 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Clinical Knowledge Integration for Mammography Report Generation
May 29, 2026Breast cancer is a major global health concern, and mammography screening plays a central role in early detection. The large volume of screening examinations creates a substantial workload for radiologists, making accurate and consistent report generation a critical clinical challenge. Existing automated mammography report generation methods primarily focus on direct visual-to-text mapping, while overlooking the structured clinical reasoning process followed by radiologists in real-world practice. To address this limitation, we propose MammoRG, a mammography report generation framework that explicitly simulates the clinical reporting workflow by following the BI-RADS guideline and incorporating prior clinical knowledge to produce diagnostic reports. Specifically, MammoRG adopts a two-stage training framework. In the first stage, the model learns to integrate clinically relevant prior knowledge from a patient's four-view mammograms through classification-based supervision. In the second stage, a terminology-aware supervised fine-tuning strategy is introduced to model mammography-specific clinical terms as atomic semantic units, enabling the generation of high-quality reports with improved clinical consistency. To facilitate clinical efficacy evaluation of generated reports, we further develop MammoRGTool, a dedicated mammography report parsing tool that extracts structured clinical information from free-text reports. Extensive experiments demonstrate that MammoRG consistently outperforms existing methods across multiple clinical efficacy metrics, particularly in diagnosis-related BI-RADS F1, where it surpasses the second-best model by 2.73%, 2.04%, 1.90%, and 3.27% on the internal, external 1, external 2, and VinDr-Mammo datasets, respectively.
SafeCtrl: Region-Aware Safety Control for Text-to-Image Diffusion via Detect-Then-Suppress
Apr 05, 2026The widespread deployment of text-to-image diffusion models is significantly challenged by the generation of visually harmful content, such as sexually explicit content, violence, and horror imagery. Common safety interventions, ranging from input filtering to model concept erasure, often suffer from two critical limitations: (1) a severe trade-off between safety and context preservation, where removing unsafe concepts degrades the fidelity of the safe content, and (2) vulnerability to adversarial attacks, where safety mechanisms are easily bypassed. To address these challenges, we propose SafeCtrl, a Region-Aware safety control framework operating on a Detect-Then-Suppress paradigm. Unlike global safety interventions, SafeCtrl first employs an attention-guided Detect module to precisely localize specific risk regions. Subsequently, a localized Suppress module, optimized via image-level Direct Preference Optimization (DPO), neutralizes harmful semantics only within the detected areas, effectively transforming unsafe objects into safe alternatives while leaving the surrounding context intact. Extensive experiments across multiple risk categories demonstrate that SafeCtrl achieves a superior trade-off between safety and fidelity compared to state-of-the-art methods. Crucially, our approach exhibits improved resilience against adversarial prompt attacks, offering a precise and robust solution for responsible generation.
IdentityGuard: Context-Aware Restriction and Provenance for Personalized Synthesis
Mar 14, 2026The nature of personalized text-to-image models poses a unique safety challenge that generic context-blind methods are ill-equipped to handle. Such global filters create a dilemma: to prevent misuse, they are forced to damage the model's broader utility by erasing concepts entirely, causing unacceptable collateral damage.Our work presents a more precisely targeted approach, built on the principle that security should be as context-aware as the threat itself, intrinsically bound to the personalized concept. We present IDENTITYGUARD, which realizes this principle through a conditional restriction that blocks harmful content only when combined with the personalized identity, and a concept-specific watermark for precise traceability. Experiments show our approach prevents misuse while preserving the model's utility and enabling robust traceability. By moving beyond blunt, global filters, our work demonstrates a more effective and responsible path toward AI safety.
Enhanced Diffusion Sampling: Efficient Rare Event Sampling and Free Energy Calculation with Diffusion Models
Feb 18, 2026The rare-event sampling problem has long been the central limiting factor in molecular dynamics (MD), especially in biomolecular simulation. Recently, diffusion models such as BioEmu have emerged as powerful equilibrium samplers that generate independent samples from complex molecular distributions, eliminating the cost of sampling rare transition events. However, a sampling problem remains when computing observables that rely on states which are rare in equilibrium, for example folding free energies. Here, we introduce enhanced diffusion sampling, enabling efficient exploration of rare-event regions while preserving unbiased thermodynamic estimators. The key idea is to perform quantitatively accurate steering protocols to generate biased ensembles and subsequently recover equilibrium statistics via exact reweighting. We instantiate our framework in three algorithms: UmbrellaDiff (umbrella sampling with diffusion models), $Δ$G-Diff (free-energy differences via tilted ensembles), and MetaDiff (a batchwise analogue for metadynamics). Across toy systems, protein folding landscapes and folding free energies, our methods achieve fast, accurate, and scalable estimation of equilibrium properties within GPU-minutes to hours per system -- closing the rare-event sampling gap that remained after the advent of diffusion-model equilibrium samplers.
