 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnealed Relaxation of Speculative Decoding for Faster Autoregressive Image Generation
Jan 14, 2026Despite significant progress in autoregressive image generation, inference remains slow due to the sequential nature of AR models and the ambiguity of image tokens, even when using speculative decoding. Recent works attempt to address this with relaxed speculative decoding but lack theoretical grounding. In this paper, we establish the theoretical basis of relaxed SD and propose COOL-SD, an annealed relaxation of speculative decoding built on two key insights. The first analyzes the total variation (TV) distance between the target model and relaxed speculative decoding and yields an optimal resampling distribution that minimizes an upper bound of the distance. The second uses perturbation analysis to reveal an annealing behaviour in relaxed speculative decoding, motivating our annealed design. Together, these insights enable COOL-SD to generate images faster with comparable quality, or achieve better quality at similar latency. Experiments validate the effectiveness of COOL-SD, showing consistent improvements over prior methods in speed-quality trade-offs.
Demystifying the Slash Pattern in Attention: The Role of RoPE
Jan 13, 2026Large Language Models (LLMs) often exhibit slash attention patterns, where attention scores concentrate along the $Δ$-th sub-diagonal for some offset $Δ$. These patterns play a key role in passing information across tokens. But why do they emerge? In this paper, we demystify the emergence of these Slash-Dominant Heads (SDHs) from both empirical and theoretical perspectives. First, by analyzing open-source LLMs, we find that SDHs are intrinsic to models and generalize to out-of-distribution prompts. To explain the intrinsic emergence, we analyze the queries, keys, and Rotary Position Embedding (RoPE), which jointly determine attention scores. Our empirical analysis reveals two characteristic conditions of SDHs: (1) Queries and keys are almost rank-one, and (2) RoPE is dominated by medium- and high-frequency components. Under these conditions, queries and keys are nearly identical across tokens, and interactions between medium- and high-frequency components of RoPE give rise to SDHs. Beyond empirical evidence, we theoretically show that these conditions are sufficient to ensure the emergence of SDHs by formalizing them as our modeling assumptions. Particularly, we analyze the training dynamics of a shallow Transformer equipped with RoPE under these conditions, and prove that models trained via gradient descent exhibit SDHs. The SDHs generalize to out-of-distribution prompts.
Sparse-to-Dense: A Free Lunch for Lossless Acceleration of Video Understanding in LLMs
May 25, 2025Due to the auto-regressive nature of current video large language models (Video-LLMs), the inference latency increases as the input sequence length grows, posing challenges for the efficient processing of video sequences that are usually very long. We observe that during decoding, the attention scores of most tokens in Video-LLMs tend to be sparse and concentrated, with only certain tokens requiring comprehensive full attention. Based on this insight, we introduce Sparse-to-Dense (StD), a novel decoding strategy that integrates two distinct modules: one leveraging sparse top-K attention and the other employing dense full attention. These modules collaborate to accelerate Video-LLMs without loss. The fast (sparse) model speculatively decodes multiple tokens, while the slow (dense) model verifies them in parallel. StD is a tuning-free, plug-and-play solution that achieves up to a 1.94$\times$ walltime speedup in video processing. It maintains model performance while enabling a seamless transition from a standard Video-LLM to a sparse Video-LLM with minimal code modifications.
