 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpistemic Context Learning: Building Trust the Right Way in LLM-Based Multi-Agent Systems
Jan 29, 2026Individual agents in multi-agent (MA) systems often lack robustness, tending to blindly conform to misleading peers. We show this weakness stems from both sycophancy and inadequate ability to evaluate peer reliability. To address this, we first formalize the learning problem of history-aware reference, introducing the historical interactions of peers as additional input, so that agents can estimate peer reliability and learn from trustworthy peers when uncertain. This shifts the task from evaluating peer reasoning quality to estimating peer reliability based on interaction history. We then develop Epistemic Context Learning (ECL): a reasoning framework that conditions predictions on explicitly-built peer profiles from history. We further optimize ECL by reinforcement learning using auxiliary rewards. Our experiments reveal that our ECL enables small models like Qwen 3-4B to outperform a history-agnostic baseline 8x its size (Qwen 3-30B) by accurately identifying reliable peers. ECL also boosts frontier models to near-perfect (100%) performance. We show that ECL generalizes well to various MA configurations and we find that trust is modeled well by LLMs, revealing a strong correlation in trust modeling accuracy and final answer quality.
Manager: Aggregating Insights from Unimodal Experts in Two-Tower VLMs and MLLMs
Jun 13, 2025Two-Tower Vision--Language Models (VLMs) have demonstrated strong performance across various downstream VL tasks. While BridgeTower further enhances performance by building bridges between encoders, it \textit{(i)} suffers from ineffective layer-by-layer utilization of unimodal representations, \textit{(ii)} restricts the flexible exploitation of different levels of unimodal semantic knowledge, and \textit{(iii)} is limited to the evaluation on traditional low-resolution datasets only with the Two-Tower VLM architecture. In this work, we propose Manager, a lightweight, efficient and effective plugin that adaptively aggregates insights from different levels of pre-trained unimodal experts to facilitate more comprehensive VL alignment and fusion. First, under the Two-Tower VLM architecture, we introduce ManagerTower, a novel VLM that introduces the manager in each cross-modal layer. Whether with or without VL pre-training, ManagerTower outperforms previous strong baselines and achieves superior performance on 4 downstream VL tasks. Moreover, we extend our exploration to the latest Multimodal Large Language Model (MLLM) architecture. We demonstrate that LLaVA-OV-Manager significantly boosts the zero-shot performance of LLaVA-OV across different categories of capabilities, images, and resolutions on 20 downstream datasets, whether the multi-grid algorithm is enabled or not. In-depth analysis reveals that both our manager and the multi-grid algorithm can be viewed as a plugin that improves the visual representation by capturing more diverse visual details from two orthogonal perspectives (depth and width). Their synergy can mitigate the semantic ambiguity caused by the multi-grid algorithm and further improve performance. Code and models are available at https://github.com/LooperXX/ManagerTower.
What Makes a Good Natural Language Prompt?
Jun 07, 2025
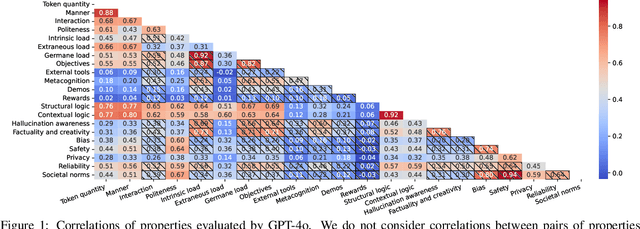
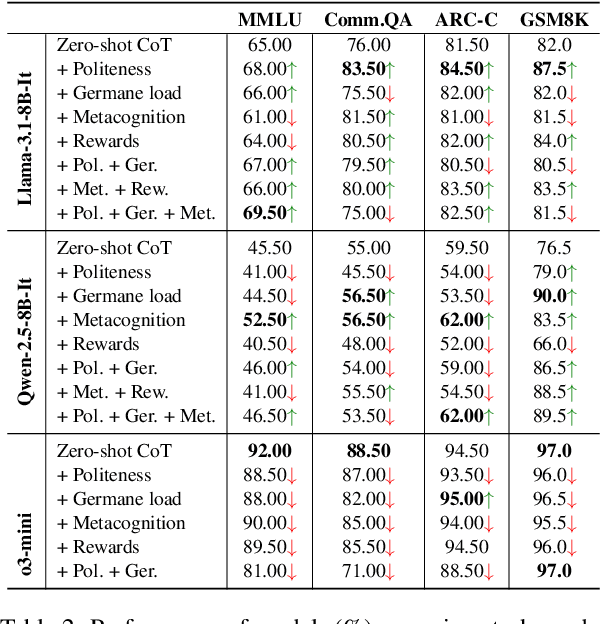
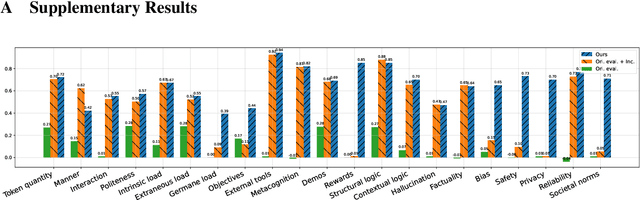
