 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWEAVE: Unleashing and Benchmarking the In-context Interleaved Comprehension and Generation
Nov 14, 2025
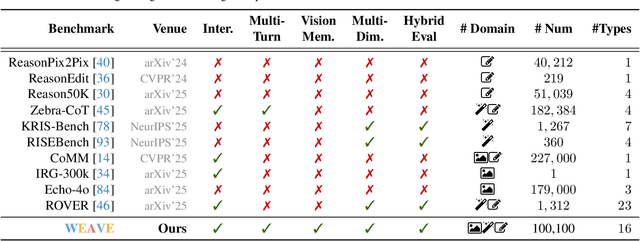
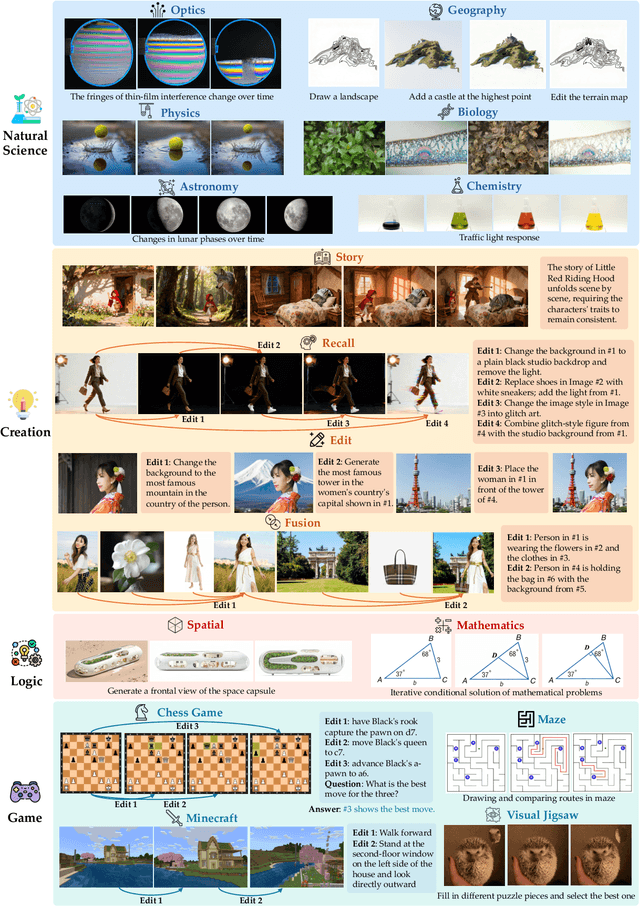

Recent advances in unified multimodal models (UMMs) have enabled impressive progress in visual comprehension and generation. However, existing datasets and benchmarks focus primarily on single-turn interactions, failing to capture the multi-turn, context-dependent nature of real-world image creation and editing. To address this gap, we present WEAVE, the first suite for in-context interleaved cross-modality comprehension and generation. Our suite consists of two complementary parts. WEAVE-100k is a large-scale dataset of 100K interleaved samples spanning over 370K dialogue turns and 500K images, covering comprehension, editing, and generation tasks that require reasoning over historical context. WEAVEBench is a human-annotated benchmark with 100 tasks based on 480 images, featuring a hybrid VLM judger evaluation framework based on both the reference image and the combination of the original image with editing instructions that assesses models' abilities in multi-turn generation, visual memory, and world-knowledge reasoning across diverse domains. Experiments demonstrate that training on WEAVE-100k enables vision comprehension, image editing, and comprehension-generation collaboration capabilities. Furthermore, it facilitates UMMs to develop emergent visual-memory capabilities, while extensive evaluations on WEAVEBench expose the persistent limitations and challenges of current approaches in multi-turn, context-aware image generation and editing. We believe WEAVE provides a view and foundation for studying in-context interleaved comprehension and generation for multi-modal community.
