 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Task-aware Contrastive Local Descriptor Selection Strategy for Few-shot Learning between inter class and intra class
Aug 12, 2024Few-shot image classification aims to classify novel classes with few labeled samples. Recent research indicates that deep local descriptors have better representational capabilities. These studies recognize the impact of background noise on classification performance. They typically filter query descriptors using all local descriptors in the support classes or engage in bidirectional selection between local descriptors in support and query sets. However, they ignore the fact that background features may be useful for the classification performance of specific tasks. This paper proposes a novel task-aware contrastive local descriptor selection network (TCDSNet). First, we calculate the contrastive discriminative score for each local descriptor in the support class, and select discriminative local descriptors to form a support descriptor subset. Finally, we leverage support descriptor subsets to adaptively select discriminative query descriptors for specific tasks. Extensive experiments demonstrate that our method outperforms state-of-the-art methods on both general and fine-grained datasets.
FreeStyle: Free Lunch for Text-guided Style Transfer using Diffusion Models
Jan 28, 2024The rapid development of generative diffusion models has significantly advanced the field of style transfer. However, most current style transfer methods based on diffusion models typically involve a slow iterative optimization process, e.g., model fine-tuning and textual inversion of style concept. In this paper, we introduce FreeStyle, an innovative style transfer method built upon a pre-trained large diffusion model, requiring no further optimization. Besides, our method enables style transfer only through a text description of the desired style, eliminating the necessity of style images. Specifically, we propose a dual-stream encoder and single-stream decoder architecture, replacing the conventional U-Net in diffusion models. In the dual-stream encoder, two distinct branches take the content image and style text prompt as inputs, achieving content and style decoupling. In the decoder, we further modulate features from the dual streams based on a given content image and the corresponding style text prompt for precise style transfer. Our experimental results demonstrate high-quality synthesis and fidelity of our method across various content images and style text prompts. The code and more results are available at our project website:https://freestylefreelunch.github.io/.
GLOP: Learning Global Partition and Local Construction for Solving Large-scale Routing Problems in Real-time
Dec 13, 2023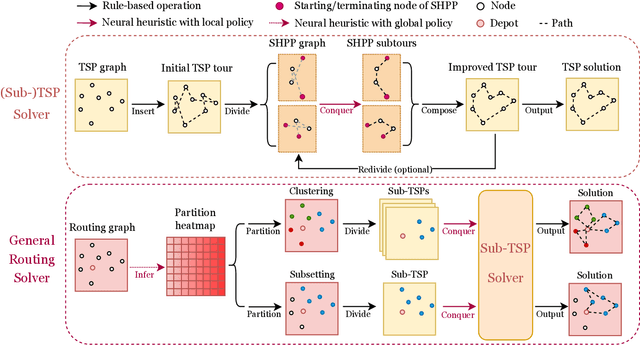
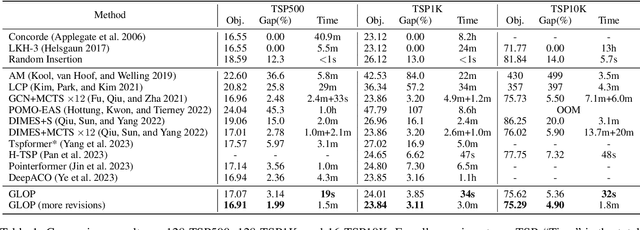
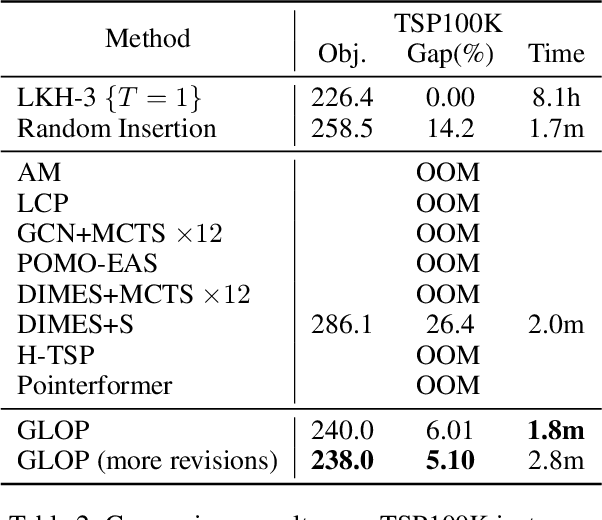
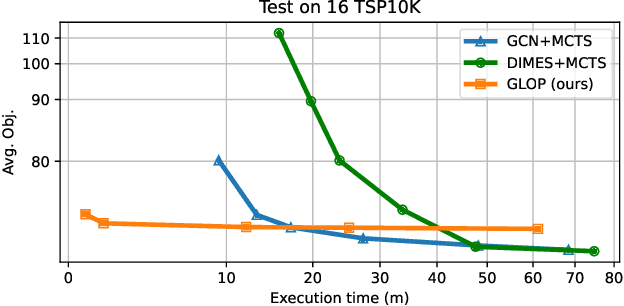