As large language models (LLMs) have progressed towards more human-like and human--AI communications have become prevalent, prompting has emerged as a decisive component. However, there is limited conceptual consensus on what exactly quantifies natural language prompts. We attempt to address this question by conducting a meta-analysis surveying more than 150 prompting-related papers from leading NLP and AI conferences from 2022 to 2025 and blogs. We propose a property- and human-centric framework for evaluating prompt quality, encompassing 21 properties categorized into six dimensions. We then examine how existing studies assess their impact on LLMs, revealing their imbalanced support across models and tasks, and substantial research gaps. Further, we analyze correlations among properties in high-quality natural language prompts, deriving prompting recommendations. We then empirically explore multi-property prompt enhancements in reasoning tasks, observing that single-property enhancements often have the greatest impact. Finally, we discover that instruction-tuning on property-enhanced prompts can result in better reasoning models. Our findings establish a foundation for property-centric prompt evaluation and optimization, bridging the gaps between human--AI communication and opening new prompting research directions.
Seeing Through Deception: Uncovering Misleading Creator Intent in Multimodal News with Vision-Language Models
May 21, 2025The real-world impact of misinformation stems from the underlying misleading narratives that creators seek to convey. As such, interpreting misleading creator intent is essential for multimodal misinformation detection (MMD) systems aimed at effective information governance. In this paper, we introduce an automated framework that simulates real-world multimodal news creation by explicitly modeling creator intent through two components: the desired influence and the execution plan. Using this framework, we construct DeceptionDecoded, a large-scale benchmark comprising 12,000 image-caption pairs aligned with trustworthy reference articles. The dataset captures both misleading and non-misleading intents and spans manipulations across visual and textual modalities. We conduct a comprehensive evaluation of 14 state-of-the-art vision-language models (VLMs) on three intent-centric tasks: (1) misleading intent detection, (2) misleading source attribution, and (3) creator desire inference. Despite recent advances, we observe that current VLMs fall short in recognizing misleading intent, often relying on spurious cues such as superficial cross-modal consistency, stylistic signals, and heuristic authenticity hints. Our findings highlight the pressing need for intent-aware modeling in MMD and open new directions for developing systems capable of deeper reasoning about multimodal misinformation.
Toward Generalizable Evaluation in the LLM Era: A Survey Beyond Benchmarks
Apr 26, 2025



Large Language Models (LLMs) are advancing at an amazing speed and have become indispensable across academia, industry, and daily applications. To keep pace with the status quo, this survey probes the core challenges that the rise of LLMs poses for evaluation. We identify and analyze two pivotal transitions: (i) from task-specific to capability-based evaluation, which reorganizes benchmarks around core competencies such as knowledge, reasoning, instruction following, multi-modal understanding, and safety; and (ii) from manual to automated evaluation, encompassing dynamic dataset curation and "LLM-as-a-judge" scoring. Yet, even with these transitions, a crucial obstacle persists: the evaluation generalization issue. Bounded test sets cannot scale alongside models whose abilities grow seemingly without limit. We will dissect this issue, along with the core challenges of the above two transitions, from the perspectives of methods, datasets, evaluators, and metrics. Due to the fast evolving of this field, we will maintain a living GitHub repository (links are in each section) to crowd-source updates and corrections, and warmly invite contributors and collaborators.
