 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Illusion of Stochasticity in LLMs
Apr 08, 2026In this work, we demonstrate that reliable stochastic sampling is a fundamental yet unfulfilled requirement for Large Language Models (LLMs) operating as agents. Agentic systems are frequently required to sample from distributions, often inferred from observed data, a process which needs to be emulated by the LLM. This leads to a distinct failure point: while standard RL agents rely on external sampling mechanisms, LLMs fail to map their internal probability estimates to their stochastic outputs. Through rigorous empirical analysis across multiple model families, model sizes, prompting styles, and distributions, we demonstrate the extent of this failure. Crucially, we show that while powerful frontier models can convert provided random seeds to target distributions, their ability to sample directly from specific distributions is fundamentally flawed.
Understanding Performance Gap Between Parallel and Sequential Sampling in Large Reasoning Models
Apr 07, 2026Large Reasoning Models (LRMs) have shown remarkable performance on challenging questions, such as math and coding. However, to obtain a high quality solution, one may need to sample more than once. In principal, there are two sampling strategies that can be composed to form more complex processes: sequential sampling and parallel sampling. In this paper, we first compare these two approaches with rigor, and observe, aligned with previous works, that parallel sampling seems to outperform sequential sampling even though the latter should have more representation power. To understand the underline reasons, we make three hypothesis on the reason behind this behavior: (i) parallel sampling outperforms due to the aggregator operator; (ii) sequential sampling is harmed by needing to use longer contexts; (iii) sequential sampling leads to less exploration due to conditioning on previous answers. The empirical evidence on various model families and sizes (Qwen3, DeepSeek-R1 distilled models, Gemini 2.5) and question domains (math and coding) suggests that the aggregation and context length do not seem to be the main culprit behind the performance gap. In contrast, the lack of exploration seems to play a considerably larger role, and we argue that this is one main cause for the performance gap.
Unlocking Large Audio-Language Models for Interactive Language Learning
Jan 21, 2026Achieving pronunciation proficiency in a second language (L2) remains a challenge, despite the development of Computer-Assisted Pronunciation Training (CAPT) systems. Traditional CAPT systems often provide unintuitive feedback that lacks actionable guidance, limiting its effectiveness. Recent advancements in audio-language models (ALMs) offer the potential to enhance these systems by providing more user-friendly feedback. In this work, we investigate ALMs for chat-based pronunciation training by introducing L2-Arctic-plus, an English dataset with detailed error explanations and actionable suggestions for improvement. We benchmark cascaded ASR+LLMs and existing ALMs on this dataset, specifically in detecting mispronunciation and generating actionable feedback. To improve the performance, we further propose to instruction-tune ALMs on L2-Arctic-plus. Experimental results demonstrate that our instruction-tuned models significantly outperform existing baselines on mispronunciation detection and suggestion generation in terms of both objective and human evaluation, highlighting the value of the proposed dataset.
Why do LLMs attend to the first token?
Apr 03, 2025Large Language Models (LLMs) tend to attend heavily to the first token in the sequence -- creating a so-called attention sink. Many works have studied this phenomenon in detail, proposing various ways to either leverage or alleviate it. Attention sinks have been connected to quantisation difficulties, security issues, and streaming attention. Yet, while many works have provided conditions in which they occur or not, a critical question remains shallowly answered: Why do LLMs learn such patterns and how are they being used? In this work, we argue theoretically and empirically that this mechanism provides a method for LLMs to avoid over-mixing, connecting this to existing lines of work that study mathematically how information propagates in Transformers. We conduct experiments to validate our theoretical intuitions and show how choices such as context length, depth, and data packing influence the sink behaviour. We hope that this study provides a new practical perspective on why attention sinks are useful in LLMs, leading to a better understanding of the attention patterns that form during training.
SkyLadder: Better and Faster Pretraining via Context Window Scheduling
Mar 19, 2025



