 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho's important? -- SUnSET: Synergistic Understanding of Stakeholder, Events and Time for Timeline Generation
Jul 29, 2025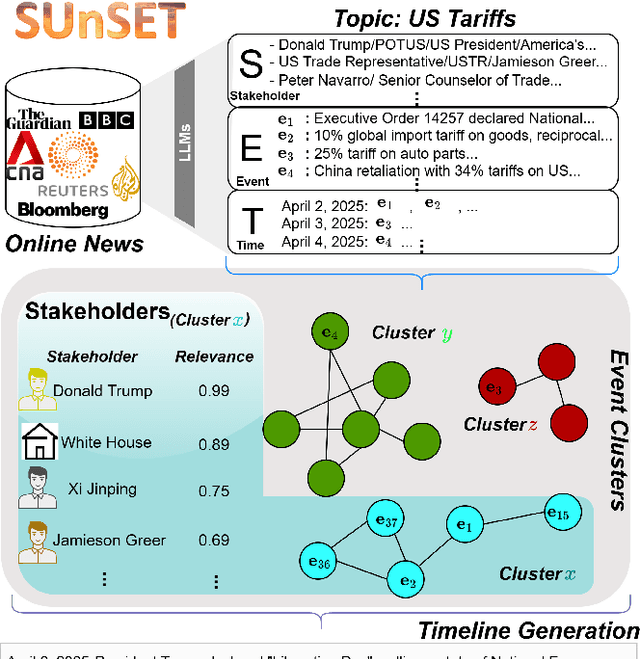
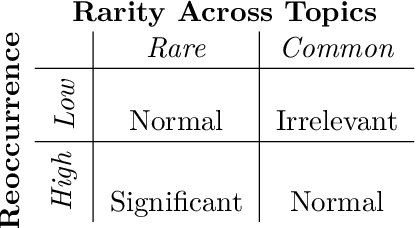
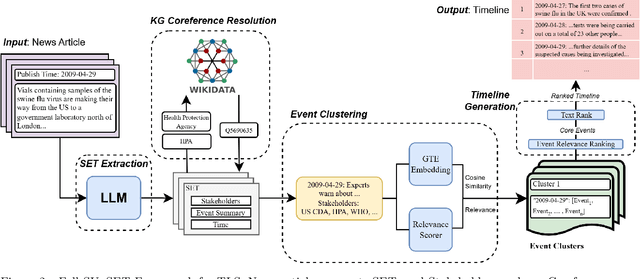
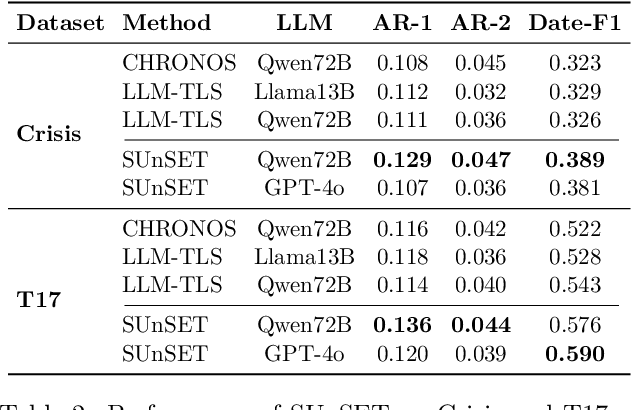
As news reporting becomes increasingly global and decentralized online, tracking related events across multiple sources presents significant challenges. Existing news summarization methods typically utilizes Large Language Models and Graphical methods on article-based summaries. However, this is not effective since it only considers the textual content of similarly dated articles to understand the gist of the event. To counteract the lack of analysis on the parties involved, it is essential to come up with a novel framework to gauge the importance of stakeholders and the connection of related events through the relevant entities involved. Therefore, we present SUnSET: Synergistic Understanding of Stakeholder, Events and Time for the task of Timeline Summarization (TLS). We leverage powerful Large Language Models (LLMs) to build SET triplets and introduced the use of stakeholder-based ranking to construct a $Relevancy$ metric, which can be extended into general situations. Our experimental results outperform all prior baselines and emerged as the new State-of-the-Art, highlighting the impact of stakeholder information within news article.
LLMs Are Biased Towards Output Formats! Systematically Evaluating and Mitigating Output Format Bias of LLMs
Aug 16, 2024We present the first systematic evaluation examining format bias in performance of large language models (LLMs). Our approach distinguishes between two categories of an evaluation metric under format constraints to reliably and accurately assess performance: one measures performance when format constraints are adhered to, while the other evaluates performance regardless of constraint adherence. We then define a metric for measuring the format bias of LLMs and establish effective strategies to reduce it. Subsequently, we present our empirical format bias evaluation spanning four commonly used categories -- multiple-choice question-answer, wrapping, list, and mapping -- covering 15 widely-used formats. Our evaluation on eight generation tasks uncovers significant format bias across state-of-the-art LLMs. We further discover that improving the format-instruction following capabilities of LLMs across formats potentially reduces format bias. Based on our evaluation findings, we study prompting and fine-tuning with synthesized format data techniques to mitigate format bias. Our methods successfully reduce the variance in ChatGPT's performance among wrapping formats from 235.33 to 0.71 (%$^2$).
Enhancing Semantic Fidelity in Text-to-Image Synthesis: Attention Regulation in Diffusion Models
Mar 11, 2024

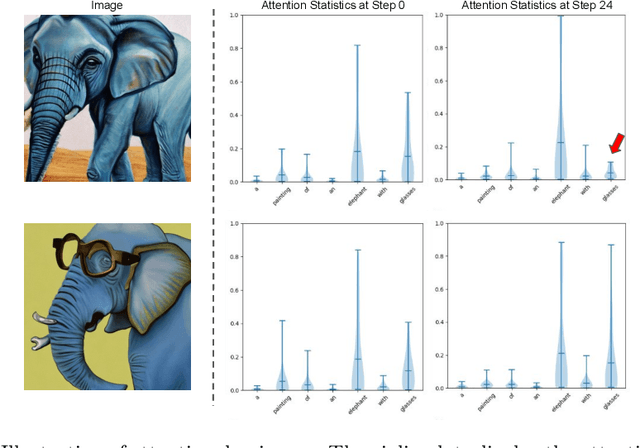

Recent advancements in diffusion models have notably improved the perceptual quality of generated images in text-to-image synthesis tasks. However, diffusion models often struggle to produce images that accurately reflect the intended semantics of the associated text prompts. We examine cross-attention layers in diffusion models and observe a propensity for these layers to disproportionately focus on certain tokens during the generation process, thereby undermining semantic fidelity. To address the issue of dominant attention, we introduce attention regulation, a computation-efficient on-the-fly optimization approach at inference time to align attention maps with the input text prompt. Notably, our method requires no additional training or fine-tuning and serves as a plug-in module on a model. Hence, the generation capacity of the original model is fully preserved. We compare our approach with alternative approaches across various datasets, evaluation metrics, and diffusion models. Experiment results show that our method consistently outperforms other baselines, yielding images that more faithfully reflect the desired concepts with reduced computation overhead. Code is available at https://github.com/YaNgZhAnG-V5/attention_regulation.