 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInitialization is Half the Battle: Generating Diverse Images from a Guidance Potential Posterior
Jun 01, 2026Despite the remarkable fidelity of generative models, they frequently suffer from mode collapse. Existing strategies for enhancing diversity predominantly focus on intervening during the generation trajectory. We identify a critical oversight that the standard Gaussian initialization often causes trajectories to collapse into dominant modes because it is agnostic to the guidance potential landscape. In this work, we formulate selecting the initial noise from a guidance potential posterior, which effectively re-weights the prior towards diversity-rich regions. To sample from this distribution efficiently, we introduce Diversity-inducing Initialization (DivIn), which leverages Langevin dynamics to actively navigate the initialization landscape, steering initial noise away from collapsing regions while anchoring them to the valid data manifold. Our method serves as an inference-time diversity enhancement compatible with both diffusion and flow matching models. Extensive experiments show that DivIn exhibits a superior performance in both class-to-image and text-to-image scenarios. Furthermore, we highlight that as DivIn is orthogonal to trajectory-based methods, combining them significantly expands the diversity-quality Pareto frontier beyond what either achieves in isolation.
Reasoning Resides in Layers: Restoring Temporal Reasoning in Video-Language Models with Layer-Selective Merging
Apr 13, 2026Multimodal adaptation equips large language models (LLMs) with perceptual capabilities, but often weakens the reasoning ability inherited from language-only pretraining. This trade-off is especially pronounced in video-language models (VLMs), where visual alignment can impair temporal reasoning (TR) over sequential events. We propose MERIT, a training-free, task-driven model merging framework for restoring TR in VLMs. MERIT searches over layer-wise self-attention merging recipes between a VLM and its paired text-only backbone using an objective that improves TR while penalizing degradation in temporal perception (TP). Across three representative VLMs and multiple challenging video benchmarks, MERIT consistently improves TR, preserves or improves TP, and generalizes beyond the search set to four distinct benchmarks. It also outperforms uniform full-model merging and random layer selection, showing that effective recovery depends on selecting the right layers. Interventional masking and frame-level attribution further show that the selected layers are disproportionately important for reasoning and shift model decisions toward temporally and causally relevant evidence. These results show that targeted, perception-aware model merging can effectively restore TR in VLMs without retraining.
In-Context Reinforcement Learning for Tool Use in Large Language Models
Mar 09, 2026While large language models (LLMs) exhibit strong reasoning abilities, their performance on complex tasks is often constrained by the limitations of their internal knowledge. A compelling approach to overcome this challenge is to augment these models with external tools -- such as Python interpreters for mathematical computations or search engines for retrieving factual information. However, enabling models to use these tools effectively remains a significant challenge. Existing methods typically rely on cold-start pipelines that begin with supervised fine-tuning (SFT), followed by reinforcement learning (RL). These approaches often require substantial amounts of labeled data for SFT, which is expensive to annotate or synthesize. In this work, we propose In-Context Reinforcement Learning (ICRL), an RL-only framework that eliminates the need for SFT by leveraging few-shot prompting during the rollout stage of RL. Specifically, ICRL introduces in-context examples within the rollout prompts to teach the model how to invoke external tools. Furthermore, as training progresses, the number of in-context examples is gradually reduced, eventually reaching a zero-shot setting where the model learns to call tools independently. We conduct extensive experiments across a range of reasoning and tool-use benchmarks. Results show that ICRL achieves state-of-the-art performance, demonstrating its effectiveness as a scalable, data-efficient alternative to traditional SFT-based pipelines.
Strategy Executability in Mathematical Reasoning: Leveraging Human-Model Differences for Effective Guidance
Feb 26, 2026Example-based guidance is widely used to improve mathematical reasoning at inference time, yet its effectiveness is highly unstable across problems and models-even when the guidance is correct and problem-relevant. We show that this instability arises from a previously underexplored gap between strategy usage-whether a reasoning strategy appears in successful solutions-and strategy executability-whether the strategy remains effective when instantiated as guidance for a target model. Through a controlled analysis of paired human-written and model-generated solutions, we identify a systematic dissociation between usage and executability: human- and model-derived strategies differ in structured, domain-dependent ways, leading to complementary strengths and consistent source-dependent reversals under guidance. Building on this diagnosis, we propose Selective Strategy Retrieval (SSR), a test-time framework that explicitly models executability by selectively retrieving and combining strategies using empirical, multi-route, source-aware signals. Across multiple mathematical reasoning benchmarks, SSR yields reliable and consistent improvements over direct solving, in-context learning, and single-source guidance, improving accuracy by up to $+13$ points on AIME25 and $+5$ points on Apex for compact reasoning models. Code and benchmark are publicly available at: https://github.com/lwd17/strategy-execute-pipeline.
