 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization of Graph Neural Networks: Implicit Acceleration by Skip Connections and More Depth
May 26, 2021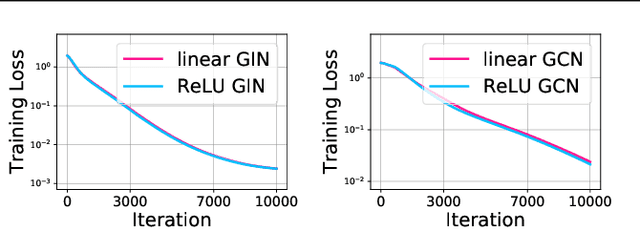
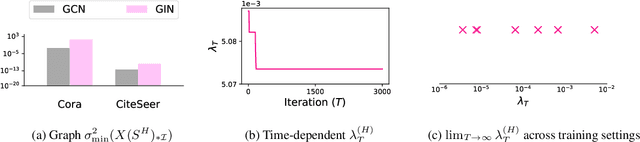
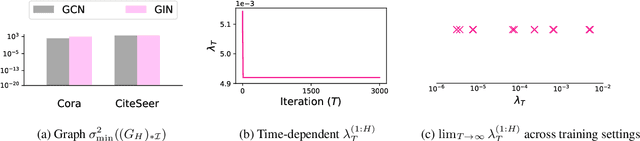
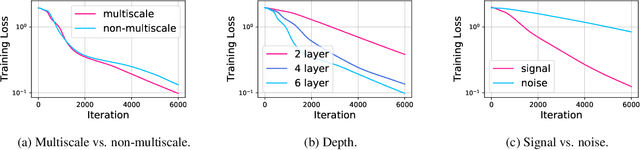
Graph Neural Networks (GNNs) have been studied through the lens of expressive power and generalization. However, their optimization properties are less well understood. We take the first step towards analyzing GNN training by studying the gradient dynamics of GNNs. First, we analyze linearized GNNs and prove that despite the non-convexity of training, convergence to a global minimum at a linear rate is guaranteed under mild assumptions that we validate on real-world graphs. Second, we study what may affect the GNNs' training speed. Our results show that the training of GNNs is implicitly accelerated by skip connections, more depth, and/or a good label distribution. Empirical results confirm that our theoretical results for linearized GNNs align with the training behavior of nonlinear GNNs. Our results provide the first theoretical support for the success of GNNs with skip connections in terms of optimization, and suggest that deep GNNs with skip connections would be promising in practice.
Noisy Labels Can Induce Good Representations
Dec 23, 2020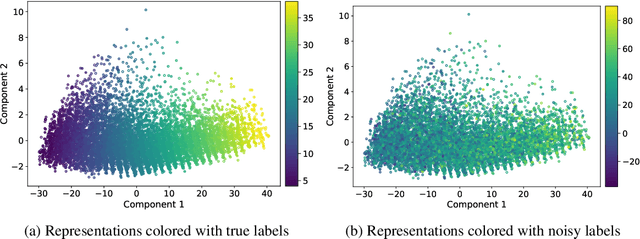

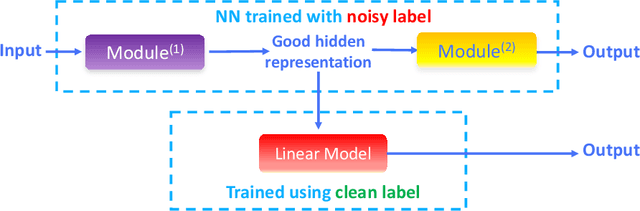
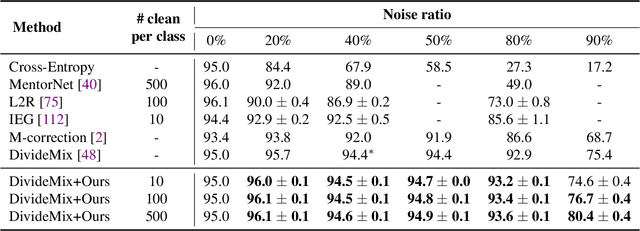
The current success of deep learning depends on large-scale labeled datasets. In practice, high-quality annotations are expensive to collect, but noisy annotations are more affordable. Previous works report mixed empirical results when training with noisy labels: neural networks can easily memorize random labels, but they can also generalize from noisy labels. To explain this puzzle, we study how architecture affects learning with noisy labels. We observe that if an architecture "suits" the task, training with noisy labels can induce useful hidden representations, even when the model generalizes poorly; i.e., the last few layers of the model are more negatively affected by noisy labels. This finding leads to a simple method to improve models trained on noisy labels: replacing the final dense layers with a linear model, whose weights are learned from a small set of clean data. We empirically validate our findings across three architectures (Convolutional Neural Networks, Graph Neural Networks, and Multi-Layer Perceptrons) and two domains (graph algorithmic tasks and image classification). Furthermore, we achieve state-of-the-art results on image classification benchmarks by combining our method with existing approaches on noisy label training.
