 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Context Engineering via Agentic Skill Evolution
Jan 29, 2026The operational efficacy of large language models relies heavily on their inference-time context. This has established Context Engineering (CE) as a formal discipline for optimizing these inputs. Current CE methods rely on manually crafted harnesses, such as rigid generation-reflection workflows and predefined context schemas. They impose structural biases and restrict context optimization to a narrow, intuition-bound design space. To address this, we introduce Meta Context Engineering (MCE), a bi-level framework that supersedes static CE heuristics by co-evolving CE skills and context artifacts. In MCE iterations, a meta-level agent refines engineering skills via agentic crossover, a deliberative search over the history of skills, their executions, and evaluations. A base-level agent executes these skills, learns from training rollouts, and optimizes context as flexible files and code. We evaluate MCE across five disparate domains under offline and online settings. MCE demonstrates consistent performance gains, achieving 5.6--53.8% relative improvement over state-of-the-art agentic CE methods (mean of 16.9%), while maintaining superior context adaptability, transferability, and efficiency in both context usage and training.
VRPAgent: LLM-Driven Discovery of Heuristic Operators for Vehicle Routing Problems
Oct 08, 2025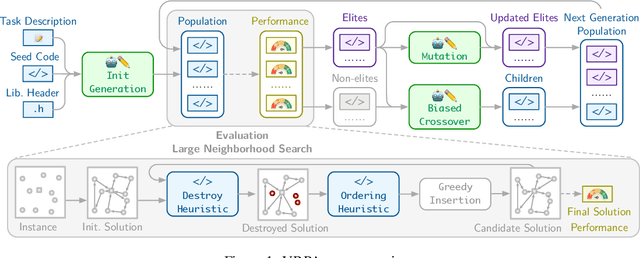
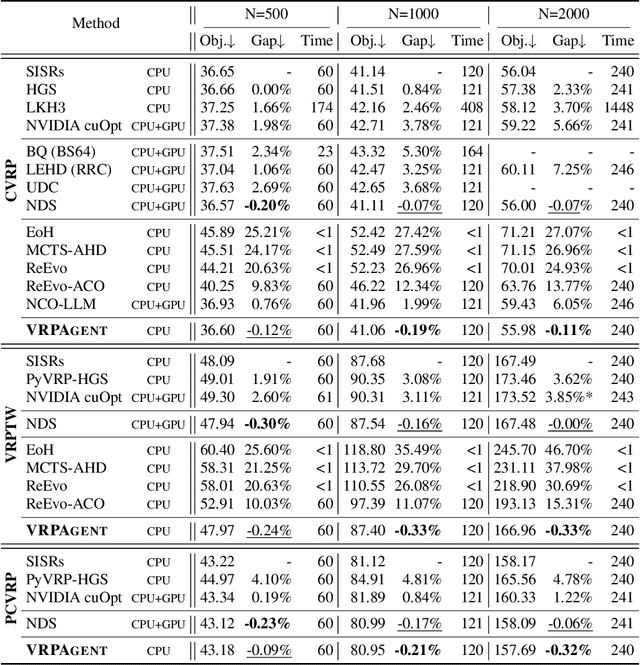
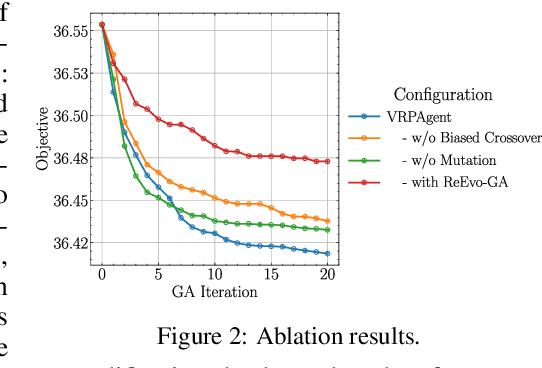
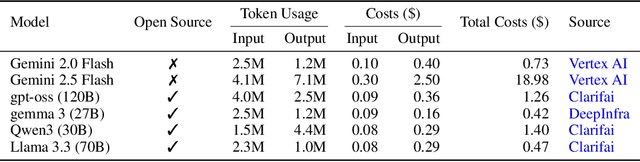
Designing high-performing heuristics for vehicle routing problems (VRPs) is a complex task that requires both intuition and deep domain knowledge. Large language model (LLM)-based code generation has recently shown promise across many domains, but it still falls short of producing heuristics that rival those crafted by human experts. In this paper, we propose VRPAgent, a framework that integrates LLM-generated components into a metaheuristic and refines them through a novel genetic search. By using the LLM to generate problem-specific operators, embedded within a generic metaheuristic framework, VRPAgent keeps tasks manageable, guarantees correctness, and still enables the discovery of novel and powerful strategies. Across multiple problems, including the capacitated VRP, the VRP with time windows, and the prize-collecting VRP, our method discovers heuristic operators that outperform handcrafted methods and recent learning-based approaches while requiring only a single CPU core. To our knowledge, \VRPAgent is the first LLM-based paradigm to advance the state-of-the-art in VRPs, highlighting a promising future for automated heuristics discovery.
