 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtract and Attend: Improving Entity Translation in Neural Machine Translation
Jun 04, 2023While Neural Machine Translation(NMT) has achieved great progress in recent years, it still suffers from inaccurate translation of entities (e.g., person/organization name, location), due to the lack of entity training instances. When we humans encounter an unknown entity during translation, we usually first look up in a dictionary and then organize the entity translation together with the translations of other parts to form a smooth target sentence. Inspired by this translation process, we propose an Extract-and-Attend approach to enhance entity translation in NMT, where the translation candidates of source entities are first extracted from a dictionary and then attended to by the NMT model to generate the target sentence. Specifically, the translation candidates are extracted by first detecting the entities in a source sentence and then translating the entities through looking up in a dictionary. Then, the extracted candidates are added as a prefix of the decoder input to be attended to by the decoder when generating the target sentence through self-attention. Experiments conducted on En-Zh and En-Ru demonstrate that the proposed method is effective on improving both the translation accuracy of entities and the overall translation quality, with up to 35% reduction on entity error rate and 0.85 gain on BLEU and 13.8 gain on COMET.
A Survey on Non-Autoregressive Generation for Neural Machine Translation and Beyond
Apr 20, 2022

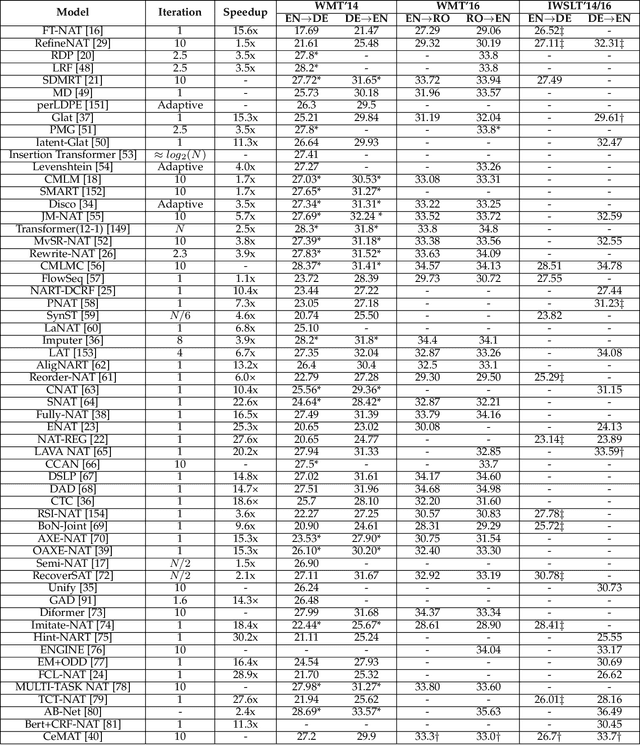
Non-autoregressive (NAR) generation, which is first proposed in neural machine translation (NMT) to speed up inference, has attracted much attention in both machine learning and natural language processing communities. While NAR generation can significantly accelerate inference speed for machine translation, the speedup comes at the cost of sacrificed translation accuracy compared to its counterpart, auto-regressive (AR) generation. In recent years, many new models and algorithms have been designed/proposed to bridge the accuracy gap between NAR generation and AR generation. In this paper, we conduct a systematic survey with comparisons and discussions of various non-autoregressive translation (NAT) models from different aspects. Specifically, we categorize the efforts of NAT into several groups, including data manipulation, modeling methods, training criterion, decoding algorithms, and the benefit from pre-trained models. Furthermore, we briefly review other applications of NAR models beyond machine translation, such as dialogue generation, text summarization, grammar error correction, semantic parsing, speech synthesis, and automatic speech recognition. In addition, we also discuss potential directions for future exploration, including releasing the dependency of KD, dynamic length prediction, pre-training for NAR, and wider applications, etc. We hope this survey can help researchers capture the latest progress in NAR generation, inspire the design of advanced NAR models and algorithms, and enable industry practitioners to choose appropriate solutions for their applications. The web page of this survey is at \url{https://github.com/LitterBrother-Xiao/Overview-of-Non-autoregressive-Applications}.