Graph Adversarial Networks: Protecting Information against Adversarial Attacks
Oct 07, 2020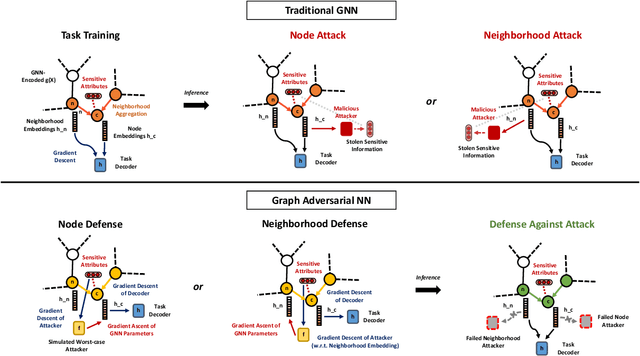
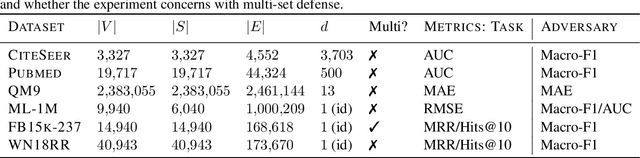
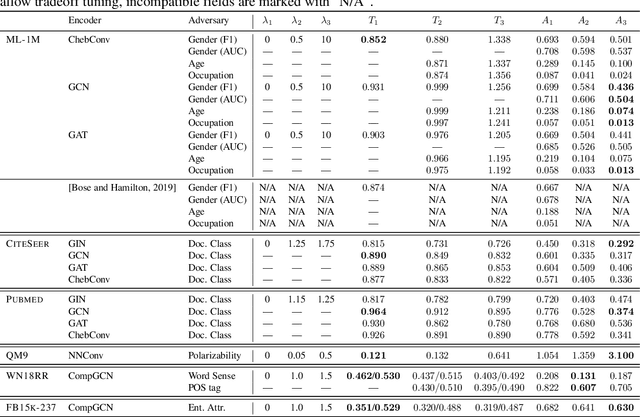
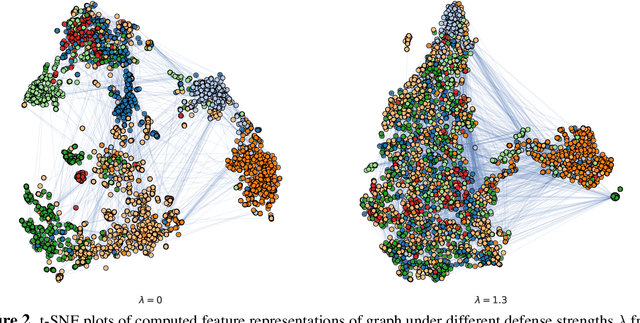
We study the problem of protecting information when learning with graph-structured data. While the advent of Graph Neural Networks (GNNs) has greatly improved node and graph representational learning in many applications, the neighborhood aggregation paradigm exposes additional vulnerabilities to attackers seeking to extract node-level information about sensitive attributes. To counter this, we propose a minimax game between the desired GNN encoder and the worst-case attacker. The resulting adversarial training creates a strong defense against inference attacks, while only suffering a small loss in task performance. We analyze the effectiveness of our framework against a worst-case adversary, and characterize the trade-off between predictive accuracy and adversarial defense. Experiments across multiple datasets from recommender systems, knowledge graphs and quantum chemistry demonstrate that the proposed approach provides a robust defense across various graph structures and tasks, while producing competitive GNN encoders. Our code is available at https://github.com/liaopeiyuan/GAL.