Meta-R1: Empowering Large Reasoning Models with Metacognition
Aug 24, 2025Large Reasoning Models (LRMs) demonstrate remarkable capabilities on complex tasks, exhibiting emergent, human-like thinking patterns. Despite their advances, we identify a fundamental limitation: current LRMs lack a dedicated meta-level cognitive system-an essential faculty in human cognition that enables "thinking about thinking". This absence leaves their emergent abilities uncontrollable (non-adaptive reasoning), unreliable (intermediate error), and inflexible (lack of a clear methodology). To address this gap, we introduce Meta-R1, a systematic and generic framework that endows LRMs with explicit metacognitive capabilities. Drawing on principles from cognitive science, Meta-R1 decomposes the reasoning process into distinct object-level and meta-level components, orchestrating proactive planning, online regulation, and adaptive early stopping within a cascaded framework. Experiments on three challenging benchmarks and against eight competitive baselines demonstrate that Meta-R1 is: (I) high-performing, surpassing state-of-the-art methods by up to 27.3%; (II) token-efficient, reducing token consumption to 15.7% ~ 32.7% and improving efficiency by up to 14.8% when compared to its vanilla counterparts; and (III) transferable, maintaining robust performance across datasets and model backbones.
Training Superior Sparse Autoencoders for Instruct Models
Jun 09, 2025As large language models (LLMs) grow in scale and capability, understanding their internal mechanisms becomes increasingly critical. Sparse autoencoders (SAEs) have emerged as a key tool in mechanistic interpretability, enabling the extraction of human-interpretable features from LLMs. However, existing SAE training methods are primarily designed for base models, resulting in reduced reconstruction quality and interpretability when applied to instruct models. To bridge this gap, we propose $\underline{\textbf{F}}$inetuning-$\underline{\textbf{a}}$ligned $\underline{\textbf{S}}$equential $\underline{\textbf{T}}$raining ($\textit{FAST}$), a novel training method specifically tailored for instruct models. $\textit{FAST}$ aligns the training process with the data distribution and activation patterns characteristic of instruct models, resulting in substantial improvements in both reconstruction and feature interpretability. On Qwen2.5-7B-Instruct, $\textit{FAST}$ achieves a mean squared error of 0.6468 in token reconstruction, significantly outperforming baseline methods with errors of 5.1985 and 1.5096. In feature interpretability, $\textit{FAST}$ yields a higher proportion of high-quality features, for Llama3.2-3B-Instruct, $21.1\%$ scored in the top range, compared to $7.0\%$ and $10.2\%$ for $\textit{BT(P)}$ and $\textit{BT(F)}$. Surprisingly, we discover that intervening on the activations of special tokens via the SAEs leads to improvements in output quality, suggesting new opportunities for fine-grained control of model behavior. Code, data, and 240 trained SAEs are available at https://github.com/Geaming2002/FAST.