Latent Causal Invariant Model
Nov 04, 2020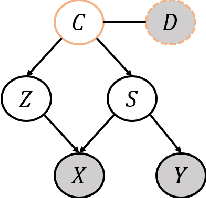


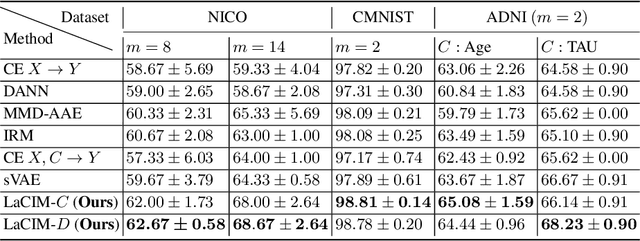
Current supervised learning can learn spurious correlation during the data-fitting process, imposing issues regarding interpretability, out-of-distribution (OOD) generalization, and robustness. To avoid spurious correlation, we propose a Latent Causal Invariance Model (LaCIM) which pursues causal prediction. Specifically, we introduce latent variables that are separated into (a) output-causative factors and (b) others that are spuriously correlated to the output via confounders, to model the underlying causal factors. We further assume the generating mechanisms from latent space to observed data to be causally invariant. We give the identifiable claim of such invariance, particularly the disentanglement of output-causative factors from others, as a theoretical guarantee for precise inference and avoiding spurious correlation. We propose a Variational-Bayesian-based method for estimation and to optimize over the latent space for prediction. The utility of our approach is verified by improved interpretability, prediction power on various OOD scenarios (including healthcare) and robustness on security.
GraphNorm: A Principled Approach to Accelerating Graph Neural Network Training
Sep 07, 2020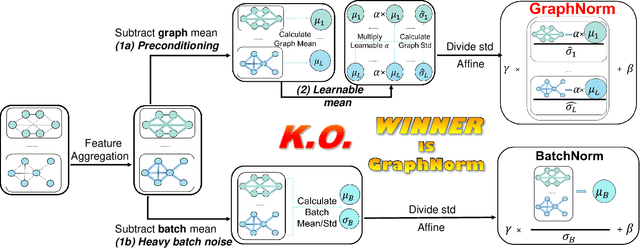
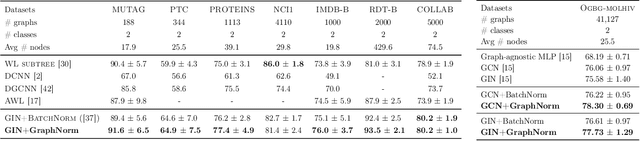
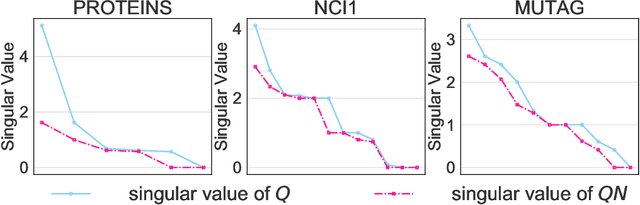
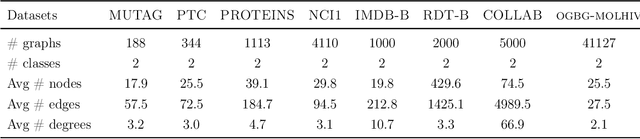
Normalization plays an important role in the optimization of deep neural networks. While there are standard normalization methods in computer vision and natural language processing, there is limited understanding of how to effectively normalize neural networks for graph representation learning. In this paper, we propose a principled normalization method, Graph Normalization (GraphNorm), where the key idea is to normalize the feature values across all nodes for each individual graph with a learnable shift. Theoretically, we show that GraphNorm serves as a preconditioner that smooths the distribution of the graph aggregation's spectrum, leading to faster optimization. Such an improvement cannot be well obtained if we use currently popular normalization methods, such as BatchNorm, which normalizes the nodes in a batch rather than in individual graphs, due to heavy batch noises. Moreover, we show that for some highly regular graphs, the mean of the feature values contains graph structural information, and directly subtracting the mean may lead to an expressiveness degradation. The learnable shift in GraphNorm enables the model to learn to avoid such degradation for those cases. Empirically, Graph neural networks (GNNs) with GraphNorm converge much faster compared to GNNs with other normalization methods, e.g., BatchNorm. GraphNorm also improves generalization of GNNs, achieving better performance on graph classification benchmarks.