SAGE: Sequence-level Adaptive Gradient Evolution for Generative Recommendation
Jan 29, 2026While works such as OneRec have validated the scaling laws of Large Language Models (LLMs) in recommender systems, they rely on a cumbersome separate vocabulary. This dependency prevents the model architecture from reusing native LLM vocabularies, resulting in high maintenance costs and poor scalability. In response, we aim to efficiently reuse open-source LLM architectures without constructing a separate tokenization vocabulary. Furthermore, we identify that the optimization strategy of OneRec Gradient Bounded Policy Optimization (GBPO),suffers from a "Symmetric Conservatism" problem: its static gradient boundaries structurally suppress the update momentum required for cold-start items and fail to prevent diversity collapse in high-noise environments.To address this issue, we propose SAGE (Sequence-level Adaptive Gradient Evolution), a unified optimization framework tailored for list-wise generative recommendation. SAGE introduces two key innovations:(1) Sequence-level Signal Decoupling: By combining a geometric mean importance ratio with decoupled multi-objective advantages, we eliminate token-level variance and resolve the "Reward Collapse" problem. (2) Asymmetric Adaptive Dynamics: We construct a dynamic gradient manifold that applies a "Boost Factor" to high-potential cold start items to achieve super-linear updates and employs an "Entropy Aware Penalty" to break information cocoons. Theoretical analysis and empirical results demonstrate that SAGE effectively unblocks cold-start traffic and sustains recommendation diversity, all while retaining the numerical stability of GBPO.
RecLLM-R1: A Two-Stage Training Paradigm with Reinforcement Learning and Chain-of-Thought v1
Jun 24, 2025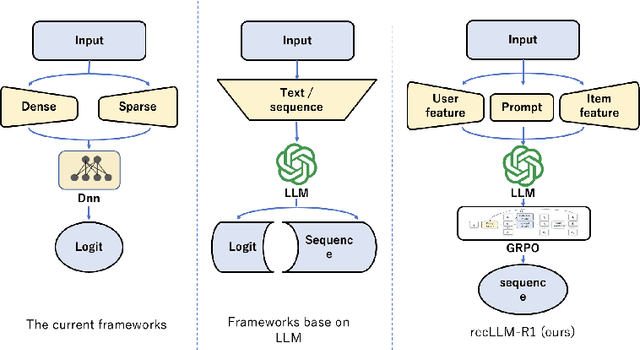



Traditional recommendation systems often grapple with "filter bubbles", underutilization of external knowledge, and a disconnect between model optimization and business policy iteration. To address these limitations, this paper introduces RecLLM-R1, a novel recommendation framework leveraging Large Language Models (LLMs) and drawing inspiration from the DeepSeek R1 methodology. The framework initiates by transforming user profiles, historical interactions, and multi-faceted item attributes into LLM-interpretable natural language prompts through a carefully engineered data construction process. Subsequently, a two-stage training paradigm is employed: the initial stage involves Supervised Fine-Tuning (SFT) to imbue the LLM with fundamental recommendation capabilities. The subsequent stage utilizes Group Relative Policy Optimization (GRPO), a reinforcement learning technique, augmented with a Chain-of-Thought (CoT) mechanism. This stage guides the model through multi-step reasoning and holistic decision-making via a flexibly defined reward function, aiming to concurrently optimize recommendation accuracy, diversity, and other bespoke business objectives. Empirical evaluations on a real-world user behavior dataset from a large-scale social media platform demonstrate that RecLLM-R1 significantly surpasses existing baseline methods across a spectrum of evaluation metrics, including accuracy, diversity, and novelty. It effectively mitigates the filter bubble effect and presents a promising avenue for the integrated optimization of recommendation models and policies under intricate business goals.
Coupled reaction and diffusion governing interface evolution in solid-state batteries
Jun 12, 2025Understanding and controlling the atomistic-level reactions governing the formation of the solid-electrolyte interphase (SEI) is crucial for the viability of next-generation solid state batteries. However, challenges persist due to difficulties in experimentally characterizing buried interfaces and limits in simulation speed and accuracy. We conduct large-scale explicit reactive simulations with quantum accuracy for a symmetric battery cell, {\symcell}, enabled by active learning and deep equivariant neural network interatomic potentials. To automatically characterize the coupled reactions and interdiffusion at the interface, we formulate and use unsupervised classification techniques based on clustering in the space of local atomic environments. Our analysis reveals the formation of a previously unreported crystalline disordered phase, Li$_2$S$_{0.72}$P$_{0.14}$Cl$_{0.14}$, in the SEI, that evaded previous predictions based purely on thermodynamics, underscoring the importance of explicit modeling of full reaction and transport kinetics. Our simulations agree with and explain experimental observations of the SEI formations and elucidate the Li creep mechanisms, critical to dendrite initiation, characterized by significant Li motion along the interface. Our approach is to crease a digital twin from first principles, without adjustable parameters fitted to experiment. As such, it offers capabilities to gain insights into atomistic dynamics governing complex heterogeneous processes in solid-state synthesis and electrochemistry.