The recent end-to-end neural solvers have shown promise for small-scale routing problems but suffered from limited real-time scaling-up performance. This paper proposes GLOP (Global and Local Optimization Policies), a unified hierarchical framework that efficiently scales toward large-scale routing problems. GLOP partitions large routing problems into Travelling Salesman Problems (TSPs) and TSPs into Shortest Hamiltonian Path Problems. For the first time, we hybridize non-autoregressive neural heuristics for coarse-grained problem partitions and autoregressive neural heuristics for fine-grained route constructions, leveraging the scalability of the former and the meticulousness of the latter. Experimental results show that GLOP achieves competitive and state-of-the-art real-time performance on large-scale routing problems, including TSP, ATSP, CVRP, and PCTSP.
TALDS-Net: Task-Aware Adaptive Local Descriptors Selection for Few-shot Image Classification
Dec 09, 2023Few-shot image classification aims to classify images from unseen novel classes with few samples. Recent works demonstrate that deep local descriptors exhibit enhanced representational capabilities compared to image-level features. However, most existing methods solely rely on either employing all local descriptors or directly utilizing partial descriptors, potentially resulting in the loss of crucial information. Moreover, these methods primarily emphasize the selection of query descriptors while overlooking support descriptors. In this paper, we propose a novel Task-Aware Adaptive Local Descriptors Selection Network (TALDS-Net), which exhibits the capacity for adaptive selection of task-aware support descriptors and query descriptors. Specifically, we compare the similarity of each local support descriptor with other local support descriptors to obtain the optimal support descriptor subset and then compare the query descriptors with the optimal support subset to obtain discriminative query descriptors. Extensive experiments demonstrate that our TALDS-Net outperforms state-of-the-art methods on both general and fine-grained datasets.
PrototypeFormer: Learning to Explore Prototype Relationships for Few-shot Image Classification
Oct 05, 2023Few-shot image classification has received considerable attention for addressing the challenge of poor classification performance with limited samples in novel classes. However, numerous studies have employed sophisticated learning strategies and diversified feature extraction methods to address this issue. In this paper, we propose our method called PrototypeFormer, which aims to significantly advance traditional few-shot image classification approaches by exploring prototype relationships. Specifically, we utilize a transformer architecture to build a prototype extraction module, aiming to extract class representations that are more discriminative for few-shot classification. Additionally, during the model training process, we propose a contrastive learning-based optimization approach to optimize prototype features in few-shot learning scenarios. Despite its simplicity, the method performs remarkably well, with no bells and whistles. We have experimented with our approach on several popular few-shot image classification benchmark datasets, which shows that our method outperforms all current state-of-the-art methods. In particular, our method achieves 97.07% and 90.88% on 5-way 5-shot and 5-way 1-shot tasks of miniImageNet, which surpasses the state-of-the-art results with accuracy of 7.27% and 8.72%, respectively. The code will be released later.