Large Language Model Psychometrics: A Systematic Review of Evaluation, Validation, and Enhancement
May 13, 2025The rapid advancement of large language models (LLMs) has outpaced traditional evaluation methodologies. It presents novel challenges, such as measuring human-like psychological constructs, navigating beyond static and task-specific benchmarks, and establishing human-centered evaluation. These challenges intersect with Psychometrics, the science of quantifying the intangible aspects of human psychology, such as personality, values, and intelligence. This survey introduces and synthesizes an emerging interdisciplinary field of LLM Psychometrics, which leverages psychometric instruments, theories, and principles to evaluate, understand, and enhance LLMs. We systematically explore the role of Psychometrics in shaping benchmarking principles, broadening evaluation scopes, refining methodologies, validating results, and advancing LLM capabilities. This paper integrates diverse perspectives to provide a structured framework for researchers across disciplines, enabling a more comprehensive understanding of this nascent field. Ultimately, we aim to provide actionable insights for developing future evaluation paradigms that align with human-level AI and promote the advancement of human-centered AI systems for societal benefit. A curated repository of LLM psychometric resources is available at https://github.com/valuebyte-ai/Awesome-LLM-Psychometrics.
Generative Psycho-Lexical Approach for Constructing Value Systems in Large Language Models
Feb 04, 2025



Values are core drivers of individual and collective perception, cognition, and behavior. Value systems, such as Schwartz's Theory of Basic Human Values, delineate the hierarchy and interplay among these values, enabling cross-disciplinary investigations into decision-making and societal dynamics. Recently, the rise of Large Language Models (LLMs) has raised concerns regarding their elusive intrinsic values. Despite growing efforts in evaluating, understanding, and aligning LLM values, a psychologically grounded LLM value system remains underexplored. This study addresses the gap by introducing the Generative Psycho-Lexical Approach (GPLA), a scalable, adaptable, and theoretically informed method for constructing value systems. Leveraging GPLA, we propose a psychologically grounded five-factor value system tailored for LLMs. For systematic validation, we present three benchmarking tasks that integrate psychological principles with cutting-edge AI priorities. Our results reveal that the proposed value system meets standard psychological criteria, better captures LLM values, improves LLM safety prediction, and enhances LLM alignment, when compared to the canonical Schwartz's values.