BanditSpec: Adaptive Speculative Decoding via Bandit Algorithms
May 21, 2025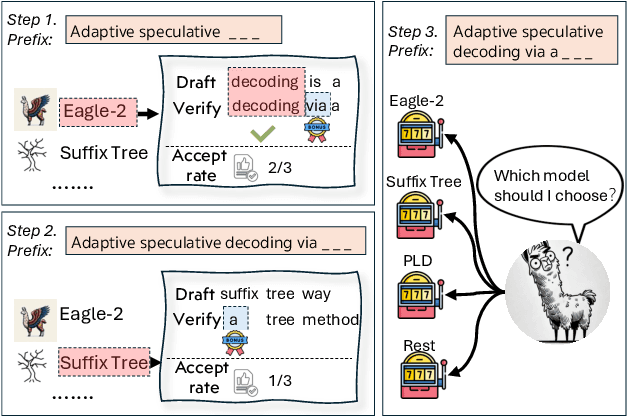
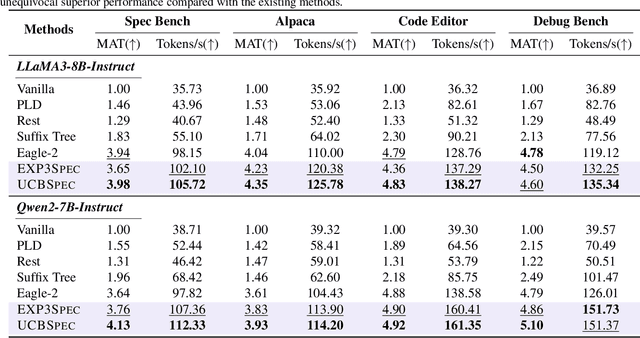
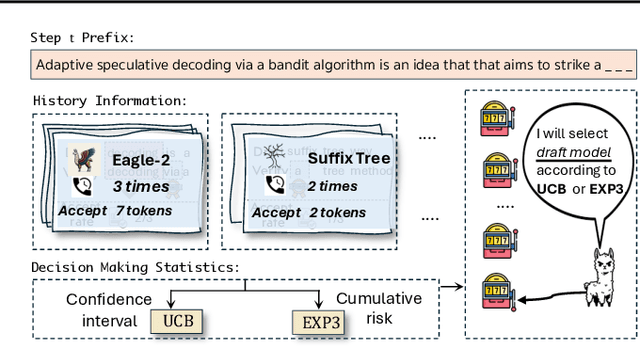
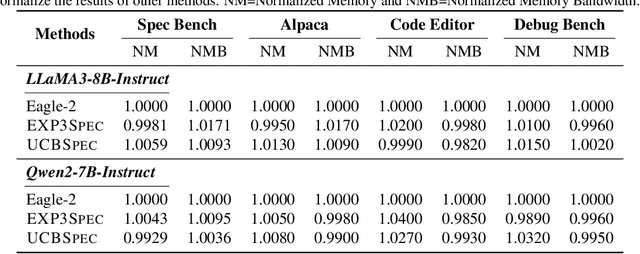
Speculative decoding has emerged as a popular method to accelerate the inference of Large Language Models (LLMs) while retaining their superior text generation performance. Previous methods either adopt a fixed speculative decoding configuration regardless of the prefix tokens, or train draft models in an offline or online manner to align them with the context. This paper proposes a training-free online learning framework to adaptively choose the configuration of the hyperparameters for speculative decoding as text is being generated. We first formulate this hyperparameter selection problem as a Multi-Armed Bandit problem and provide a general speculative decoding framework BanditSpec. Furthermore, two bandit-based hyperparameter selection algorithms, UCBSpec and EXP3Spec, are designed and analyzed in terms of a novel quantity, the stopping time regret. We upper bound this regret under both stochastic and adversarial reward settings. By deriving an information-theoretic impossibility result, it is shown that the regret performance of UCBSpec is optimal up to universal constants. Finally, extensive empirical experiments with LLaMA3 and Qwen2 demonstrate that our algorithms are effective compared to existing methods, and the throughput is close to the oracle best hyperparameter in simulated real-life LLM serving scenarios with diverse input prompts.