Cartoondiff: Training-free Cartoon Image Generation with Diffusion Transformer Models
Sep 15, 2023



Image cartoonization has attracted significant interest in the field of image generation. However, most of the existing image cartoonization techniques require re-training models using images of cartoon style. In this paper, we present CartoonDiff, a novel training-free sampling approach which generates image cartoonization using diffusion transformer models. Specifically, we decompose the reverse process of diffusion models into the semantic generation phase and the detail generation phase. Furthermore, we implement the image cartoonization process by normalizing high-frequency signal of the noisy image in specific denoising steps. CartoonDiff doesn't require any additional reference images, complex model designs, or the tedious adjustment of multiple parameters. Extensive experimental results show the powerful ability of our CartoonDiff. The project page is available at: https://cartoondiff.github.io/
Jointly Learning Structured Analysis Discriminative Dictionary and Analysis Multiclass Classifier
May 27, 2019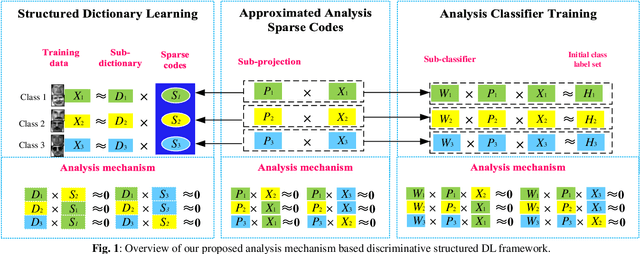
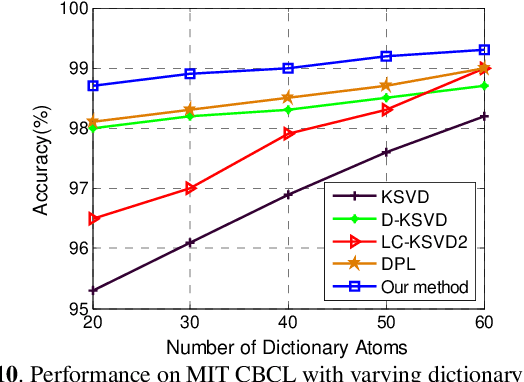
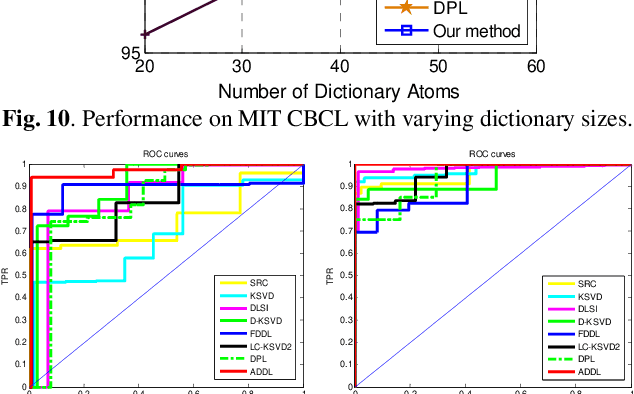

In this paper, we propose an analysis mechanism based structured Analysis Discriminative Dictionary Learning (ADDL) framework. ADDL seamlessly integrates the analysis discriminative dictionary learning, analysis representation and analysis classifier training into a unified model. The applied analysis mechanism can make sure that the learnt dictionaries, representations and linear classifiers over different classes are independent and discriminating as much as possible. The dictionary is obtained by minimizing a reconstruction error and an analytical incoherence promoting term that encourages the sub-dictionaries associated with different classes to be independent. To obtain the representation coefficients, ADDL imposes a sparse l2,1-norm constraint on the coding coefficients instead of using l0 or l1-norm, since the l0 or l1-norm constraint applied in most existing DL criteria makes the training phase time consuming. The codes-extraction projection that bridges data with the sparse codes by extracting special features from the given samples is calculated via minimizing a sparse codes approximation term. Then we compute a linear classifier based on the approximated sparse codes by an analysis mechanism to simultaneously consider the classification and representation powers. Thus, the classification approach of our model is very efficient, because it can avoid the extra time-consuming sparse reconstruction process with trained dictionary for each new test data as most existing DL algorithms. Simulations on real image databases demonstrate that our ADDL model can obtain superior performance over other state-of-the-arts.