 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing the Efficiency of Complex Systems Crystal Structure Prediction by Active Learning Guided Machine Learning Potential
May 13, 2025Understanding multicomponent complex material systems is essential for design of advanced materials for a wide range of technological applications. While state-of-the-art crystal structure prediction (CSP) methods effectively identify new structures and assess phase stability, they face fundamental limitations when applied to complex systems. This challenge stems from the combinatorial explosion of atomic configurations and the vast stoichiometric space, both of which contribute to computational demands that rapidly exceed practical feasibility. In this work, we propose a flexible and automated workflow to build a highly generalizable and data-efficient machine learning potential (MLP), effectively unlocking the full potential of CSP algorithms. The workflow is validated on both Mg-Ca-H ternary and Be-P-N-O quaternary systems, demonstrating substantial machine learning acceleration in high-throughput structural optimization and enabling the efficient identification of promising compounds. These results underscore the effectiveness of our approach in exploring complex material systems and accelerating the discovery of new multicomponent materials.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
Intrinsic Saliency Guided Trunk-Collateral Network for Unsupervised Video Object Segmentation
Apr 08, 2025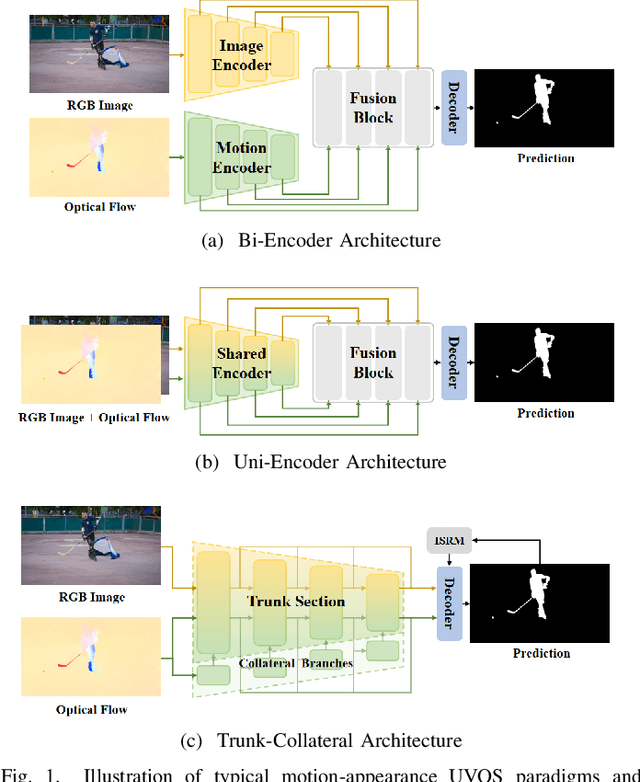

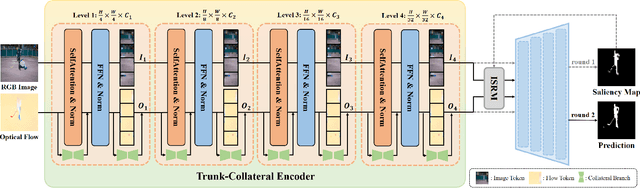
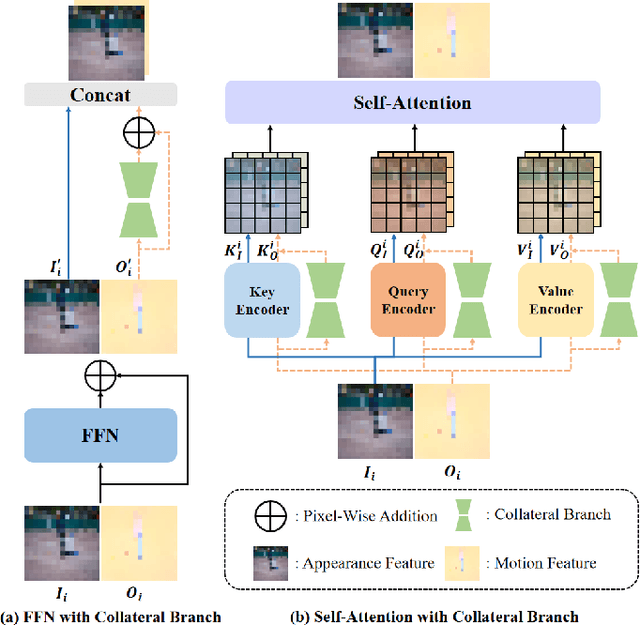
Recent unsupervised video object segmentation (UVOS) methods predominantly adopt the motion-appearance paradigm. Mainstream motion-appearance approaches use either the two-encoder structure to separately encode motion and appearance features, or the single-encoder structure for joint encoding. However, these methods fail to properly balance the motion-appearance relationship. Consequently, even with complex fusion modules for motion-appearance integration, the extracted suboptimal features degrade the models' overall performance. Moreover, the quality of optical flow varies across scenarios, making it insufficient to rely solely on optical flow to achieve high-quality segmentation results. To address these challenges, we propose the Intrinsic Saliency guided Trunk-Collateral Net}work (ISTC-Net), which better balances the motion-appearance relationship and incorporates model's intrinsic saliency information to enhance segmentation performance. Specifically, considering that optical flow maps are derived from RGB images, they share both commonalities and differences. We