SkyLadder: Better and Faster Pretraining via Context Window Scheduling
Mar 19, 2025



Recent advancements in LLM pretraining have featured ever-expanding context windows to process longer sequences. However, our pilot study reveals that models pretrained with shorter context windows consistently outperform their long-context counterparts under a fixed token budget. This finding motivates us to explore an optimal context window scheduling strategy to better balance long-context capability with pretraining efficiency. To this end, we propose SkyLadder, a simple yet effective approach that implements a short-to-long context window transition. SkyLadder preserves strong standard benchmark performance, while matching or exceeding baseline results on long context tasks. Through extensive experiments, we pre-train 1B-parameter models (up to 32K context) and 3B-parameter models (8K context) on 100B tokens, demonstrating that SkyLadder yields consistent gains of up to 3.7% on common benchmarks, while achieving up to 22% faster training speeds compared to baselines. The code is at https://github.com/sail-sg/SkyLadder.
Evaluating Sakana's AI Scientist for Autonomous Research: Wishful Thinking or an Emerging Reality Towards 'Artificial Research Intelligence' (ARI)?
Feb 22, 2025A major step toward Artificial General Intelligence (AGI) and Super Intelligence is AI's ability to autonomously conduct research - what we term Artificial Research Intelligence (ARI). If machines could generate hypotheses, conduct experiments, and write research papers without human intervention, it would transform science. Sakana recently introduced the 'AI Scientist', claiming to conduct research autonomously, i.e. they imply to have achieved what we term Artificial Research Intelligence (ARI). The AI Scientist gained much attention, but a thorough independent evaluation has yet to be conducted. Our evaluation of the AI Scientist reveals critical shortcomings. The system's literature reviews produced poor novelty assessments, often misclassifying established concepts (e.g., micro-batching for stochastic gradient descent) as novel. It also struggles with experiment execution: 42% of experiments failed due to coding errors, while others produced flawed or misleading results. Code modifications were minimal, averaging 8% more characters per iteration, suggesting limited adaptability. Generated manuscripts were poorly substantiated, with a median of five citations, most outdated (only five of 34 from 2020 or later). Structural errors were frequent, including missing figures, repeated sections, and placeholder text like 'Conclusions Here'. Some papers contained hallucinated numerical results. Despite these flaws, the AI Scientist represents a leap forward in research automation. It generates full research manuscripts with minimal human input, challenging expectations of AI-driven science. Many reviewers might struggle to distinguish its work from human researchers. While its quality resembles a rushed undergraduate paper, its speed and cost efficiency are unprecedented, producing a full paper for USD 6 to 15 with 3.5 hours of human involvement, far outpacing traditional researchers.
Exploring Multi-Grained Concept Annotations for Multimodal Large Language Models
Dec 08, 2024



Multimodal Large Language Models (MLLMs) excel in vision--language tasks by pre-training solely on coarse-grained concept annotations (e.g., image captions). We hypothesize that integrating fine-grained concept annotations (e.g., object labels and object regions) will further improve performance, as both data granularities complement each other in terms of breadth and depth in concept representation. We introduce a new dataset featuring Multimodal Multi-Grained Concept annotations (MMGiC) for MLLMs. In constructing MMGiC, we explore the impact of different data recipes on multimodal comprehension and generation. Our analyses reveal that multi-grained concept annotations integrate and complement each other, under our structured template and a general MLLM framework. We clearly explore and demonstrate the potential of MMGiC to help MLLMs better locate and learn concepts, aligning vision and language at multiple granularities. We further validate our hypothesis by investigating the fair comparison and effective collaboration between MMGiC and image--caption data on 12 multimodal comprehension and generation benchmarks, e.g., their appropriate combination achieve 3.95% and 2.34% absolute improvements over image--caption data alone on POPE and SEED-Bench. Code, data and models will be available at https://github.com/LooperXX/MMGiC.
Reasoning Robustness of LLMs to Adversarial Typographical Errors
Nov 08, 2024



Large Language Models (LLMs) have demonstrated impressive capabilities in reasoning using Chain-of-Thought (CoT) prompting. However, CoT can be biased by users' instruction. In this work, we study the reasoning robustness of LLMs to typographical errors, which can naturally occur in users' queries. We design an Adversarial Typo Attack ($\texttt{ATA}$) algorithm that iteratively samples typos for words that are important to the query and selects the edit that is most likely to succeed in attacking. It shows that LLMs are sensitive to minimal adversarial typographical changes. Notably, with 1 character edit, Mistral-7B-Instruct's accuracy drops from 43.7% to 38.6% on GSM8K, while with 8 character edits the performance further drops to 19.2%. To extend our evaluation to larger and closed-source LLMs, we develop the $\texttt{R$^2$ATA}$ benchmark, which assesses models' $\underline{R}$easoning $\underline{R}$obustness to $\underline{\texttt{ATA}}$. It includes adversarial typographical questions derived from three widely used reasoning datasets-GSM8K, BBH, and MMLU-by applying $\texttt{ATA}$ to open-source LLMs. $\texttt{R$^2$ATA}$ demonstrates remarkable transferability and causes notable performance drops across multiple super large and closed-source LLMs.