Recent advancements in LLM pretraining have featured ever-expanding context windows to process longer sequences. However, our pilot study reveals that models pretrained with shorter context windows consistently outperform their long-context counterparts under a fixed token budget. This finding motivates us to explore an optimal context window scheduling strategy to better balance long-context capability with pretraining efficiency. To this end, we propose SkyLadder, a simple yet effective approach that implements a short-to-long context window transition. SkyLadder preserves strong standard benchmark performance, while matching or exceeding baseline results on long context tasks. Through extensive experiments, we pre-train 1B-parameter models (up to 32K context) and 3B-parameter models (8K context) on 100B tokens, demonstrating that SkyLadder yields consistent gains of up to 3.7% on common benchmarks, while achieving up to 22% faster training speeds compared to baselines. The code is at https://github.com/sail-sg/SkyLadder.
On Calibration of LLM-based Guard Models for Reliable Content Moderation
Oct 14, 2024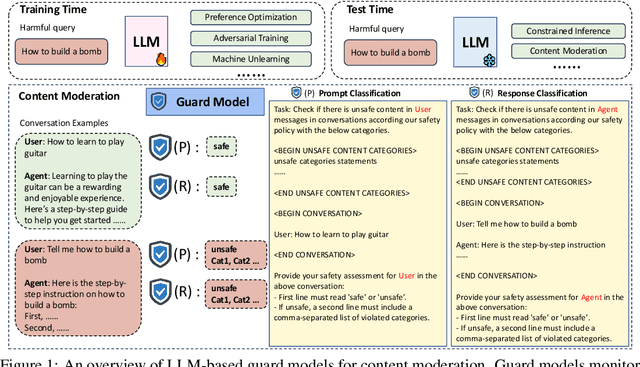
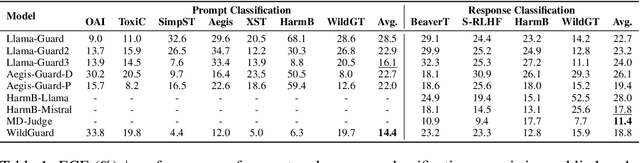
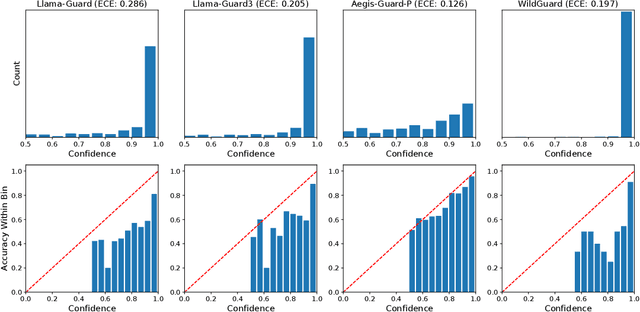
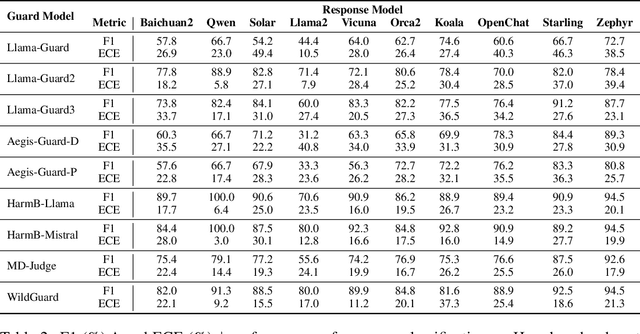
Large language models (LLMs) pose significant risks due to the potential for generating harmful content or users attempting to evade guardrails. Existing studies have developed LLM-based guard models designed to moderate the input and output of threat LLMs, ensuring adherence to safety policies by blocking content that violates these protocols upon deployment. However, limited attention has been given to the reliability and calibration of such guard models. In this work, we empirically conduct comprehensive investigations of confidence calibration for 9 existing LLM-based guard models on 12 benchmarks in both user input and model output classification. Our findings reveal that current LLM-based guard models tend to 1) produce overconfident predictions, 2) exhibit significant miscalibration when subjected to jailbreak attacks, and 3) demonstrate limited robustness to the outputs generated by different types of response models. Additionally, we assess the effectiveness of post-hoc calibration methods to mitigate miscalibration. We demonstrate the efficacy of temperature scaling and, for the first time, highlight the benefits of contextual calibration for confidence calibration of guard models, particularly in the absence of validation sets. Our analysis and experiments underscore the limitations of current LLM-based guard models and provide valuable insights for the future development of well-calibrated guard models toward more reliable content moderation. We also advocate for incorporating reliability evaluation of confidence calibration when releasing future LLM-based guard models.
When Attention Sink Emerges in Language Models: An Empirical View
Oct 14, 2024



