 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnthropogenic Regional Adaptation in Multimodal Vision-Language Model
Apr 13, 2026While the field of vision-language (VL) has achieved remarkable success in integrating visual and textual information across multiple languages and domains, there is still no dedicated framework for assessing human-centric alignment in vision-language systems. We offer two contributions to address this gap. First, we introduce Anthropogenic Regional Adaptation: a novel paradigm that aims to optimize model relevance to specific regional contexts while ensuring the retention of global generalization capabilities. Second, we present a simple, but effective adaptation method named Geographical-generalization-made-easy (GG-EZ), which utilizes regional data filtering and model merging. Through comprehensive experiments on 3 VL architectures: large vision-language models, text-to-image diffusion models, and vision-language embedding models, and a case study in Southeast Asia (SEA) regional adaptation, we demonstrate the importance of Anthropogenic Regional Adaptation and the effectiveness of GG-EZ, showing 5-15% gains in cultural relevance metrics across SEA while maintaining over 98% of global performance and even occasionally surpassing it. Our findings establish Anthropogenic Regional Alignment as a foundational paradigm towards applicability of multimodal vision-language models in diverse regions and demonstrate a simple-yet-effective baseline method that optimizes regional value alignment while preserving global generalization.
What Makes a Good Natural Language Prompt?
Jun 07, 2025
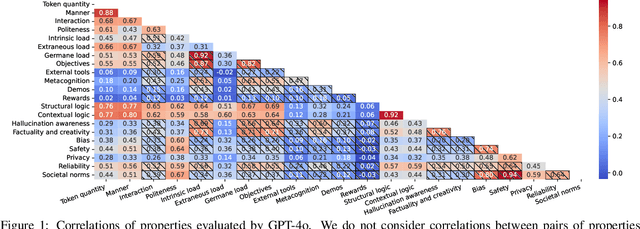
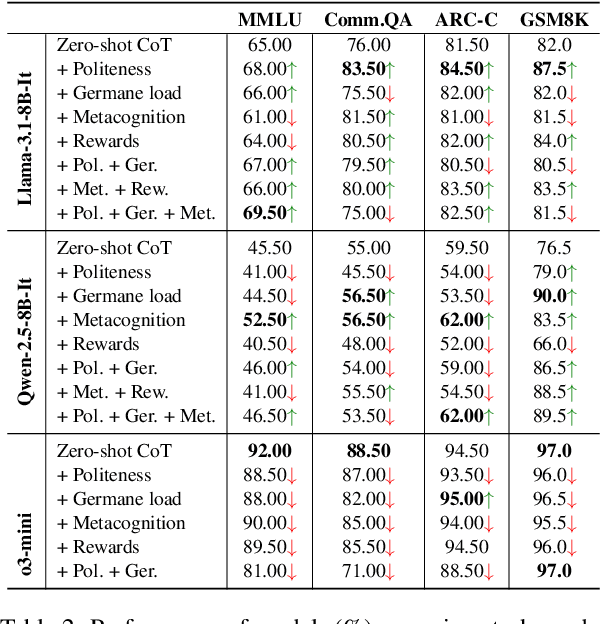
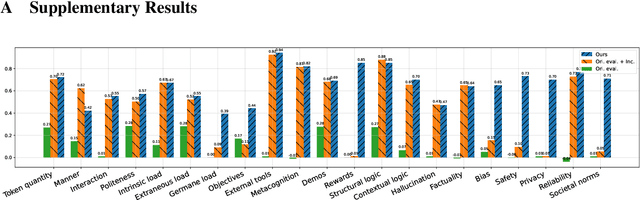
As large language models (LLMs) have progressed towards more human-like and human--AI communications have become prevalent, prompting has emerged as a decisive component. However, there is limited conceptual consensus on what exactly quantifies natural language prompts. We attempt to address this question by conducting a meta-analysis surveying more than 150 prompting-related papers from leading NLP and AI conferences from 2022 to 2025 and blogs. We propose a property- and human-centric framework for evaluating prompt quality, encompassing 21 properties categorized into six dimensions. We then examine how existing studies assess their impact on LLMs, revealing their imbalanced support across models and tasks, and substantial research gaps. Further, we analyze correlations among properties in high-quality natural language prompts, deriving prompting recommendations. We then empirically explore multi-property prompt enhancements in reasoning tasks, observing that single-property enhancements often have the greatest impact. Finally, we discover that instruction-tuning on property-enhanced prompts can result in better reasoning models. Our findings establish a foundation for property-centric prompt evaluation and optimization, bridging the gaps between human--AI communication and opening new prompting research directions.
A Survey of Frontiers in LLM Reasoning: Inference Scaling, Learning to Reason, and Agentic Systems
Apr 12, 2025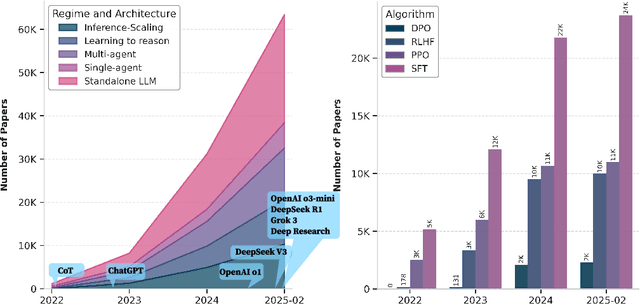

