflows, achieving orders-of-magnitude reductions in end-to-end scientific cycle time and generating execution-grounded signals from real workloads at multi-million scale.
TokenLake: A Unified Segment-level Prefix Cache Pool for Fine-grained Elastic Long-Context LLM Serving
Aug 24, 2025



Prefix caching is crucial to accelerate multi-turn interactions and requests with shared prefixes. At the cluster level, existing prefix caching systems are tightly coupled with request scheduling to optimize cache efficiency and computation performance together, leading to load imbalance, data redundancy, and memory fragmentation of caching systems across instances. To address these issues, memory pooling is promising to shield the scheduler from the underlying cache management so that it can focus on the computation optimization. However, because existing prefix caching systems only transfer increasingly longer prefix caches between instances, they cannot achieve low-latency memory pooling. To address these problems, we propose a unified segment-level prefix cache pool, TokenLake. It uses a declarative cache interface to expose requests' query tensors, prefix caches, and cache-aware operations to TokenLake for efficient pooling. Powered by this abstraction, TokenLake can manage prefix cache at the segment level with a heavy-hitter-aware load balancing algorithm to achieve better cache load balance, deduplication, and defragmentation. TokenLake also transparently minimizes the communication volume of query tensors and new caches. Based on TokenLake, the scheduler can schedule requests elastically by using existing techniques without considering prefix cache management. Evaluations on real-world workloads show that TokenLake can improve throughput by up to 2.6$\times$ and 2.0$\times$ and boost hit rate by 2.0$\times$ and 2.1$\times$, compared to state-of-the-art cache-aware routing and cache-centric PD-disaggregation solutions, respectively.
StreamRL: Scalable, Heterogeneous, and Elastic RL for LLMs with Disaggregated Stream Generation
Apr 22, 2025Reinforcement learning (RL) has become the core post-training technique for large language models (LLMs). RL for LLMs involves two stages: generation and training. The LLM first generates samples online, which are then used to derive rewards for training. The conventional view holds that the colocated architecture, where the two stages share resources via temporal multiplexing, outperforms the disaggregated architecture, in which dedicated resources are assigned to each stage. However, in real-world deployments, we observe that the colocated architecture suffers from resource coupling, where the two stages are constrained to use the same resources. This coupling compromises the scalability and cost-efficiency of colocated RL in large-scale training. In contrast, the disaggregated architecture allows for flexible resource allocation, supports heterogeneous training setups, and facilitates cross-datacenter deployment. StreamRL is designed with disaggregation from first principles and fully unlocks its potential by addressing two types of performance bottlenecks in existing disaggregated RL frameworks: pipeline bubbles, caused by stage dependencies, and skewness bubbles, resulting from long-tail output length distributions. To address pipeline bubbles, StreamRL breaks the traditional stage boundary in synchronous RL algorithms through stream generation and achieves full overlapping in asynchronous RL. To address skewness bubbles, StreamRL employs an output-length ranker model to identify long-tail samples and reduces generation time via skewness-aware dispatching and scheduling. Experiments show that StreamRL improves throughput by up to 2.66x compared to existing state-of-the-art systems, and improves cost-effectiveness by up to 1.33x in a heterogeneous, cross-datacenter setting.
LoongServe: Efficiently Serving Long-context Large Language Models with Elastic Sequence Parallelism
Apr 15, 2024The context window of large language models (LLMs) is rapidly increasing, leading to a huge variance in resource usage between different requests as well as between different phases of the same request. Restricted by static parallelism strategies, existing LLM serving systems cannot efficiently utilize the underlying resources to serve variable-length requests in different phases. To address this problem, we propose a new parallelism paradigm, elastic sequence parallelism (ESP), to elastically adapt to the variance between different requests and phases. Based on ESP, we design and build LoongServe, an LLM serving system that (1) improves computation efficiency by elastically adjusting the degree of parallelism in real-time, (2) improves communication efficiency by reducing key-value cache migration overhead and overlapping partial decoding communication with computation, and (3) improves GPU memory efficiency by reducing key-value cache fragmentation across instances. Our evaluation under diverse real-world datasets shows that LoongServe improves the maximum throughput by up to 3.85$\times$ compared to the chunked prefill and 5.81$\times$ compared to the prefill-decoding disaggregation.