propose a novel Trunk-Collateral structure. The shared trunk backbone captures the motion-appearance commonality, while the collateral branch learns the uniqueness of motion features. Furthermore, an Intrinsic Saliency guided Refinement Module (ISRM) is devised to efficiently leverage the model's intrinsic saliency information to refine high-level features, and provide pixel-level guidance for motion-appearance fusion, thereby enhancing performance without additional input. Experimental results show that ISTC-Net achieved state-of-the-art performance on three UVOS datasets (89.2% J&F on DAVIS-16, 76% J on YouTube-Objects, 86.4% J on FBMS) and four standard video salient object detection (VSOD) benchmarks with the notable increase, demonstrating its effectiveness and superiority over previous methods.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
OneVOS: Unifying Video Object Segmentation with All-in-One Transformer Framework
Mar 13, 2024Contemporary Video Object Segmentation (VOS) approaches typically consist stages of feature extraction, matching, memory management, and multiple objects aggregation. Recent advanced models either employ a discrete modeling for these components in a sequential manner, or optimize a combined pipeline through substructure aggregation. However, these existing explicit staged approaches prevent the VOS framework from being optimized as a unified whole, leading to the limited capacity and suboptimal performance in tackling complex videos. In this paper, we propose OneVOS, a novel framework that unifies the core components of VOS with All-in-One Transformer. Specifically, to unify all aforementioned modules into a vision transformer, we model all the features of frames, masks and memory for multiple objects as transformer tokens, and integrally accomplish feature extraction, matching and memory management of multiple objects through the flexible attention mechanism. Furthermore, a Unidirectional Hybrid Attention is proposed through a double decoupling of the original attention operation, to rectify semantic errors and ambiguities of stored tokens in OneVOS framework. Finally, to alleviate the storage burden and expedite inference, we propose the Dynamic Token Selector, which unveils the working mechanism of OneVOS and naturally leads to a more efficient version of OneVOS. Extensive experiments demonstrate the superiority of OneVOS, achieving state-of-the-art performance across 7 datasets, particularly excelling in complex LVOS and MOSE datasets with 70.1% and 66.4% $J \& F$ scores, surpassing previous state-of-the-art methods by 4.2% and 7.0%, respectively. And our code will be available for reproducibility and further research.