LongSpec: Long-Context Speculative Decoding with Efficient Drafting and Verification
Feb 24, 2025
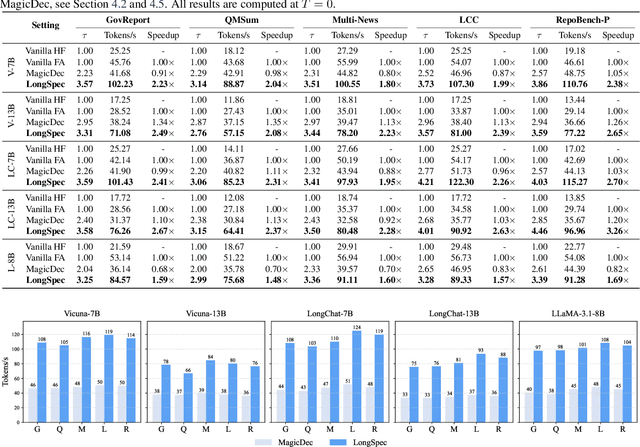
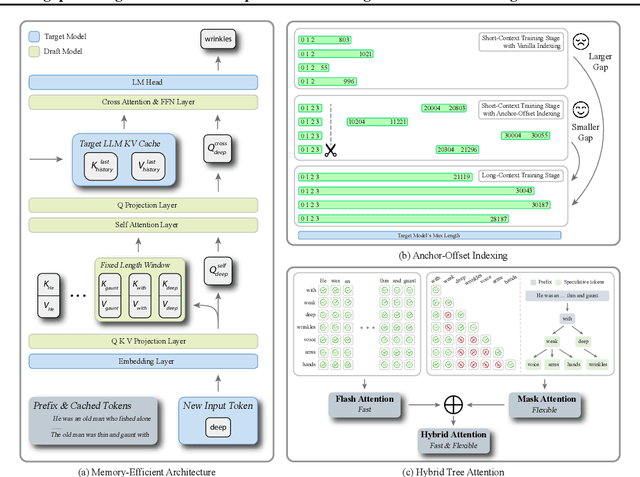
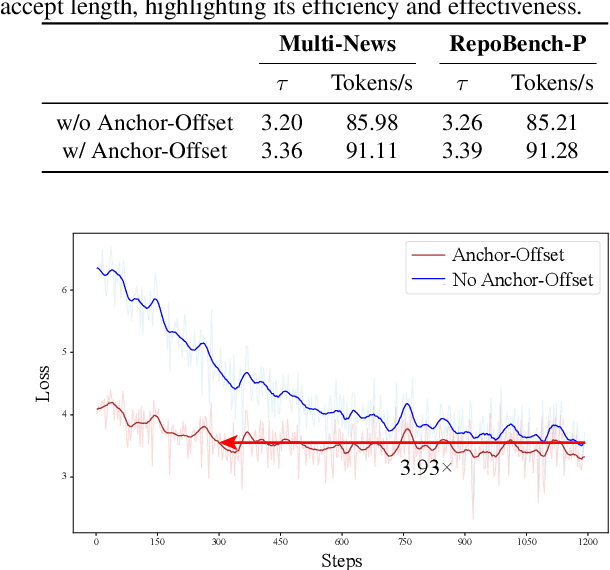
Speculative decoding has become a promising technique to mitigate the high inference latency of autoregressive decoding in Large Language Models (LLMs). Despite its promise, the effective application of speculative decoding in LLMs still confronts three key challenges: the increasing memory demands of the draft model, the distribution shift between the short-training corpora and long-context inference, and inefficiencies in attention implementation. In this work, we enhance the performance of speculative decoding in long-context settings by addressing these challenges. First, we propose a memory-efficient draft model with a constant-sized Key-Value (KV) cache. Second, we introduce novel position indices for short-training data, enabling seamless adaptation from short-context training to long-context inference. Finally, we present an innovative attention aggregation method that combines fast implementations for prefix computation with standard attention for tree mask handling, effectively resolving the latency and memory inefficiencies of tree decoding. Our approach achieves strong results on various long-context tasks, including repository-level code completion, long-context summarization, and o1-like long reasoning tasks, demonstrating significant improvements in latency reduction. The code is available at https://github.com/sail-sg/LongSpec.