BanditSpec: Adaptive Speculative Decoding via Bandit Algorithms
May 21, 2025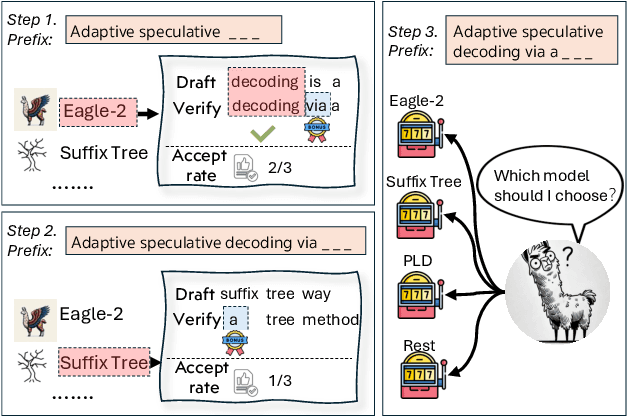
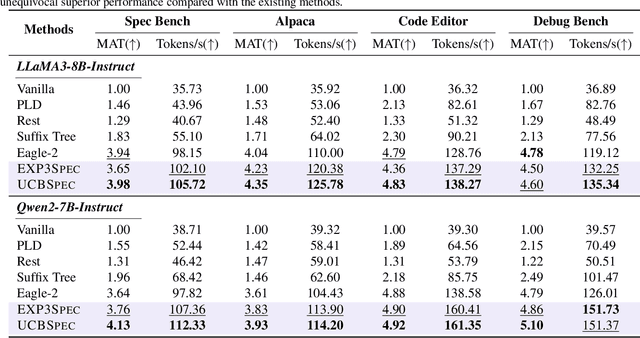
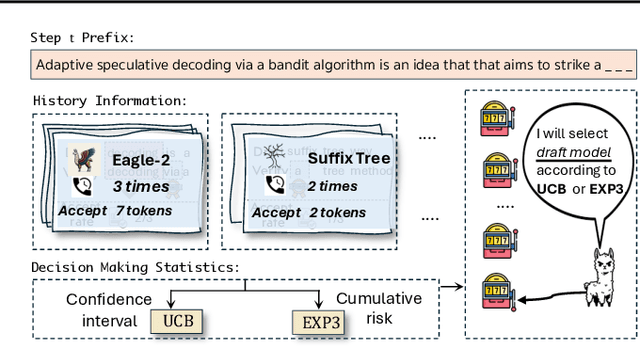
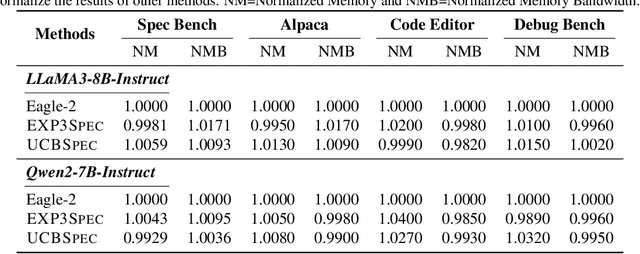
Speculative decoding has emerged as a popular method to accelerate the inference of Large Language Models (LLMs) while retaining their superior text generation performance. Previous methods either adopt a fixed speculative decoding configuration regardless of the prefix tokens, or train draft models in an offline or online manner to align them with the context. This paper proposes a training-free online learning framework to adaptively choose the configuration of the hyperparameters for speculative decoding as text is being generated. We first formulate this hyperparameter selection problem as a Multi-Armed Bandit problem and provide a general speculative decoding framework BanditSpec. Furthermore, two bandit-based hyperparameter selection algorithms, UCBSpec and EXP3Spec, are designed and analyzed in terms of a novel quantity, the stopping time regret. We upper bound this regret under both stochastic and adversarial reward settings. By deriving an information-theoretic impossibility result, it is shown that the regret performance of UCBSpec is optimal up to universal constants. Finally, extensive empirical experiments with LLaMA3 and Qwen2 demonstrate that our algorithms are effective compared to existing methods, and the throughput is close to the oracle best hyperparameter in simulated real-life LLM serving scenarios with diverse input prompts.