How Neural Networks Extrapolate: From Feedforward to Graph Neural Networks
Oct 01, 2020


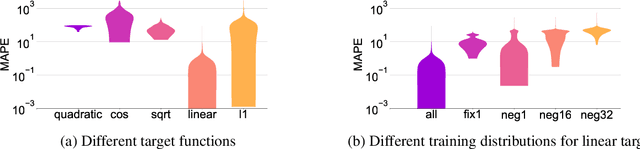
We study how neural networks trained by gradient descent extrapolate, i.e., what they learn outside the support of the training distribution. Previous works report mixed empirical results when extrapolating with neural networks: while multilayer perceptrons (MLPs) do not extrapolate well in certain simple tasks, Graph Neural Network (GNN), a structured network with MLP modules, has shown some success in more complex tasks. Working towards a theoretical explanation, we identify conditions under which MLPs and GNNs extrapolate well. First, we quantify the observation that ReLU MLPs quickly converge to linear functions along any direction from the origin, which implies that ReLU MLPs do not extrapolate most non-linear functions. But, they can provably learn a linear target function when the training distribution is sufficiently "diverse". Second, in connection to analyzing successes and limitations of GNNs, these results suggest a hypothesis for which we provide theoretical and empirical evidence: the success of GNNs in extrapolating algorithmic tasks to new data (e.g., larger graphs or edge weights) relies on encoding task-specific non-linearities in the architecture or features.
GraphNorm: A Principled Approach to Accelerating Graph Neural Network Training
Sep 07, 2020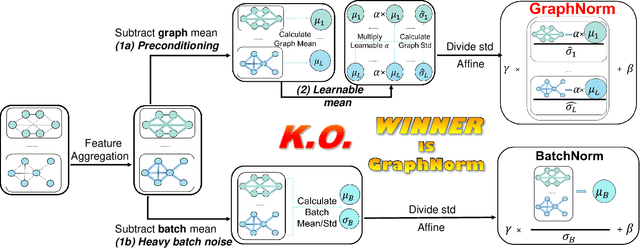
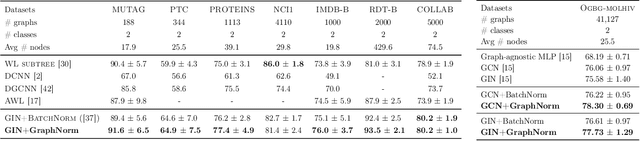
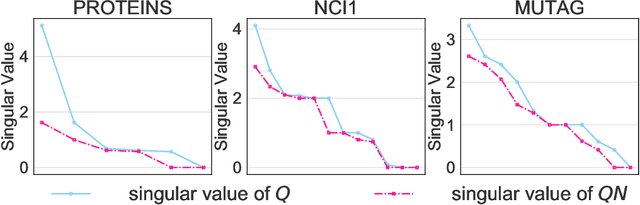
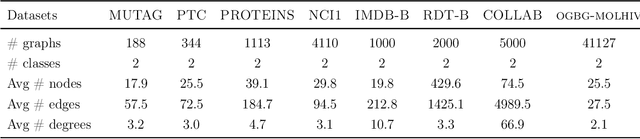
Normalization plays an important role in the optimization of deep neural networks. While there are standard normalization methods in computer vision and natural language processing, there is limited understanding of how to effectively normalize neural networks for graph representation learning. In this paper, we propose a principled normalization method, Graph Normalization (GraphNorm), where the key idea is to normalize the feature values across all nodes for each individual graph with a learnable shift. Theoretically, we show that GraphNorm serves as a preconditioner that smooths the distribution of the graph aggregation's spectrum, leading to faster optimization. Such an improvement cannot be well obtained if we use currently popular normalization methods, such as BatchNorm, which normalizes the nodes in a batch rather than in individual graphs, due to heavy batch noises. Moreover, we show that for some highly regular graphs, the mean of the feature values contains graph structural information, and directly subtracting the mean may lead to an expressiveness degradation. The learnable shift in GraphNorm enables the model to learn to avoid such degradation for those cases. Empirically, Graph neural networks (GNNs) with GraphNorm converge much faster compared to GNNs with other normalization methods, e.g., BatchNorm. GraphNorm also improves generalization of GNNs, achieving better performance on graph classification benchmarks.
