 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorEngine: A Program-level Knowledge-Infused Factor Mining Framework for Quantitative Investment
Mar 17, 2026We study alpha factor mining, the automated discovery of predictive signals from noisy, non-stationary market data-under a practical requirement that mined factors be directly executable and auditable, and that the discovery process remain computationally tractable at scale. Existing symbolic approaches are limited by bounded expressiveness, while neural forecasters often trade interpretability for performance and remain vulnerable to regime shifts and overfitting. We introduce FactorEngine (FE), a program-level factor discovery framework that casts factors as Turing-complete code and improves both effectiveness and efficiency via three separations: (i) logic revision vs. parameter optimization, (ii) LLM-guided directional search vs. Bayesian hyperparameter search, and (iii) LLM usage vs. local computation. FE further incorporates a knowledge-infused bootstrapping module that transforms unstructured financial reports into executable factor programs through a closed-loop multi-agent extraction-verification-code-generation pipeline, and an experience knowledge base that supports trajectory-aware refinement (including learning from failures). Across extensive backtests on real-world OHLCV data, FE produces factors with substantially stronger predictive stability and portfolio impact-for example, higher IC/ICIR (and Rank IC/ICIR) and improved AR/Sharpe, than baseline methods, achieving state-of-the-art predictive and portfolio performance.
RuCL: Stratified Rubric-Based Curriculum Learning for Multimodal Large Language Model Reasoning
Feb 25, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a prevailing paradigm for enhancing reasoning in Multimodal Large Language Models (MLLMs). However, relying solely on outcome supervision risks reward hacking, where models learn spurious reasoning patterns to satisfy final answer checks. While recent rubric-based approaches offer fine-grained supervision signals, they suffer from high computational costs of instance-level generation and inefficient training dynamics caused by treating all rubrics as equally learnable. In this paper, we propose Stratified Rubric-based Curriculum Learning (RuCL), a novel framework that reformulates curriculum learning by shifting the focus from data selection to reward design. RuCL generates generalized rubrics for broad applicability and stratifies them based on the model's competence. By dynamically adjusting rubric weights during training, RuCL guides the model from mastering foundational perception to tackling advanced logical reasoning. Extensive experiments on various visual reasoning benchmarks show that RuCL yields a remarkable +7.83% average improvement over the Qwen2.5-VL-7B model, achieving a state-of-the-art accuracy of 60.06%.
Towards Cross-lingual Values Assessment: A Consensus-Pluralism Perspective
Feb 19, 2026While large language models (LLMs) have become pivotal to content safety, current evaluation paradigms primarily focus on detecting explicit harms (e.g., violence or hate speech), neglecting the subtler value dimensions conveyed in digital content. To bridge this gap, we introduce X-Value, a novel Cross-lingual Values Assessment Benchmark designed to evaluate LLMs' ability to assess deep-level values of content from a global perspective. X-Value consists of more than 5,000 QA pairs across 18 languages, systematically organized into 7 core domains grounded in Schwartz's Theory of Basic Human Values and categorized into easy and hard levels for discriminative evaluation. We further propose a unique two-stage annotation framework that first identifies whether an issue falls under global consensus (e.g., human rights) or pluralism (e.g., religion), and subsequently conducts a multi-party evaluation of the latent values embedded within the content. Systematic evaluations on X-Value reveal that current SOTA LLMs exhibit deficiencies in cross-lingual values assessment ($Acc < 77\%$), with significant performance disparities across different languages ($ΔAcc > 20\%$). This work highlights the urgent need to improve the nuanced, values-aware content assessment capability of LLMs. Our X-Value is available at: https://huggingface.co/datasets/Whitolf/X-Value.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Spiking Vocos: An Energy-Efficient Neural Vocoder
Sep 16, 2025Despite the remarkable progress in the synthesis speed and fidelity of neural vocoders, their high energy consumption remains a critical barrier to practical deployment on computationally restricted edge devices. Spiking Neural Networks (SNNs), widely recognized for their high energy efficiency due to their event-driven nature, offer a promising solution for low-resource scenarios. In this paper, we propose Spiking Vocos, a novel spiking neural vocoder with ultra-low energy consumption, built upon the efficient Vocos framework. To mitigate the inherent information bottleneck in SNNs, we design a Spiking ConvNeXt module to reduce Multiply-Accumulate (MAC) operations and incorporate an amplitude shortcut path to preserve crucial signal dynamics. Furthermore, to bridge the performance gap with its Artificial Neural Network (ANN) counterpart, we introduce a self-architectural distillation strategy to effectively transfer knowledge. A lightweight Temporal Shift Module is also integrated to enhance the model's ability to fuse information across the temporal dimension with negligible computational overhead. Experiments demonstrate that our model achieves performance comparable to its ANN counterpart, with UTMOS and PESQ scores of 3.74 and 3.45 respectively, while consuming only 14.7% of the energy. The source code is available at https://github.com/pymaster17/Spiking-Vocos.