Gradually Compacting Large Language Models for Reasoning Like a Boiling Frog
Feb 04, 2026Large Language Models (LLMs) have demonstrated impressive reasoning capabilities, but their substantial size often demands significant computational resources. To reduce resource consumption and accelerate inference, it is essential to eliminate redundant parameters without compromising performance. However, conventional pruning methods that directly remove such parameters often lead to a dramatic drop in model performance in reasoning tasks, and require extensive post-training to recover the lost capabilities. In this work, we propose a gradual compacting method that divides the compression process into multiple fine-grained iterations, applying a Prune-Tune Loop (PTL) at each stage to incrementally reduce model size while restoring performance with finetuning. This iterative approach-reminiscent of the "boiling frog" effect-enables the model to be progressively compressed without abrupt performance loss. Experimental results show that PTL can compress LLMs to nearly half their original size with only lightweight post-training, while maintaining performance comparable to the original model on reasoning tasks. Moreover, PTL is flexible and can be applied to various pruning strategies, such as neuron pruning and layer pruning, as well as different post-training methods, including continual pre-training and reinforcement learning. Additionally, experimental results confirm the effectiveness of PTL on a variety of tasks beyond mathematical reasoning, such as code generation, demonstrating its broad applicability.
DeRaDiff: Denoising Time Realignment of Diffusion Models
Jan 28, 2026Recent advances align diffusion models with human preferences to increase aesthetic appeal and mitigate artifacts and biases. Such methods aim to maximize a conditional output distribution aligned with higher rewards whilst not drifting far from a pretrained prior. This is commonly enforced by KL (Kullback Leibler) regularization. As such, a central issue still remains: how does one choose the right regularization strength? Too high of a strength leads to limited alignment and too low of a strength leads to "reward hacking". This renders the task of choosing the correct regularization strength highly non-trivial. Existing approaches sweep over this hyperparameter by aligning a pretrained model at multiple regularization strengths and then choose the best strength. Unfortunately, this is prohibitively expensive. We introduce DeRaDiff, a denoising time realignment procedure that, after aligning a pretrained model once, modulates the regularization strength during sampling to emulate models trained at other regularization strengths without any additional training or finetuning. Extending decoding-time realignment from language to diffusion models, DeRaDiff operates over iterative predictions of continuous latents by replacing the reverse step reference distribution by a geometric mixture of an aligned and reference posterior, thus giving rise to a closed form update under common schedulers and a single tunable parameter, lambda, for on the fly control. Our experiments show that across multiple text image alignment and image-quality metrics, our method consistently provides a strong approximation for models aligned entirely from scratch at different regularization strengths. Thus, our method yields an efficient way to search for the optimal strength, eliminating the need for expensive alignment sweeps and thereby substantially reducing computational costs.
Unconsciously Forget: Mitigating Memorization; Without Knowing What is being Memorized
Dec 12, 2025Recent advances in generative models have demonstrated an exceptional ability to produce highly realistic images. However, previous studies show that generated images often resemble the training data, and this problem becomes more severe as the model size increases. Memorizing training data can lead to legal challenges, including copyright infringement, violations of portrait rights, and trademark violations. Existing approaches to mitigating memorization mainly focus on manipulating the denoising sampling process to steer image embeddings away from the memorized embedding space or employ unlearning methods that require training on datasets containing specific sets of memorized concepts. However, existing methods often incur substantial computational overhead during sampling, or focus narrowly on removing one or more groups of target concepts, imposing a significant limitation on their scalability. To understand and mitigate these problems, our work, UniForget, offers a new perspective on understanding the root cause of memorization. Our work demonstrates that specific parts of the model are responsible for copyrighted content generation. By applying model pruning, we can effectively suppress the probability of generating copyrighted content without targeting specific concepts while preserving the general generative capabilities of the model. Additionally, we show that our approach is both orthogonal and complementary to existing unlearning methods, thereby highlighting its potential to improve current unlearning and de-memorization techniques.
LoReUn: Data Itself Implicitly Provides Cues to Improve Machine Unlearning
Jul 30, 2025Recent generative models face significant risks of producing harmful content, which has underscored the importance of machine unlearning (MU) as a critical technique for eliminating the influence of undesired data. However, existing MU methods typically assign the same weight to all data to be forgotten, which makes it difficult to effectively forget certain data that is harder to unlearn than others. In this paper, we empirically demonstrate that the loss of data itself can implicitly reflect its varying difficulty. Building on this insight, we introduce Loss-based Reweighting Unlearning (LoReUn), a simple yet effective plug-and-play strategy that dynamically reweights data during the unlearning process with minimal additional computational overhead. Our approach significantly reduces the gap between existing MU methods and exact unlearning in both image classification and generation tasks, effectively enhancing the prevention of harmful content generation in text-to-image diffusion models.