Are Girls Neko or Shōjo? Cross-Lingual Alignment of Non-Isomorphic Embeddings with Iterative Normalization
Jun 05, 2019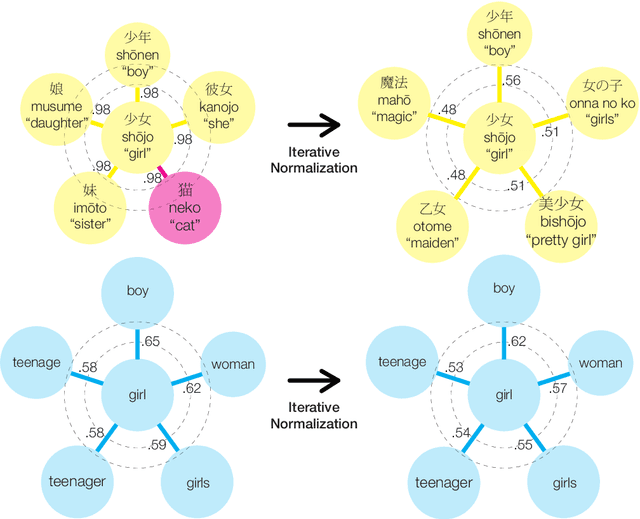
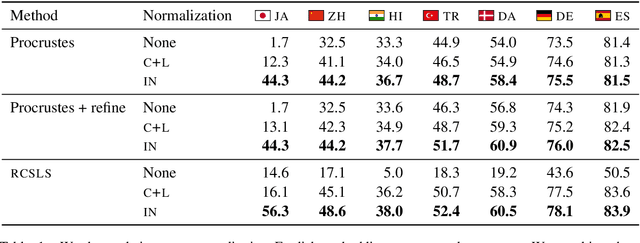
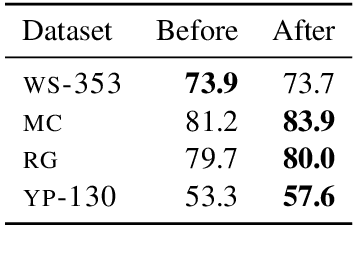
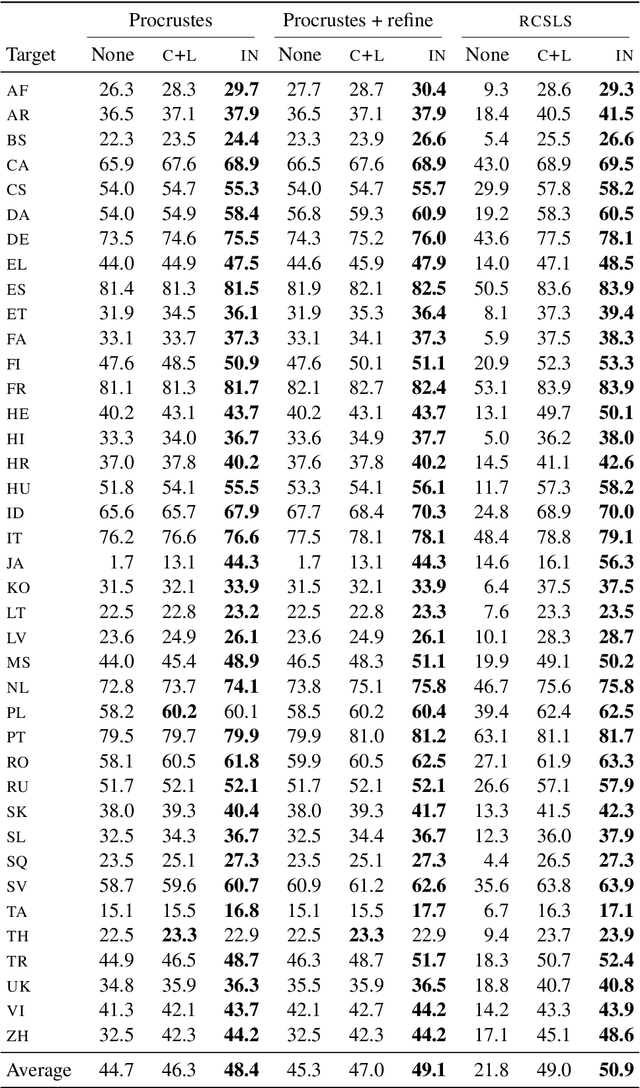
Cross-lingual word embeddings (CLWE) underlie many multilingual natural language processing systems, often through orthogonal transformations of pre-trained monolingual embeddings. However, orthogonal mapping only works on language pairs whose embeddings are naturally isomorphic. For non-isomorphic pairs, our method (Iterative Normalization) transforms monolingual embeddings to make orthogonal alignment easier by simultaneously enforcing that (1) individual word vectors are unit length, and (2) each language's average vector is zero. Iterative Normalization consistently improves word translation accuracy of three CLWE methods, with the largest improvement observed on English-Japanese (from 2% to 44% test accuracy).