Training Superior Sparse Autoencoders for Instruct Models
Jun 09, 2025As large language models (LLMs) grow in scale and capability, understanding their internal mechanisms becomes increasingly critical. Sparse autoencoders (SAEs) have emerged as a key tool in mechanistic interpretability, enabling the extraction of human-interpretable features from LLMs. However, existing SAE training methods are primarily designed for base models, resulting in reduced reconstruction quality and interpretability when applied to instruct models. To bridge this gap, we propose $\underline{\textbf{F}}$inetuning-$\underline{\textbf{a}}$ligned $\underline{\textbf{S}}$equential $\underline{\textbf{T}}$raining ($\textit{FAST}$), a novel training method specifically tailored for instruct models. $\textit{FAST}$ aligns the training process with the data distribution and activation patterns characteristic of instruct models, resulting in substantial improvements in both reconstruction and feature interpretability. On Qwen2.5-7B-Instruct, $\textit{FAST}$ achieves a mean squared error of 0.6468 in token reconstruction, significantly outperforming baseline methods with errors of 5.1985 and 1.5096. In feature interpretability, $\textit{FAST}$ yields a higher proportion of high-quality features, for Llama3.2-3B-Instruct, $21.1\%$ scored in the top range, compared to $7.0\%$ and $10.2\%$ for $\textit{BT(P)}$ and $\textit{BT(F)}$. Surprisingly, we discover that intervening on the activations of special tokens via the SAEs leads to improvements in output quality, suggesting new opportunities for fine-grained control of model behavior. Code, data, and 240 trained SAEs are available at https://github.com/Geaming2002/FAST.
StreamRL: Scalable, Heterogeneous, and Elastic RL for LLMs with Disaggregated Stream Generation
Apr 22, 2025Reinforcement learning (RL) has become the core post-training technique for large language models (LLMs). RL for LLMs involves two stages: generation and training. The LLM first generates samples online, which are then used to derive rewards for training. The conventional view holds that the colocated architecture, where the two stages share resources via temporal multiplexing, outperforms the disaggregated architecture, in which dedicated resources are assigned to each stage. However, in real-world deployments, we observe that the colocated architecture suffers from resource coupling, where the two stages are constrained to use the same resources. This coupling compromises the scalability and cost-efficiency of colocated RL in large-scale training. In contrast, the disaggregated architecture allows for flexible resource allocation, supports heterogeneous training setups, and facilitates cross-datacenter deployment. StreamRL is designed with disaggregation from first principles and fully unlocks its potential by addressing two types of performance bottlenecks in existing disaggregated RL frameworks: pipeline bubbles, caused by stage dependencies, and skewness bubbles, resulting from long-tail output length distributions. To address pipeline bubbles, StreamRL breaks the traditional stage boundary in synchronous RL algorithms through stream generation and achieves full overlapping in asynchronous RL. To address skewness bubbles, StreamRL employs an output-length ranker model to identify long-tail samples and reduces generation time via skewness-aware dispatching and scheduling. Experiments show that StreamRL improves throughput by up to 2.66x compared to existing state-of-the-art systems, and improves cost-effectiveness by up to 1.33x in a heterogeneous, cross-datacenter setting.