Enhancing Multi-Text Long Video Generation Consistency without Tuning: Time-Frequency Analysis, Prompt Alignment, and Theory
Dec 23, 2024
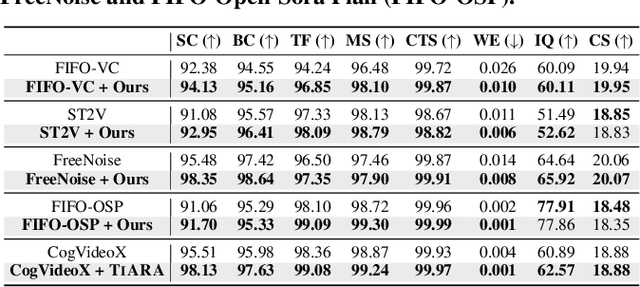
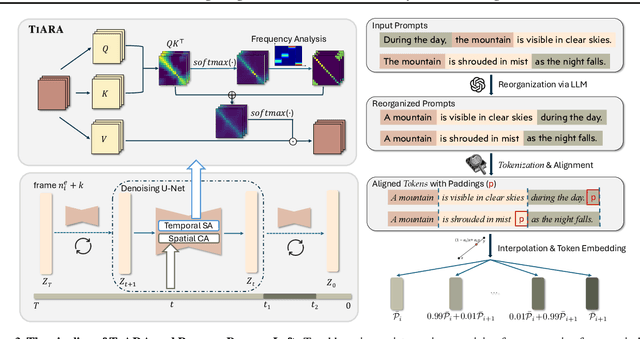
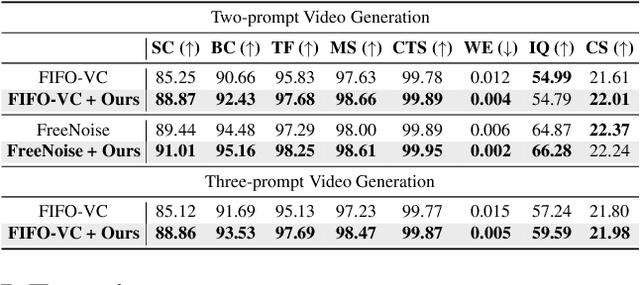
Despite the considerable progress achieved in the long video generation problem, there is still significant room to improve the consistency of the videos, particularly in terms of smoothness and transitions between scenes. We address these issues to enhance the consistency and coherence of videos generated with either single or multiple prompts. We propose the Time-frequency based temporal Attention Reweighting Algorithm (TiARA), which meticulously edits the attention score matrix based on the Discrete Short-Time Fourier Transform. Our method is supported by a theoretical guarantee, the first-of-its-kind for frequency-based methods in diffusion models. For videos generated by multiple prompts, we further investigate key factors affecting prompt interpolation quality and propose PromptBlend, an advanced prompt interpolation pipeline. The efficacy of our proposed method is validated via extensive experimental results, exhibiting consistent and impressive improvements over baseline methods. The code will be released upon acceptance.
When Attention Sink Emerges in Language Models: An Empirical View
Oct 14, 2024



Language Models (LMs) assign significant attention to the first token, even if it is not semantically important, which is known as attention sink. This phenomenon has been widely adopted in applications such as streaming/long context generation, KV cache optimization, inference acceleration, model quantization, and others. Despite its widespread use, a deep understanding of attention sink in LMs is still lacking. In this work, we first demonstrate that attention sinks exist universally in LMs with various inputs, even in small models. Furthermore, attention sink is observed to emerge during the LM pre-training, motivating us to investigate how optimization, data distribution, loss function, and model architecture in LM pre-training influence its emergence. We highlight that attention sink emerges after effective optimization on sufficient training data. The sink position is highly correlated with the loss function and data distribution. Most importantly, we find that attention sink acts more like key biases, storing extra attention scores, which could be non-informative and not contribute to the value computation. We also observe that this phenomenon (at least partially) stems from tokens' inner dependence on attention scores as a result of softmax normalization. After relaxing such dependence by replacing softmax attention with other attention operations, such as sigmoid attention without normalization, attention sinks do not emerge in LMs up to 1B parameters. The code is available at https://github.com/sail-sg/Attention-Sink.