What Can Neural Networks Reason About?
May 31, 2019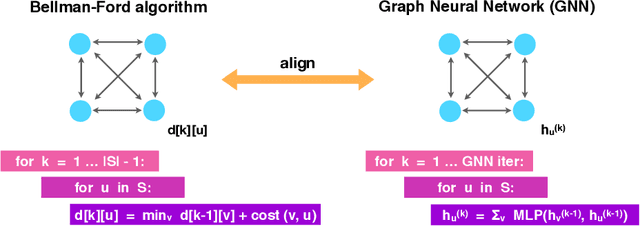
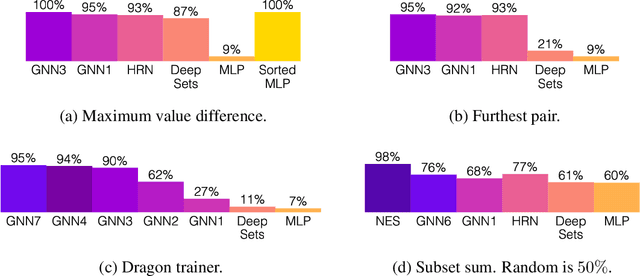
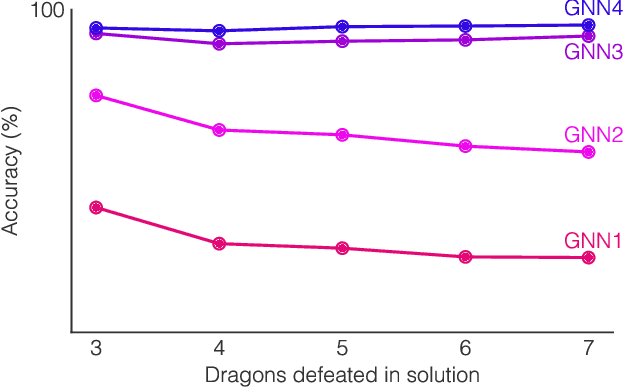
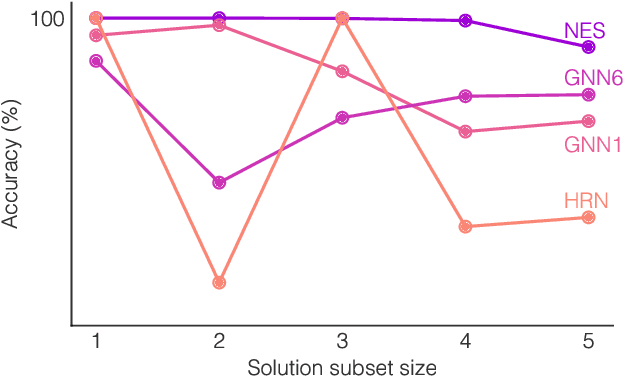
Neural networks have successfully been applied to solving reasoning tasks, ranging from learning simple concepts like "close to", to intricate questions whose reasoning procedures resemble algorithms. Empirically, not all network structures work equally well for reasoning. For example, Graph Neural Networks have achieved impressive empirical results, while less structured neural networks may fail to learn to reason. Theoretically, there is currently limited understanding of the interplay between reasoning tasks and network learning. In this paper, we develop a framework to characterize which tasks a neural network can learn well, by studying how well its structure aligns with the algorithmic structure of the relevant reasoning procedure. This suggests that Graph Neural Networks can learn dynamic programming, a powerful algorithmic strategy that solves a broad class of reasoning problems, such as relational question answering, sorting, intuitive physics, and shortest paths. Our perspective also implies strategies to design neural architectures for complex reasoning. On several abstract reasoning tasks, we see empirically that our theory aligns well with practice.