Selftok: Discrete Visual Tokens of Autoregression, by Diffusion, and for Reasoning
May 18, 2025We completely discard the conventional spatial prior in image representation and introduce a novel discrete visual tokenizer: Self-consistency Tokenizer (Selftok). At its design core, we compose an autoregressive (AR) prior -- mirroring the causal structure of language -- into visual tokens by using the reverse diffusion process of image generation. The AR property makes Selftok fundamentally distinct from traditional spatial tokens in the following two key ways: - Selftok offers an elegant and minimalist approach to unify diffusion and AR for vision-language models (VLMs): By representing images with Selftok tokens, we can train a VLM using a purely discrete autoregressive architecture -- like that in LLMs -- without requiring additional modules or training objectives. - We theoretically show that the AR prior satisfies the Bellman equation, whereas the spatial prior does not. Therefore, Selftok supports reinforcement learning (RL) for visual generation with effectiveness comparable to that achieved in LLMs. Besides the AR property, Selftok is also a SoTA tokenizer that achieves a favorable trade-off between high-quality reconstruction and compression rate. We use Selftok to build a pure AR VLM for both visual comprehension and generation tasks. Impressively, without using any text-image training pairs, a simple policy gradient RL working in the visual tokens can significantly boost the visual generation benchmark, surpassing all the existing models by a large margin. Therefore, we believe that Selftok effectively addresses the long-standing challenge that visual tokens cannot support effective RL. When combined with the well-established strengths of RL in LLMs, this brings us one step closer to realizing a truly multimodal LLM. Project Page: https://selftok-team.github.io/report/.
Discrete Visual Tokens of Autoregression, by Diffusion, and for Reasoning
May 12, 2025We completely discard the conventional spatial prior in image representation and introduce a novel discrete visual tokenizer: Self-consistency Tokenizer (Selftok). At its design core, we compose an autoregressive (AR) prior -- mirroring the causal structure of language -- into visual tokens by using the reverse diffusion process of image generation. The AR property makes Selftok fundamentally distinct from traditional spatial tokens in the following two key ways: - Selftok offers an elegant and minimalist approach to unify diffusion and AR for vision-language models (VLMs): By representing images with Selftok tokens, we can train a VLM using a purely discrete autoregressive architecture -- like that in LLMs -- without requiring additional modules or training objectives. - We theoretically show that the AR prior satisfies the Bellman equation, whereas the spatial prior does not. Therefore, Selftok supports reinforcement learning (RL) for visual generation with effectiveness comparable to that achieved in LLMs. Besides the AR property, Selftok is also a SoTA tokenizer that achieves a favorable trade-off between high-quality reconstruction and compression rate. We use Selftok to build a pure AR VLM for both visual comprehension and generation tasks. Impressively, without using any text-image training pairs, a simple policy gradient RL working in the visual tokens can significantly boost the visual generation benchmark, surpassing all the existing models by a large margin. Therefore, we believe that Selftok effectively addresses the long-standing challenge that visual tokens cannot support effective RL. When combined with the well-established strengths of RL in LLMs, this brings us one step closer to realizing a truly multimodal LLM. Project Page: https://selftok-team.github.io/report/.
Skywork R1V: Pioneering Multimodal Reasoning with Chain-of-Thought
Apr 08, 2025We introduce Skywork R1V, a multimodal reasoning model extending the an R1-series Large language models (LLM) to visual modalities via an efficient multimodal transfer method. Leveraging a lightweight visual projector, Skywork R1V facilitates seamless multimodal adaptation without necessitating retraining of either the foundational language model or the vision encoder. To strengthen visual-text alignment, we propose a hybrid optimization strategy that combines Iterative Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO), significantly enhancing cross-modal integration efficiency. Additionally, we introduce an adaptive-length Chain-of-Thought distillation approach for reasoning data generation. This approach dynamically optimizes reasoning chain lengths, thereby enhancing inference efficiency and preventing excessive reasoning overthinking. Empirical evaluations demonstrate that Skywork R1V, with only 38B parameters, delivers competitive performance, achieving a score of 69.0 on the MMMU benchmark and 67.5 on MathVista. Meanwhile, it maintains robust textual reasoning performance, evidenced by impressive scores of 72.0 on AIME and 94.0 on MATH500. The Skywork R1V model weights have been publicly released to promote openness and reproducibility.