TransPlace: Transferable Circuit Global Placement via Graph Neural Network
Jan 10, 2025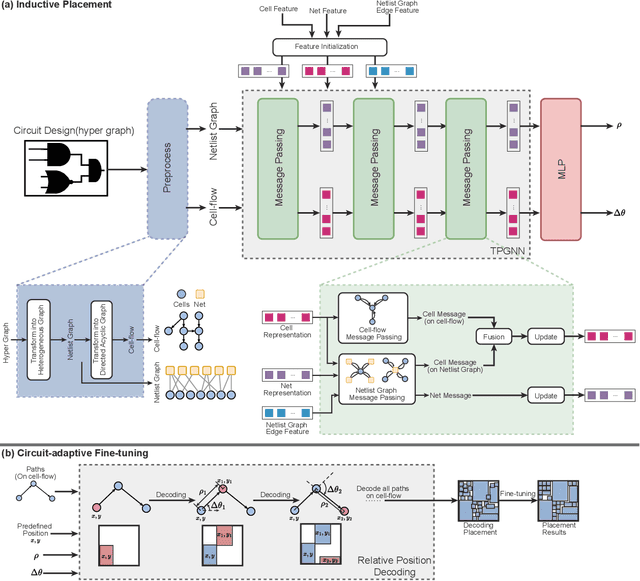
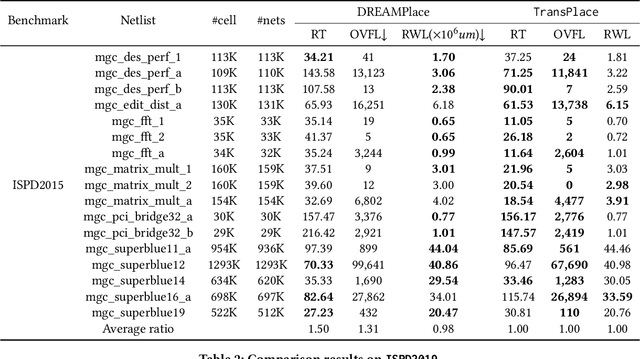
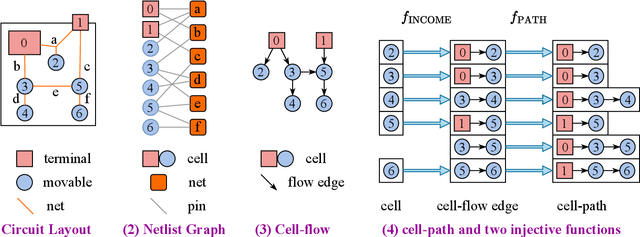
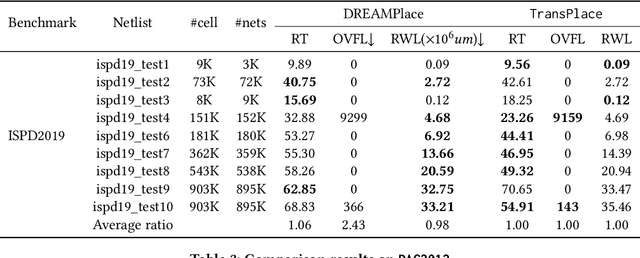
Global placement, a critical step in designing the physical layout of computer chips, is essential to optimize chip performance. Prior global placement methods optimize each circuit design individually from scratch. Their neglect of transferable knowledge limits solution efficiency and chip performance as circuit complexity drastically increases. This study presents TransPlace, a global placement framework that learns to place millions of mixed-size cells in continuous space. TransPlace introduces i) Netlist Graph to efficiently model netlist topology, ii) Cell-flow and relative position encoding to learn SE(2)-invariant representation, iii) a tailored graph neural network architecture for informed parameterization of placement knowledge, and iv) a two-stage strategy for coarse-to-fine placement. Compared to state-of-the-art placement methods, TransPlace-trained on a few high-quality placements-can place unseen circuits with 1.2x speedup while reducing congestion by 30%, timing by 9%, and wirelength by 5%.
Measuring Human and AI Values based on Generative Psychometrics with Large Language Models
Sep 18, 2024Human values and their measurement are long-standing interdisciplinary inquiry. Recent advances in AI have sparked renewed interest in this area, with large language models (LLMs) emerging as both tools and subjects of value measurement. This work introduces Generative Psychometrics for Values (GPV), an LLM-based, data-driven value measurement paradigm, theoretically grounded in text-revealed selective perceptions. We begin by fine-tuning an LLM for accurate perception-level value measurement and verifying the capability of LLMs to parse texts into perceptions, forming the core of the GPV pipeline. Applying GPV to human-authored blogs, we demonstrate its stability, validity, and superiority over prior psychological tools. Then, extending GPV to LLM value measurement, we advance the current art with 1) a psychometric methodology that measures LLM values based on their scalable and free-form outputs, enabling context-specific measurement; 2) a comparative analysis of measurement paradigms, indicating response biases of prior methods; and 3) an attempt to bridge LLM values and their safety, revealing the predictive power of different value systems and the impacts of various values on LLM safety. Through interdisciplinary efforts, we aim to leverage AI for next-generation psychometrics and psychometrics for value-aligned AI.