TextFlux: An OCR-Free DiT Model for High-Fidelity Multilingual Scene Text Synthesis
May 23, 2025


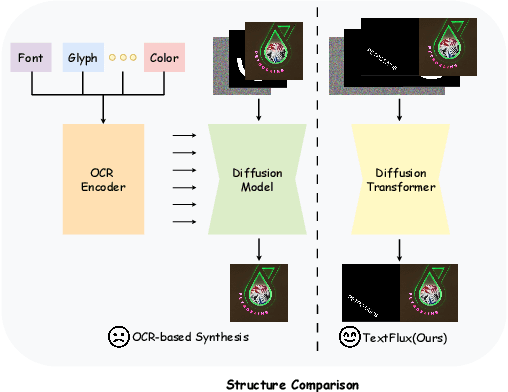
Diffusion-based scene text synthesis has progressed rapidly, yet existing methods commonly rely on additional visual conditioning modules and require large-scale annotated data to support multilingual generation. In this work, we revisit the necessity of complex auxiliary modules and further explore an approach that simultaneously ensures glyph accuracy and achieves high-fidelity scene integration, by leveraging diffusion models' inherent capabilities for contextual reasoning. To this end, we introduce TextFlux, a DiT-based framework that enables multilingual scene text synthesis. The advantages of TextFlux can be summarized as follows: (1) OCR-free model architecture. TextFlux eliminates the need for OCR encoders (additional visual conditioning modules) that are specifically used to extract visual text-related features. (2) Strong multilingual scalability. TextFlux is effective in low-resource multilingual settings, and achieves strong performance in newly added languages with fewer than 1,000 samples. (3) Streamlined training setup. TextFlux is trained with only 1% of the training data required by competing methods. (4) Controllable multi-line text generation. TextFlux offers flexible multi-line synthesis with precise line-level control, outperforming methods restricted to single-line or rigid layouts. Extensive experiments and visualizations demonstrate that TextFlux outperforms previous methods in both qualitative and quantitative evaluations.
Enhancing the Efficiency of Complex Systems Crystal Structure Prediction by Active Learning Guided Machine Learning Potential
May 13, 2025Understanding multicomponent complex material systems is essential for design of advanced materials for a wide range of technological applications. While state-of-the-art crystal structure prediction (CSP) methods effectively identify new structures and assess phase stability, they face fundamental limitations when applied to complex systems. This challenge stems from the combinatorial explosion of atomic configurations and the vast stoichiometric space, both of which contribute to computational demands that rapidly exceed practical feasibility. In this work, we propose a flexible and automated workflow to build a highly generalizable and data-efficient machine learning potential (MLP), effectively unlocking the full potential of CSP algorithms. The workflow is validated on both Mg-Ca-H ternary and Be-P-N-O quaternary systems, demonstrating substantial machine learning acceleration in high-throughput structural optimization and enabling the efficient identification of promising compounds. These results underscore the effectiveness of our approach in exploring complex material systems and accelerating the discovery of new multicomponent materials.
UniGenX: Unified Generation of Sequence and Structure with Autoregressive Diffusion
Mar 09, 2025Unified generation of sequence and structure for scientific data (e.g., materials, molecules, proteins) is a critical task. Existing approaches primarily rely on either autoregressive sequence models or diffusion models, each offering distinct advantages and facing notable limitations. Autoregressive models, such as GPT, Llama, and Phi-4, have demonstrated remarkable success in natural language generation and have been extended to multimodal tasks (e.g., image, video, and audio) using advanced encoders like VQ-VAE to represent complex modalities as discrete sequences. However, their direct application to scientific domains is challenging due to the high precision requirements and the diverse nature of scientific data. On the other hand, diffusion models excel at generating high-dimensional scientific data, such as protein, molecule, and material structures, with remarkable accuracy. Yet, their inability to effectively model sequences limits their potential as general-purpose multimodal foundation models. To address these challenges, we propose UniGenX, a unified framework that combines autoregressive next-token prediction with conditional diffusion models. This integration leverages the strengths of autoregressive models to ease the training of conditional diffusion models, while diffusion-based generative heads enhance the precision of autoregressive predictions. We validate the effectiveness of UniGenX on material and small molecule generation tasks, achieving a significant leap in state-of-the-art performance for material crystal structure prediction and establishing new state-of-the-art results for small molecule structure prediction, de novo design, and conditional generation. Notably, UniGenX demonstrates significant improvements, especially in handling long sequences for complex structures, showcasing its efficacy as a versatile tool for scientific data generation.