Towards Understanding Why Data Augmentation Improves Generalization
Feb 13, 2025
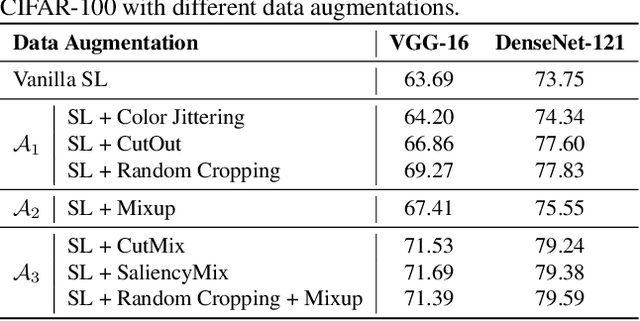


Data augmentation is a cornerstone technique in deep learning, widely used to improve model generalization. Traditional methods like random cropping and color jittering, as well as advanced techniques such as CutOut, Mixup, and CutMix, have achieved notable success across various domains. However, the mechanisms by which data augmentation improves generalization remain poorly understood, and existing theoretical analyses typically focus on individual techniques without a unified explanation. In this work, we present a unified theoretical framework that elucidates how data augmentation enhances generalization through two key effects: partial semantic feature removal and feature mixing. Partial semantic feature removal reduces the model's reliance on individual feature, promoting diverse feature learning and better generalization. Feature mixing, by scaling down original semantic features and introducing noise, increases training complexity, driving the model to develop more robust features. Advanced methods like CutMix integrate both effects, achieving complementary benefits. Our theoretical insights are further supported by experimental results, validating the effectiveness of this unified perspective.
Enhancing Multi-Text Long Video Generation Consistency without Tuning: Time-Frequency Analysis, Prompt Alignment, and Theory
Dec 23, 2024
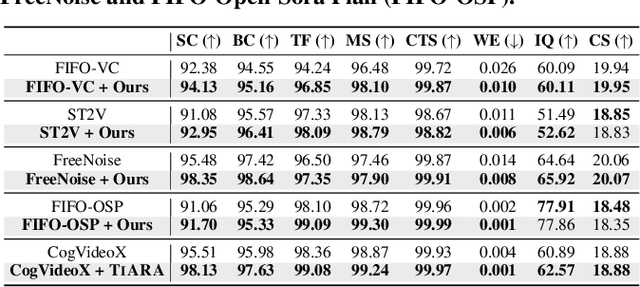
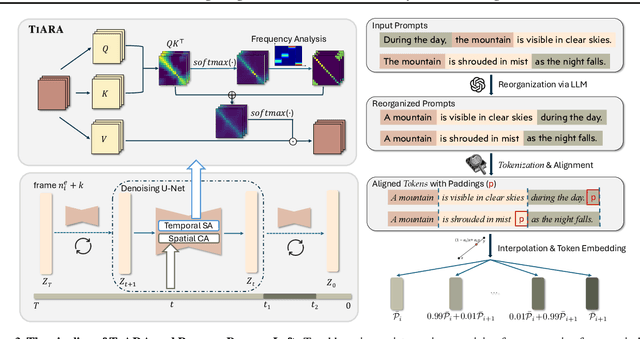
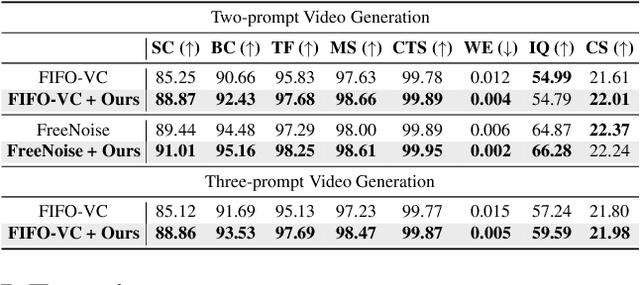
Despite the considerable progress achieved in the long video generation problem, there is still significant room to improve the consistency of the videos, particularly in terms of smoothness and transitions between scenes. We address these issues to enhance the consistency and coherence of videos generated with either single or multiple prompts. We propose the Time-frequency based temporal Attention Reweighting Algorithm (TiARA), which meticulously edits the attention score matrix based on the Discrete Short-Time Fourier Transform. Our method is supported by a theoretical guarantee, the first-of-its-kind for frequency-based methods in diffusion models. For videos generated by multiple prompts, we further investigate key factors affecting prompt interpolation quality and propose PromptBlend, an advanced prompt interpolation pipeline. The efficacy of our proposed method is validated via extensive experimental results, exhibiting consistent and impressive improvements over baseline methods. The code will be released upon acceptance.