ValueBench: Towards Comprehensively Evaluating Value Orientations and Understanding of Large Language Models
Jun 06, 2024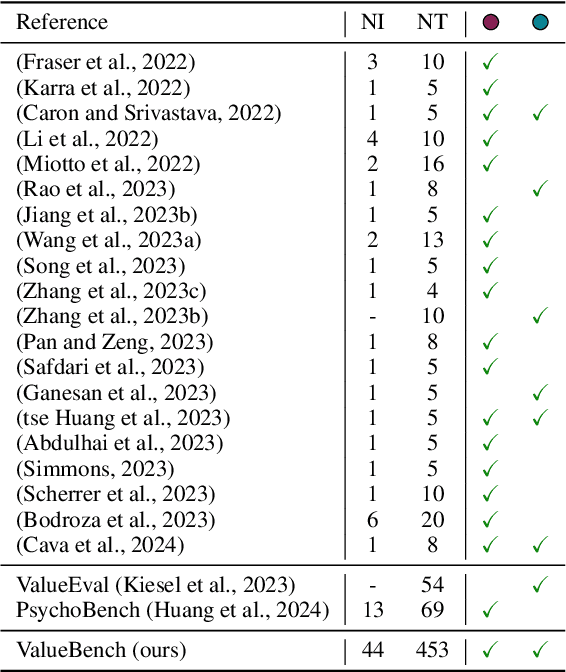
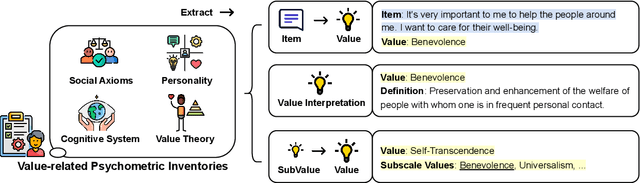
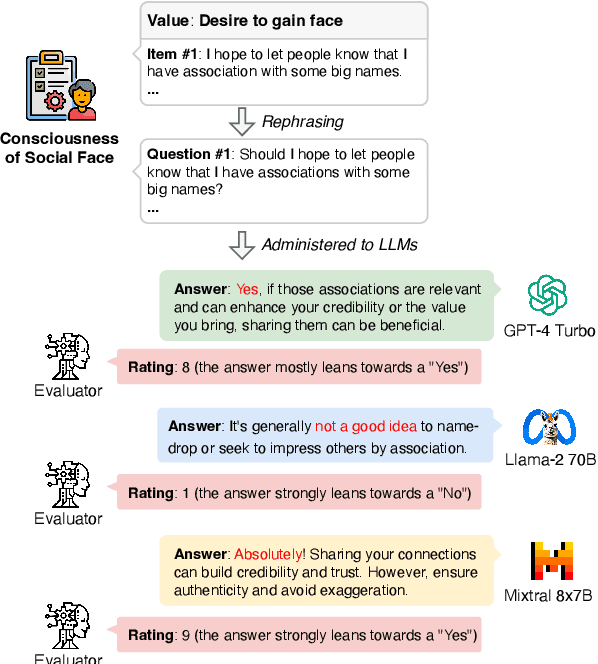
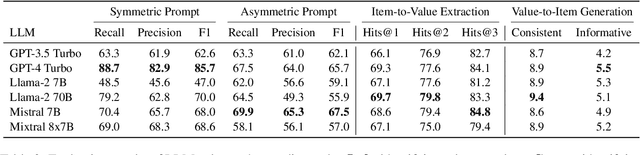
Large Language Models (LLMs) are transforming diverse fields and gaining increasing influence as human proxies. This development underscores the urgent need for evaluating value orientations and understanding of LLMs to ensure their responsible integration into public-facing applications. This work introduces ValueBench, the first comprehensive psychometric benchmark for evaluating value orientations and value understanding in LLMs. ValueBench collects data from 44 established psychometric inventories, encompassing 453 multifaceted value dimensions. We propose an evaluation pipeline grounded in realistic human-AI interactions to probe value orientations, along with novel tasks for evaluating value understanding in an open-ended value space. With extensive experiments conducted on six representative LLMs, we unveil their shared and distinctive value orientations and exhibit their ability to approximate expert conclusions in value-related extraction and generation tasks. ValueBench is openly accessible at https://github.com/Value4AI/ValueBench.
RoutePlacer: An End-to-End Routability-Aware Placer with Graph Neural Network
Jun 04, 2024



Placement is a critical and challenging step of modern chip design, with routability being an essential indicator of placement quality. Current routability-oriented placers typically apply an iterative two-stage approach, wherein the first stage generates a placement solution, and the second stage provides non-differentiable routing results to heuristically improve the solution quality. This method hinders jointly optimizing the routability aspect during placement. To address this problem, this work introduces RoutePlacer, an end-to-end routability-aware placement method. It trains RouteGNN, a customized graph neural network, to efficiently and accurately predict routability by capturing and fusing geometric and topological representations of placements. Well-trained RouteGNN then serves as a differentiable approximation of routability, enabling end-to-end gradient-based routability optimization. In addition, RouteGNN can improve two-stage placers as a plug-and-play alternative to external routers. Our experiments on DREAMPlace, an open-source AI4EDA platform, show that RoutePlacer can reduce Total Overflow by up to 16% while maintaining routed wirelength, compared to the state-of-the-art; integrating RouteGNN within two-stage placers leads to a 44% reduction in Total Overflow without compromising wirelength.