Unveiling the Statistical Foundations of Chain-of-Thought Prompting Methods
Aug 25, 2024



Chain-of-Thought (CoT) prompting and its variants have gained popularity as effective methods for solving multi-step reasoning problems using pretrained large language models (LLMs). In this work, we analyze CoT prompting from a statistical estimation perspective, providing a comprehensive characterization of its sample complexity. To this end, we introduce a multi-step latent variable model that encapsulates the reasoning process, where the latent variable encodes the task information. Under this framework, we demonstrate that when the pretraining dataset is sufficiently large, the estimator formed by CoT prompting is equivalent to a Bayesian estimator. This estimator effectively solves the multi-step reasoning problem by aggregating a posterior distribution inferred from the demonstration examples in the prompt. Moreover, we prove that the statistical error of the CoT estimator can be decomposed into two main components: (i) a prompting error, which arises from inferring the true task using CoT prompts, and (ii) the statistical error of the pretrained LLM. We establish that, under appropriate assumptions, the prompting error decays exponentially to zero as the number of demonstrations increases. Additionally, we explicitly characterize the approximation and generalization errors of the pretrained LLM. Notably, we construct a transformer model that approximates the target distribution of the multi-step reasoning problem with an error that decreases exponentially in the number of transformer blocks. Our analysis extends to other variants of CoT, including Self-Consistent CoT, Tree-of-Thought, and Selection-Inference, offering a broad perspective on the efficacy of these methods. We also provide numerical experiments to validate the theoretical findings.
From Words to Actions: Unveiling the Theoretical Underpinnings of LLM-Driven Autonomous Systems
May 30, 2024In this work, from a theoretical lens, we aim to understand why large language model (LLM) empowered agents are able to solve decision-making problems in the physical world. To this end, consider a hierarchical reinforcement learning (RL) model where the LLM Planner and the Actor perform high-level task planning and low-level execution, respectively. Under this model, the LLM Planner navigates a partially observable Markov decision process (POMDP) by iteratively generating language-based subgoals via prompting. Under proper assumptions on the pretraining data, we prove that the pretrained LLM Planner effectively performs Bayesian aggregated imitation learning (BAIL) through in-context learning. Additionally, we highlight the necessity for exploration beyond the subgoals derived from BAIL by proving that naively executing the subgoals returned by LLM leads to a linear regret. As a remedy, we introduce an $\epsilon$-greedy exploration strategy to BAIL, which is proven to incur sublinear regret when the pretraining error is small. Finally, we extend our theoretical framework to include scenarios where the LLM Planner serves as a world model for inferring the transition model of the environment and to multi-agent settings, enabling coordination among multiple Actors.
Learning Regularized Graphon Mean-Field Games with Unknown Graphons
Oct 26, 2023

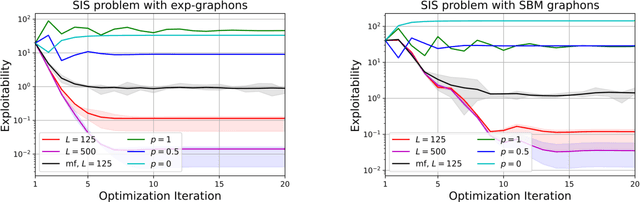
We design and analyze reinforcement learning algorithms for Graphon Mean-Field Games (GMFGs). In contrast to previous works that require the precise values of the graphons, we aim to learn the Nash Equilibrium (NE) of the regularized GMFGs when the graphons are unknown. Our contributions are threefold. First, we propose the Proximal Policy Optimization for GMFG (GMFG-PPO) algorithm and show that it converges at a rate of $O(T^{-1/3})$ after $T$ iterations with an estimation oracle, improving on a previous work by Xie et al. (ICML, 2021). Second, using kernel embedding of distributions, we design efficient algorithms to estimate the transition kernels, reward functions, and graphons from sampled agents. Convergence rates are then derived when the positions of the agents are either known or unknown. Results for the combination of the optimization algorithm GMFG-PPO and the estimation algorithm are then provided. These algorithms are the first specifically designed for learning graphons from sampled agents. Finally, the efficacy of the proposed algorithms are corroborated through simulations. These simulations demonstrate that learning the unknown graphons reduces the exploitability effectively.