MEMO: Memory-Guided Diffusion for Expressive Talking Video Generation
Dec 05, 2024



Recent advances in video diffusion models have unlocked new potential for realistic audio-driven talking video generation. However, achieving seamless audio-lip synchronization, maintaining long-term identity consistency, and producing natural, audio-aligned expressions in generated talking videos remain significant challenges. To address these challenges, we propose Memory-guided EMOtion-aware diffusion (MEMO), an end-to-end audio-driven portrait animation approach to generate identity-consistent and expressive talking videos. Our approach is built around two key modules: (1) a memory-guided temporal module, which enhances long-term identity consistency and motion smoothness by developing memory states to store information from a longer past context to guide temporal modeling via linear attention; and (2) an emotion-aware audio module, which replaces traditional cross attention with multi-modal attention to enhance audio-video interaction, while detecting emotions from audio to refine facial expressions via emotion adaptive layer norm. Extensive quantitative and qualitative results demonstrate that MEMO generates more realistic talking videos across diverse image and audio types, outperforming state-of-the-art methods in overall quality, audio-lip synchronization, identity consistency, and expression-emotion alignment.
Towards Understanding Why FixMatch Generalizes Better Than Supervised Learning
Oct 15, 2024



Semi-supervised learning (SSL), exemplified by FixMatch (Sohn et al., 2020), has shown significant generalization advantages over supervised learning (SL), particularly in the context of deep neural networks (DNNs). However, it is still unclear, from a theoretical standpoint, why FixMatch-like SSL algorithms generalize better than SL on DNNs. In this work, we present the first theoretical justification for the enhanced test accuracy observed in FixMatch-like SSL applied to DNNs by taking convolutional neural networks (CNNs) on classification tasks as an example. Our theoretical analysis reveals that the semantic feature learning processes in FixMatch and SL are rather different. In particular, FixMatch learns all the discriminative features of each semantic class, while SL only randomly captures a subset of features due to the well-known lottery ticket hypothesis. Furthermore, we show that our analysis framework can be applied to other FixMatch-like SSL methods, e.g., FlexMatch, FreeMatch, Dash, and SoftMatch. Inspired by our theoretical analysis, we develop an improved variant of FixMatch, termed Semantic-Aware FixMatch (SA-FixMatch). Experimental results corroborate our theoretical findings and the enhanced generalization capability of SA-FixMatch.
PeRFlow: Piecewise Rectified Flow as Universal Plug-and-Play Accelerator
May 13, 2024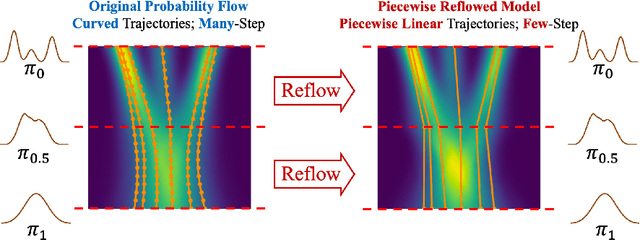



We present Piecewise Rectified Flow (PeRFlow), a flow-based method for accelerating diffusion models. PeRFlow divides the sampling process of generative flows into several time windows and straightens the trajectories in each interval via the reflow operation, thereby approaching piecewise linear flows. PeRFlow achieves superior performance in a few-step generation. Moreover, through dedicated parameterizations, the obtained PeRFlow models show advantageous transfer ability, serving as universal plug-and-play accelerators that are compatible with various workflows based on the pre-trained diffusion models. The implementations of training and inference are fully open-sourced. https://github.com/magic-research/piecewise-rectified-flow