V-DPO: Mitigating Hallucination in Large Vision Language Models via Vision-Guided Direct Preference Optimization
Nov 05, 2024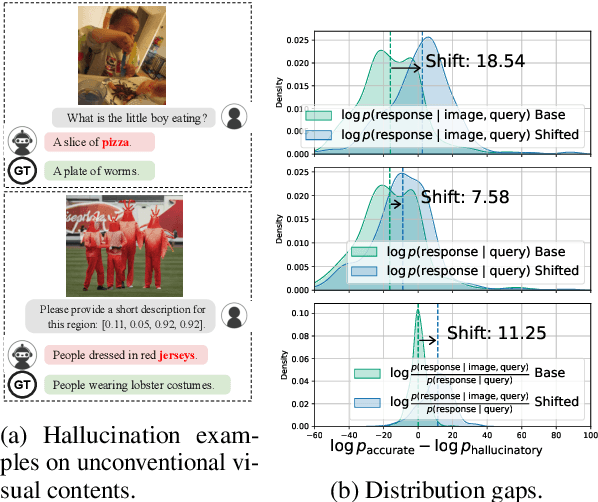
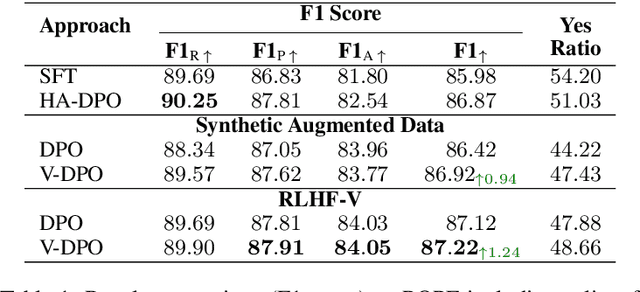
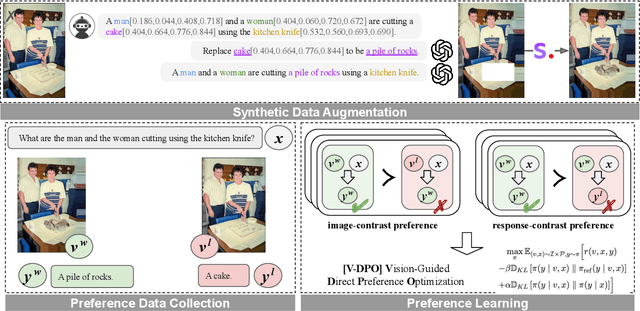
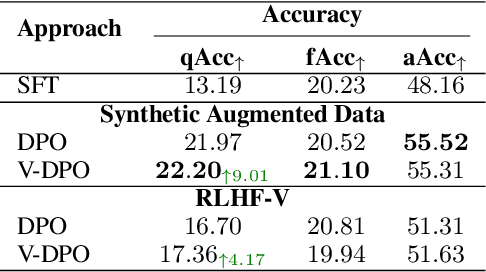
Large vision-language models (LVLMs) suffer from hallucination, resulting in misalignment between the output textual response and the input visual content. Recent research indicates that the over-reliance on the Large Language Model (LLM) backbone, as one cause of the LVLM hallucination, inherently introduces bias from language priors, leading to insufficient context attention to the visual inputs. We tackle this issue of hallucination by mitigating such over-reliance through preference learning. We propose Vision-guided Direct Preference Optimization (V-DPO) to enhance visual context learning at training time. To interpret the effectiveness and generalizability of V-DPO on different types of training data, we construct a synthetic dataset containing both response- and image-contrast preference pairs, compared against existing human-annotated hallucination samples. Our approach achieves significant improvements compared with baseline methods across various hallucination benchmarks. Our analysis indicates that V-DPO excels in learning from image-contrast preference data, demonstrating its superior ability to elicit and understand nuances of visual context. Our code is publicly available at https://github.com/YuxiXie/V-DPO.