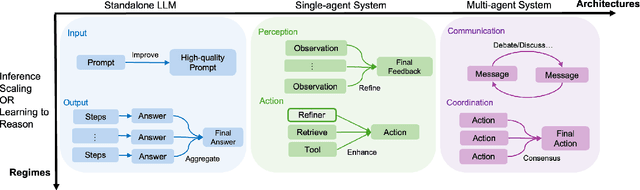

Reasoning is a fundamental cognitive process that enables logical inference, problem-solving, and decision-making. With the rapid advancement of large language models (LLMs), reasoning has emerged as a key capability that distinguishes advanced AI systems from conventional models that empower chatbots. In this survey, we categorize existing methods along two orthogonal dimensions: (1) Regimes, which define the stage at which reasoning is achieved (either at inference time or through dedicated training); and (2) Architectures, which determine the components involved in the reasoning process, distinguishing between standalone LLMs and agentic compound systems that incorporate external tools, and multi-agent collaborations. Within each dimension, we analyze two key perspectives: (1) Input level, which focuses on techniques that construct high-quality prompts that the LLM condition on; and (2) Output level, which methods that refine multiple sampled candidates to enhance reasoning quality. This categorization provides a systematic understanding of the evolving landscape of LLM reasoning, highlighting emerging trends such as the shift from inference-scaling to learning-to-reason (e.g., DeepSeek-R1), and the transition to agentic workflows (e.g., OpenAI Deep Research, Manus Agent). Additionally, we cover a broad spectrum of learning algorithms, from supervised fine-tuning to reinforcement learning such as PPO and GRPO, and the training of reasoners and verifiers. We also examine key designs of agentic workflows, from established patterns like generator-evaluator and LLM debate to recent innovations. ...
Multi-expert Prompting Improves Reliability, Safety, and Usefulness of Large Language Models
Nov 01, 2024



We present Multi-expert Prompting, a novel enhancement of ExpertPrompting (Xu et al., 2023), designed to improve the large language model (LLM) generation. Specifically, it guides an LLM to fulfill an input instruction by simulating multiple experts, aggregating their responses, and selecting the best among individual and aggregated responses. This process is performed in a single chain of thoughts through our seven carefully designed subtasks derived from the Nominal Group Technique (Ven and Delbecq, 1974), a well-established decision-making framework. Our evaluations demonstrate that Multi-expert Prompting significantly outperforms ExpertPrompting and comparable baselines in enhancing the truthfulness, factuality, informativeness, and usefulness of responses while reducing toxicity and hurtfulness. It further achieves state-of-the-art truthfulness by outperforming the best baseline by 8.69% with ChatGPT. Multi-expert Prompting is efficient, explainable, and highly adaptable to diverse scenarios, eliminating the need for manual prompt construction.
LLMs Are Biased Towards Output Formats! Systematically Evaluating and Mitigating Output Format Bias of LLMs
Aug 16, 2024We present the first systematic evaluation examining format bias in performance of large language models (LLMs). Our approach distinguishes between two categories of an evaluation metric under format constraints to reliably and accurately assess performance: one measures performance when format constraints are adhered to, while the other evaluates performance regardless of constraint adherence. We then define a metric for measuring the format bias of LLMs and establish effective strategies to reduce it. Subsequently, we present our empirical format bias evaluation spanning four commonly used categories -- multiple-choice question-answer, wrapping, list, and mapping -- covering 15 widely-used formats. Our evaluation on eight generation tasks uncovers significant format bias across state-of-the-art LLMs. We further discover that improving the format-instruction following capabilities of LLMs across formats potentially reduces format bias. Based on our evaluation findings, we study prompting and fine-tuning with synthesized format data techniques to mitigate format bias. Our methods successfully reduce the variance in ChatGPT's performance among wrapping formats from 235.33 to 0.71 (%$^2$).
ChartQA: A Benchmark for Question Answering about Charts with Visual and Logical Reasoning
Mar 19, 2022
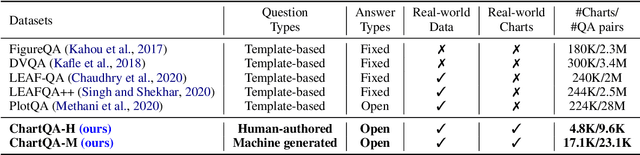
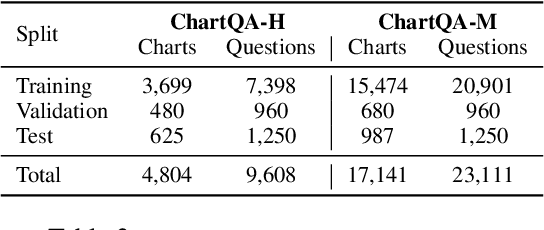

Charts are very popular for analyzing data. When exploring charts, people often ask a variety of complex reasoning questions that involve several logical and arithmetic operations. They also commonly refer to visual features of a chart in their questions. However, most existing datasets do not focus on such complex reasoning questions as their questions are template-based and answers come from a fixed-vocabulary. In this work, we present a large-scale benchmark covering 9.6K human-written questions as well as 23.1K questions generated from human-written chart summaries. To address the unique challenges in our benchmark involving visual and logical reasoning over charts, we present two transformer-based models that combine visual features and the data table of the chart in a unified way to answer questions. While our models achieve the state-of-the-art results on the previous datasets as well as on our benchmark, the evaluation also reveals several challenges in answering complex reasoning questions.