REFINE: Inversion-Free Backdoor Defense via Model Reprogramming
Feb 22, 2025Backdoor attacks on deep neural networks (DNNs) have emerged as a significant security threat, allowing adversaries to implant hidden malicious behaviors during the model training phase. Pre-processing-based defense, which is one of the most important defense paradigms, typically focuses on input transformations or backdoor trigger inversion (BTI) to deactivate or eliminate embedded backdoor triggers during the inference process. However, these methods suffer from inherent limitations: transformation-based defenses often fail to balance model utility and defense performance, while BTI-based defenses struggle to accurately reconstruct trigger patterns without prior knowledge. In this paper, we propose REFINE, an inversion-free backdoor defense method based on model reprogramming. REFINE consists of two key components: \textbf{(1)} an input transformation module that disrupts both benign and backdoor patterns, generating new benign features; and \textbf{(2)} an output remapping module that redefines the model's output domain to guide the input transformations effectively. By further integrating supervised contrastive loss, REFINE enhances the defense capabilities while maintaining model utility. Extensive experiments on various benchmark datasets demonstrate the effectiveness of our REFINE and its resistance to potential adaptive attacks.
PersonaMath: Enhancing Math Reasoning through Persona-Driven Data Augmentation
Oct 02, 2024


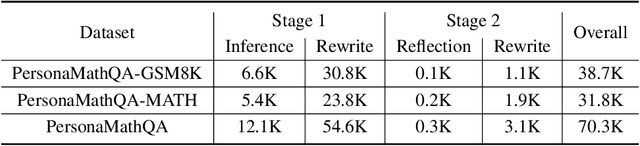
While closed-source Large Language Models (LLMs) demonstrate strong mathematical problem-solving abilities, open-source models continue to struggle with such tasks. To bridge this gap, we propose a data augmentation approach and introduce PersonaMathQA, a dataset derived from MATH and GSM8K, on which we train the PersonaMath models. Our approach consists of two stages: the first stage is learning from Persona Diversification, and the second stage is learning from Reflection. In the first stage, we regenerate detailed chain-of-thought (CoT) solutions as instructions using a closed-source LLM and introduce a novel persona-driven data augmentation technique to enhance the dataset's quantity and diversity. In the second stage, we incorporate reflection to fully leverage more challenging and valuable questions. Evaluation of our PersonaMath models on MATH and GSM8K reveals that the PersonaMath-7B model (based on LLaMA-2-7B) achieves an accuracy of 24.2% on MATH and 68.7% on GSM8K, surpassing all baseline methods and achieving state-of-the-art performance. Notably, our dataset contains only 70.3K data points-merely 17.8% of MetaMathQA and 27% of MathInstruct-yet our model outperforms these baselines, demonstrating the high quality and diversity of our dataset, which enables more efficient model training. We open-source the PersonaMathQA dataset, PersonaMath models, and our code for public usage.
Towards the Better Ranking Consistency: A Multi-task Learning Framework for Early Stage Ads Ranking
Jul 12, 2023



Dividing ads ranking system into retrieval, early, and final stages is a common practice in large scale ads recommendation to balance the efficiency and accuracy. The early stage ranking often uses efficient models to generate candidates out of a set of retrieved ads. The candidates are then fed into a more computationally intensive but accurate final stage ranking system to produce the final ads recommendation. As the early and final stage ranking use different features and model architectures because of system constraints, a serious ranking consistency issue arises where the early stage has a low ads recall, i.e., top ads in the final stage are ranked low in the early stage. In order to pass better ads from the early to the final stage ranking, we propose a multi-task learning framework for early stage ranking to capture multiple final stage ranking components (i.e. ads clicks and ads quality events) and their task relations. With our multi-task learning framework, we can not only achieve serving cost saving from the model consolidation, but also improve the ads recall and ranking consistency. In the online A/B testing, our framework achieves significantly higher click-through rate (CTR), conversion rate (CVR), total value and better ads-quality (e.g. reduced ads cross-out rate) in a large scale industrial ads ranking system.