A Survey of Resource-efficient LLM and Multimodal Foundation Models
Jan 16, 2024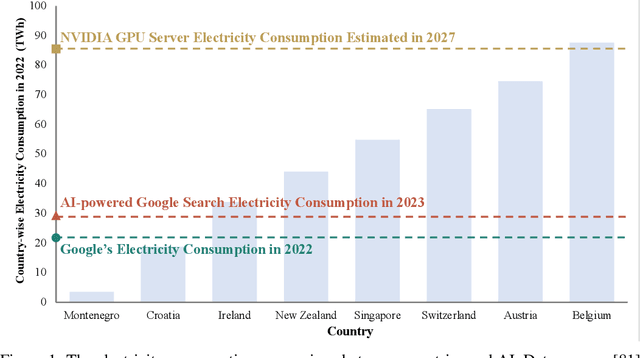
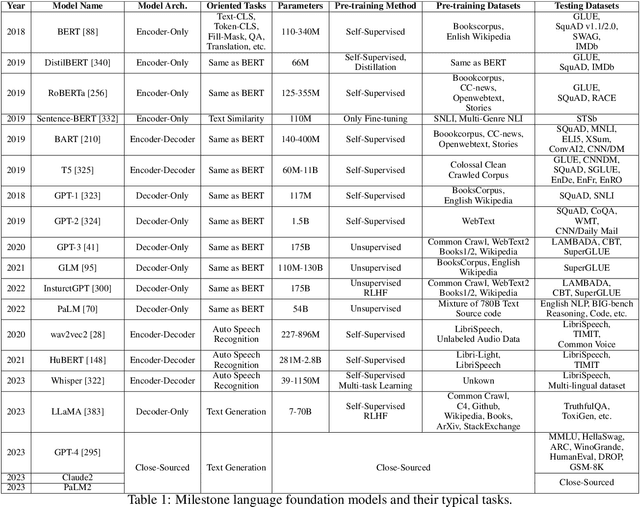
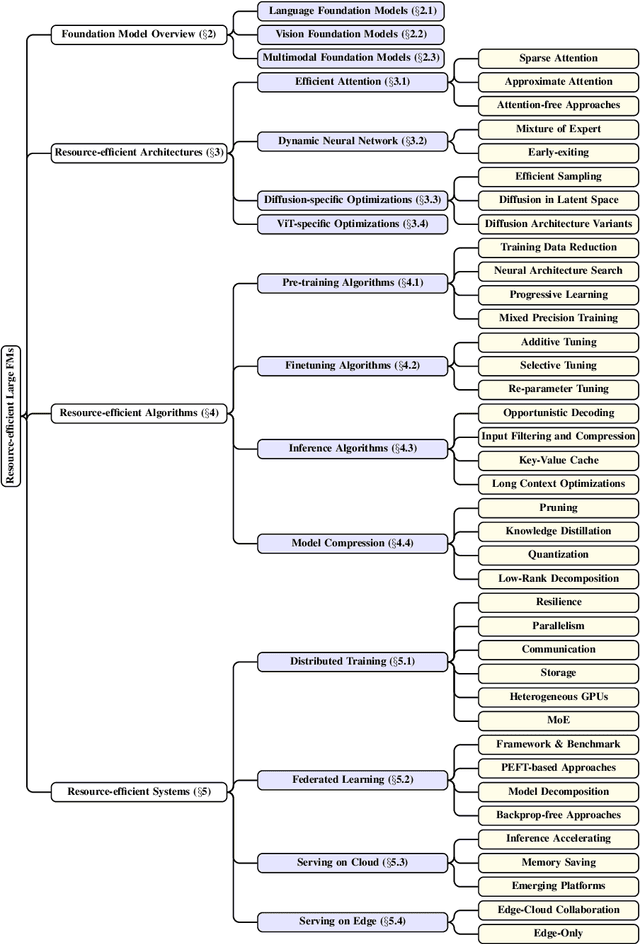
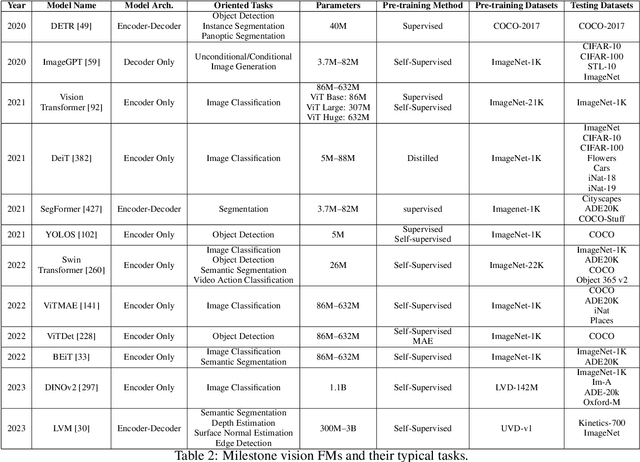
Large foundation models, including large language models (LLMs), vision transformers (ViTs), diffusion, and LLM-based multimodal models, are revolutionizing the entire machine learning lifecycle, from training to deployment. However, the substantial advancements in versatility and performance these models offer come at a significant cost in terms of hardware resources. To support the growth of these large models in a scalable and environmentally sustainable way, there has been a considerable focus on developing resource-efficient strategies. This survey delves into the critical importance of such research, examining both algorithmic and systemic aspects. It offers a comprehensive analysis and valuable insights gleaned from existing literature, encompassing a broad array of topics from cutting-edge model architectures and training/serving algorithms to practical system designs and implementations. The goal of this survey is to provide an overarching understanding of how current approaches are tackling the resource challenges posed by large foundation models and to potentially inspire future breakthroughs in this field.
Fast Distributed Inference Serving for Large Language Models
May 10, 2023



Large language models (LLMs) power a new generation of interactive AI applications exemplified by ChatGPT. The interactive nature of these applications demand low job completion time (JCT) for model inference. Existing LLM serving systems use run-to-completion processing for inference jobs, which suffers from head-of-line blocking and long JCT. We present FastServe, a distributed inference serving system for LLMs. FastServe exploits the autoregressive pattern of LLM inference to enable preemption at the granularity of each output token. FastServe uses preemptive scheduling to minimize JCT with a novel skip-join Multi-Level Feedback Queue scheduler. Based on the new semi information-agnostic setting of LLM inference, the scheduler leverages the input length information to assign an appropriate initial queue for each arrival job to join. The higher priority queues than the joined queue are skipped to reduce demotions. We design an efficient GPU memory management mechanism that proactively offloads and uploads intermediate states between GPU memory and host memory for LLM inference. We build a system prototype of FastServe based on NVIDIA FasterTransformer. Experimental results show that compared to the state-of-the-art solution Orca, FastServe improves the average and tail JCT by up to 5.1$\times$ and 6.4$\times$, respectively.