Who's important? -- SUnSET: Synergistic Understanding of Stakeholder, Events and Time for Timeline Generation
Jul 29, 2025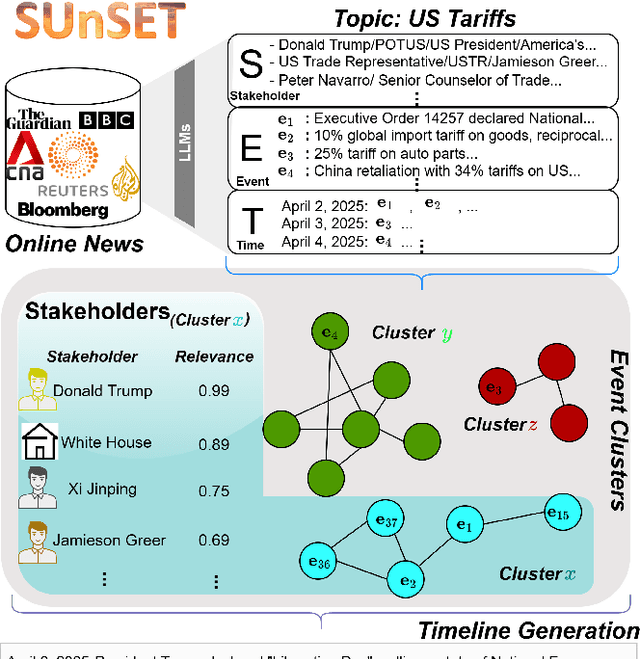
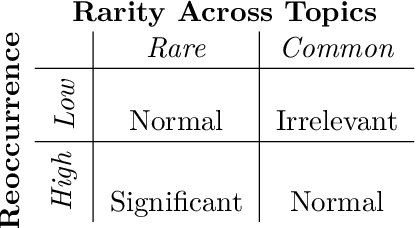
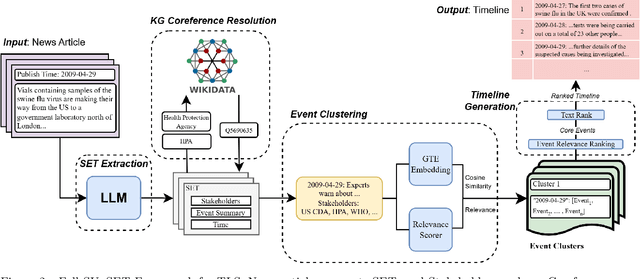
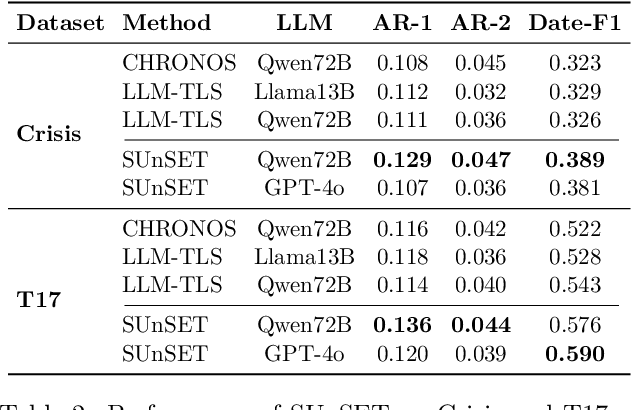
As news reporting becomes increasingly global and decentralized online, tracking related events across multiple sources presents significant challenges. Existing news summarization methods typically utilizes Large Language Models and Graphical methods on article-based summaries. However, this is not effective since it only considers the textual content of similarly dated articles to understand the gist of the event. To counteract the lack of analysis on the parties involved, it is essential to come up with a novel framework to gauge the importance of stakeholders and the connection of related events through the relevant entities involved. Therefore, we present SUnSET: Synergistic Understanding of Stakeholder, Events and Time for the task of Timeline Summarization (TLS). We leverage powerful Large Language Models (LLMs) to build SET triplets and introduced the use of stakeholder-based ranking to construct a $Relevancy$ metric, which can be extended into general situations. Our experimental results outperform all prior baselines and emerged as the new State-of-the-Art, highlighting the impact of stakeholder information within news article.
Prefix-Tuning+: Modernizing Prefix-Tuning through Attention Independent Prefix Data
Jun 16, 2025Parameter-Efficient Fine-Tuning (PEFT) methods have become crucial for rapidly adapting large language models (LLMs) to downstream tasks. Prefix-Tuning, an early and effective PEFT technique, demonstrated the ability to achieve performance comparable to full fine-tuning with significantly reduced computational and memory overhead. However, despite its earlier success, its effectiveness in training modern state-of-the-art LLMs has been very limited. In this work, we demonstrate empirically that Prefix-Tuning underperforms on LLMs because of an inherent tradeoff between input and prefix significance within the attention head. This motivates us to introduce Prefix-Tuning+, a novel architecture that generalizes the principles of Prefix-Tuning while addressing its shortcomings by shifting the prefix module out of the attention head itself. We further provide an overview of our construction process to guide future users when constructing their own context-based methods. Our experiments show that, across a diverse set of benchmarks, Prefix-Tuning+ consistently outperforms existing Prefix-Tuning methods. Notably, it achieves performance on par with the widely adopted LoRA method on several general benchmarks, highlighting the potential modern extension of Prefix-Tuning approaches. Our findings suggest that by overcoming its inherent limitations, Prefix-Tuning can remain a competitive and relevant research direction in the landscape of parameter-efficient LLM adaptation.