Graph Neural Tangent Kernel: Fusing Graph Neural Networks with Graph Kernels
May 30, 2019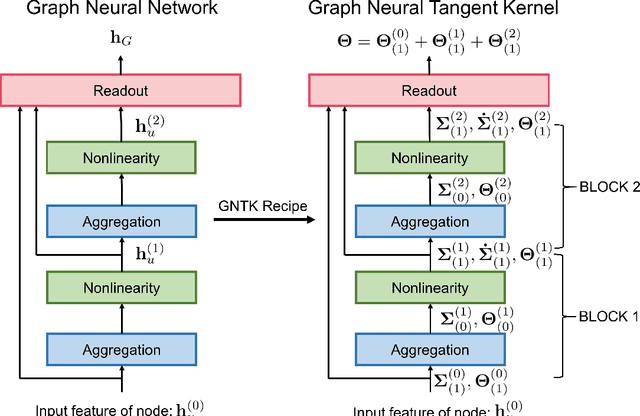
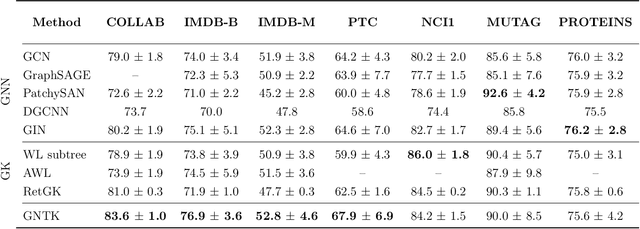
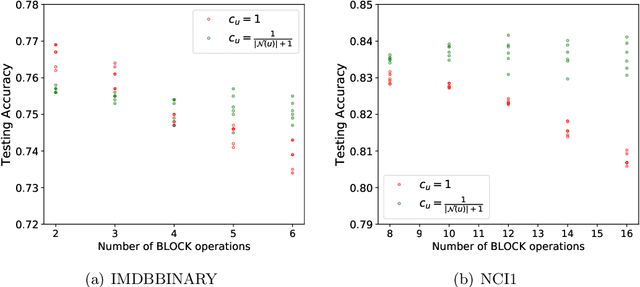
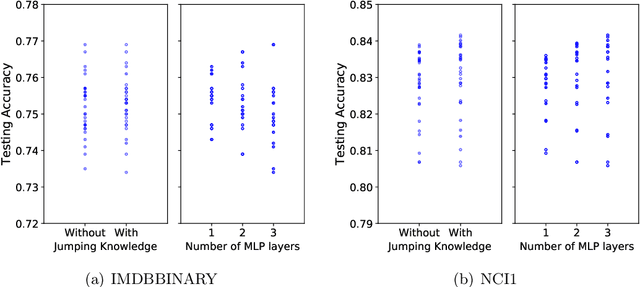
While graph kernels (GKs) are easy to train and enjoy provable theoretical guarantees, their practical performances are limited by their expressive power, as the kernel function often depends on hand-crafted combinatorial features of graphs. Compared to graph kernels, graph neural networks (GNNs) usually achieve better practical performance, as GNNs use multi-layer architectures and non-linear activation functions to extract high-order information of graphs as features. However, due to the large number of hyper-parameters and the non-convex nature of the training procedure, GNNs are harder to train. Theoretical guarantees of GNNs are also not well-understood. Furthermore, the expressive power of GNNs scales with the number of parameters, and thus it is hard to exploit the full power of GNNs when computing resources are limited. The current paper presents a new class of graph kernels, Graph Neural Tangent Kernels (GNTKs), which correspond to \emph{infinitely wide} multi-layer GNNs trained by gradient descent. GNTKs enjoy the full expressive power of GNNs and inherit advantages of GKs. Theoretically, we show GNTKs provably learn a class of smooth functions on graphs. Empirically, we test GNTKs on graph classification datasets and show they achieve strong performance.
How Powerful are Graph Neural Networks?