UTBoost: A Tree-boosting based System for Uplift Modeling
Dec 05, 2023


Uplift modeling refers to the set of machine learning techniques that a manager may use to estimate customer uplift, that is, the net effect of an action on some customer outcome. By identifying the subset of customers for whom a treatment will have the greatest effect, uplift models assist decision-makers in optimizing resource allocations and maximizing overall returns. Accurately estimating customer uplift poses practical challenges, as it requires assessing the difference between two mutually exclusive outcomes for each individual. In this paper, we propose two innovative adaptations of the well-established Gradient Boosting Decision Trees (GBDT) algorithm, which learn the causal effect in a sequential way and overcome the counter-factual nature. Both approaches innovate existing techniques in terms of ensemble learning method and learning objectives, respectively. Experiments on large-scale datasets demonstrate the usefulness of the proposed methods, which often yielding remarkable improvements over base models. To facilitate the application, we develop the UTBoost, an end-to-end tree boosting system specifically designed for uplift modeling. The package is open source and has been optimized for training speed to meet the needs of real industrial applications.
Causally Invariant Predictor with Shift-Robustness
Jul 05, 2021
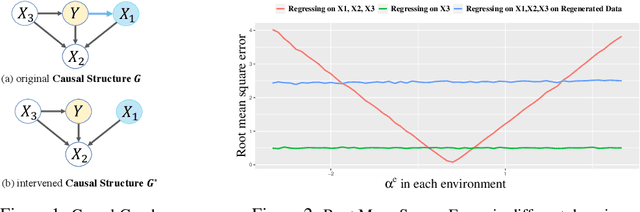

This paper proposes an invariant causal predictor that is robust to distribution shift across domains and maximally reserves the transferable invariant information. Based on a disentangled causal factorization, we formulate the distribution shift as soft interventions in the system, which covers a wide range of cases for distribution shift as we do not make prior specifications on the causal structure or the intervened variables. Instead of imposing regularizations to constrain the invariance of the predictor, we propose to predict by the intervened conditional expectation based on the do-operator and then prove that it is invariant across domains. More importantly, we prove that the proposed predictor is the robust predictor that minimizes the worst-case quadratic loss among the distributions of all domains. For empirical learning, we propose an intuitive and flexible estimating method based on data regeneration and present a local causal discovery procedure to guide the regeneration step. The key idea is to regenerate data such that the regenerated distribution is compatible with the intervened graph, which allows us to incorporate standard supervised learning methods with the regenerated data. Experimental results on both synthetic and real data demonstrate the efficacy of our predictor in improving the predictive accuracy and robustness across domains.
Latent Causal Invariant Model
Nov 04, 2020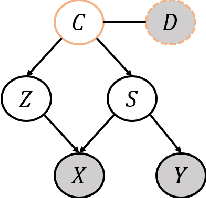


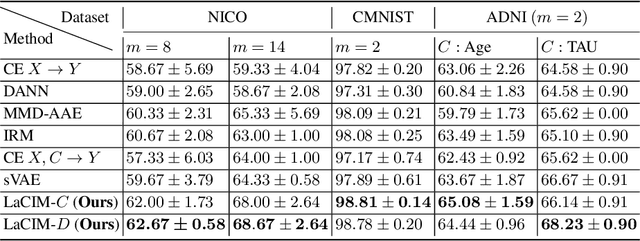
Current supervised learning can learn spurious correlation during the data-fitting process, imposing issues regarding interpretability, out-of-distribution (OOD) generalization, and robustness. To avoid spurious correlation, we propose a Latent Causal Invariance Model (LaCIM) which pursues causal prediction. Specifically, we introduce latent variables that are separated into (a) output-causative factors and (b) others that are spuriously correlated to the output via confounders, to model the underlying causal factors. We further assume the generating mechanisms from latent space to observed data to be causally invariant. We give the identifiable claim of such invariance, particularly the disentanglement of output-causative factors from others, as a theoretical guarantee for precise inference and avoiding spurious correlation. We propose a Variational-Bayesian-based method for estimation and to optimize over the latent space for prediction. The utility of our approach is verified by improved interpretability, prediction power on various OOD scenarios (including healthcare) and robustness on security.