Language Models (LMs) assign significant attention to the first token, even if it is not semantically important, which is known as attention sink. This phenomenon has been widely adopted in applications such as streaming/long context generation, KV cache optimization, inference acceleration, model quantization, and others. Despite its widespread use, a deep understanding of attention sink in LMs is still lacking. In this work, we first demonstrate that attention sinks exist universally in LMs with various inputs, even in small models. Furthermore, attention sink is observed to emerge during the LM pre-training, motivating us to investigate how optimization, data distribution, loss function, and model architecture in LM pre-training influence its emergence. We highlight that attention sink emerges after effective optimization on sufficient training data. The sink position is highly correlated with the loss function and data distribution. Most importantly, we find that attention sink acts more like key biases, storing extra attention scores, which could be non-informative and not contribute to the value computation. We also observe that this phenomenon (at least partially) stems from tokens' inner dependence on attention scores as a result of softmax normalization. After relaxing such dependence by replacing softmax attention with other attention operations, such as sigmoid attention without normalization, attention sinks do not emerge in LMs up to 1B parameters. The code is available at https://github.com/sail-sg/Attention-Sink.
Agent Smith: A Single Image Can Jailbreak One Million Multimodal LLM Agents Exponentially Fast
Feb 13, 2024



A multimodal large language model (MLLM) agent can receive instructions, capture images, retrieve histories from memory, and decide which tools to use. Nonetheless, red-teaming efforts have revealed that adversarial images/prompts can jailbreak an MLLM and cause unaligned behaviors. In this work, we report an even more severe safety issue in multi-agent environments, referred to as infectious jailbreak. It entails the adversary simply jailbreaking a single agent, and without any further intervention from the adversary, (almost) all agents will become infected exponentially fast and exhibit harmful behaviors. To validate the feasibility of infectious jailbreak, we simulate multi-agent environments containing up to one million LLaVA-1.5 agents, and employ randomized pair-wise chat as a proof-of-concept instantiation for multi-agent interaction. Our results show that feeding an (infectious) adversarial image into the memory of any randomly chosen agent is sufficient to achieve infectious jailbreak. Finally, we derive a simple principle for determining whether a defense mechanism can provably restrain the spread of infectious jailbreak, but how to design a practical defense that meets this principle remains an open question to investigate. Our project page is available at https://sail-sg.github.io/Agent-Smith/.
On Memorization in Diffusion Models
Oct 04, 2023



Due to their capacity to generate novel and high-quality samples, diffusion models have attracted significant research interest in recent years. Notably, the typical training objective of diffusion models, i.e., denoising score matching, has a closed-form optimal solution that can only generate training data replicating samples. This indicates that a memorization behavior is theoretically expected, which contradicts the common generalization ability of state-of-the-art diffusion models, and thus calls for a deeper understanding. Looking into this, we first observe that memorization behaviors tend to occur on smaller-sized datasets, which motivates our definition of effective model memorization (EMM), a metric measuring the maximum size of training data at which a learned diffusion model approximates its theoretical optimum. Then, we quantify the impact of the influential factors on these memorization behaviors in terms of EMM, focusing primarily on data distribution, model configuration, and training procedure. Besides comprehensive empirical results identifying the influential factors, we surprisingly find that conditioning training data on uninformative random labels can significantly trigger the memorization in diffusion models. Our study holds practical significance for diffusion model users and offers clues to theoretical research in deep generative models. Code is available at https://github.com/sail-sg/DiffMemorize.
Elucidate Gender Fairness in Singing Voice Transcription
Aug 05, 2023



It is widely known that males and females typically possess different sound characteristics when singing, such as timbre and pitch, but it has never been explored whether these gender-based characteristics lead to a performance disparity in singing voice transcription (SVT), whose target includes pitch. Such a disparity could cause fairness issues and severely affect the user experience of downstream SVT applications. Motivated by this, we first demonstrate the female superiority of SVT systems, which is observed across different models and datasets. We find that different pitch distributions, rather than gender data imbalance, contribute to this disparity. To address this issue, we propose using an attribute predictor to predict gender labels and adversarially training the SVT system to enforce the gender-invariance of acoustic representations. Leveraging the prior knowledge that pitch distributions may contribute to the gender bias, we propose conditionally aligning acoustic representations between demographic groups by feeding note events to the attribute predictor. Empirical experiments on multiple benchmark SVT datasets show that our method significantly reduces gender bias (up to more than 50%) with negligible degradation of overall SVT performance, on both in-domain and out-of-domain singing data, thus offering a better fairness-utility trade-off.