Oct 01, 2018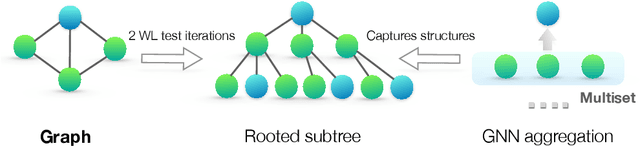
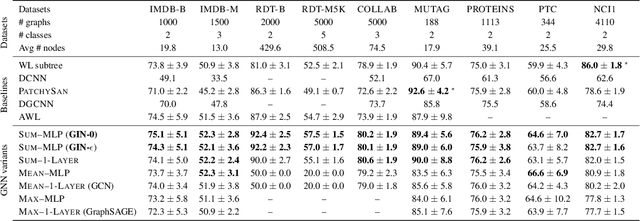
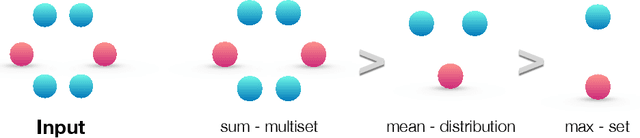

Graph Neural Networks (GNNs) for representation learning of graphs broadly follow a neighborhood aggregation framework, where the representation vector of a node is computed by recursively aggregating and transforming feature vectors of its neighboring nodes. Many GNN variants have been proposed and have achieved state-of-the-art results on both node and graph classification tasks. However, despite GNNs revolutionizing graph representation learning, there is limited understanding of their representational properties and limitations. Here, we present a theoretical framework for analyzing the expressive power of GNNs in capturing different graph structures. Our results characterize the discriminative power of popular GNN variants, such as Graph Convolutional Networks and GraphSAGE, and show that they cannot learn to distinguish certain simple graph structures. We then develop a simple architecture that is provably the most expressive among the class of GNNs and is as powerful as the Weisfeiler-Lehman graph isomorphism test. We empirically validate our theoretical findings on a number of graph classification benchmarks, and demonstrate that our model achieves state-of-the-art performance.
Representation Learning on Graphs with Jumping Knowledge Networks
Jun 25, 2018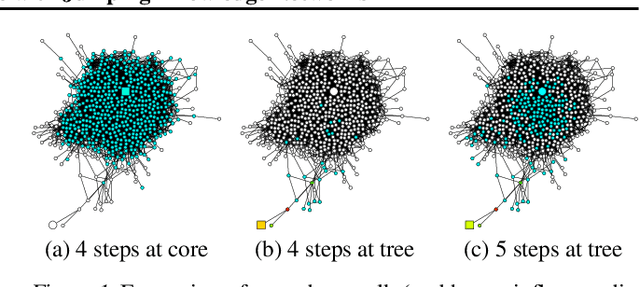

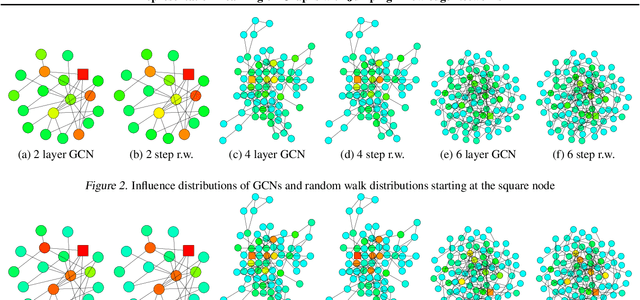
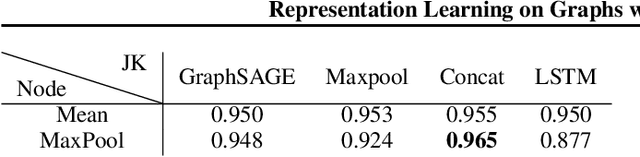
Recent deep learning approaches for representation learning on graphs follow a neighborhood aggregation procedure. We analyze some important properties of these models, and propose a strategy to overcome those. In particular, the range of "neighboring" nodes that a node's representation draws from strongly depends on the graph structure, analogous to the spread of a random walk. To adapt to local neighborhood properties and tasks, we explore an architecture -- jumping knowledge (JK) networks -- that flexibly leverages, for each node, different neighborhood ranges to enable better structure-aware representation. In a number of experiments on social, bioinformatics and citation networks, we demonstrate that our model achieves state-of-the-art performance. Furthermore, combining the JK framework with models like Graph Convolutional Networks, GraphSAGE and Graph Attention Networks consistently improves those models' performance.