 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoirai 2.0: When Less Is More for Time Series Forecasting
Nov 12, 2025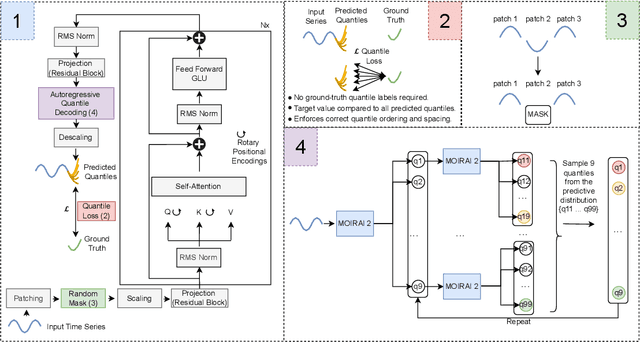
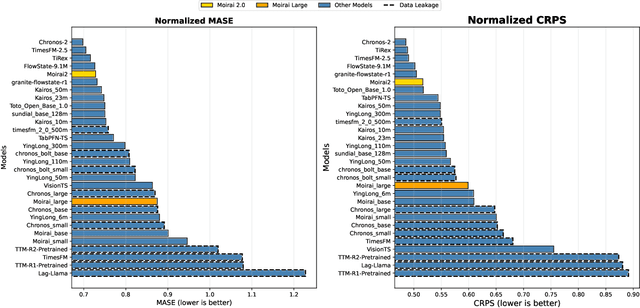

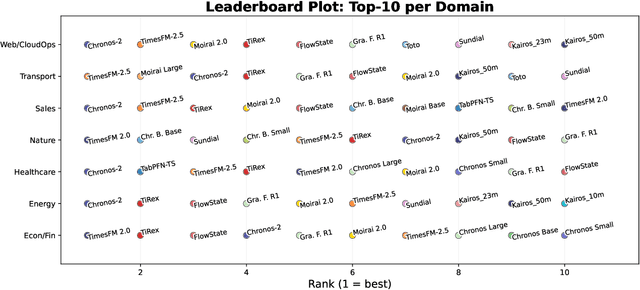
We introduce Moirai 2.0, a decoder-only time-series foundation model trained on a new corpus of 36M series. The model adopts quantile forecasting and multi-token prediction, improving both probabilistic accuracy and inference efficiency. On the Gift-Eval benchmark, it ranks among the top pretrained models while achieving a strong trade-off between accuracy, speed, and model size. Compared to Moirai 1.0, Moirai 2.0 replaces masked-encoder training, multi-patch inputs, and mixture-distribution outputs with a simpler decoder-only architecture, single patch, and quantile loss. Ablation studies isolate these changes -- showing that the decoder-only backbone along with recursive multi-quantile decoding contribute most to the gains. Additional experiments show that Moirai 2.0 outperforms larger models from the same family and exhibits robust domain-level results. In terms of efficiency and model size, Moirai 2.0 is twice as fast and thirty times smaller than its prior best version, Moirai 1.0-Large, while also performing better. Model performance plateaus with increasing parameter count and declines at longer horizons, motivating future work on data scaling and long-horizon modeling. We release code and evaluation details to support further research.
OFTSR: One-Step Flow for Image Super-Resolution with Tunable Fidelity-Realism Trade-offs
Dec 12, 2024



Recent advances in diffusion and flow-based generative models have demonstrated remarkable success in image restoration tasks, achieving superior perceptual quality compared to traditional deep learning approaches. However, these methods either require numerous sampling steps to generate high-quality images, resulting in significant computational overhead, or rely on model distillation, which usually imposes a fixed fidelity-realism trade-off and thus lacks flexibility. In this paper, we introduce OFTSR, a novel flow-based framework for one-step image super-resolution that can produce outputs with tunable levels of fidelity and realism. Our approach first trains a conditional flow-based super-resolution model to serve as a teacher model. We then distill this teacher model by applying a specialized constraint. Specifically, we force the predictions from our one-step student model for same input to lie on the same sampling ODE trajectory of the teacher model. This alignment ensures that the student model's single-step predictions from initial states match the teacher's predictions from a closer intermediate state. Through extensive experiments on challenging datasets including FFHQ (256$\times$256), DIV2K, and ImageNet (256$\times$256), we demonstrate that OFTSR achieves state-of-the-art performance for one-step image super-resolution, while having the ability to flexibly tune the fidelity-realism trade-off. Code and pre-trained models are available at https://github.com/yuanzhi-zhu/OFTSR and https://huggingface.co/Yuanzhi/OFTSR, respectively.
Accelerating Video Diffusion Models via Distribution Matching
Dec 08, 2024



Generative models, particularly diffusion models, have made significant success in data synthesis across various modalities, including images, videos, and 3D assets. However, current diffusion models are computationally intensive, often requiring numerous sampling steps that limit their practical application, especially in video generation. This work introduces a novel framework for diffusion distillation and distribution matching that dramatically reduces the number of inference steps while maintaining-and potentially improving-generation quality. Our approach focuses on distilling pre-trained diffusion models into a more efficient few-step generator, specifically targeting video generation. By leveraging a combination of video GAN loss and a novel 2D score distribution matching loss, we demonstrate the potential to generate high-quality video frames with substantially fewer sampling steps. To be specific, the proposed method incorporates a denoising GAN discriminator to distil from the real data and a pre-trained image diffusion model to enhance the frame quality and the prompt-following capabilities. Experimental results using AnimateDiff as the teacher model showcase the method's effectiveness, achieving superior performance in just four sampling steps compared to existing techniques.
DiG: Scalable and Efficient Diffusion Models with Gated Linear Attention
May 28, 2024



Diffusion models with large-scale pre-training have achieved significant success in the field of visual content generation, particularly exemplified by Diffusion Transformers (DiT). However, DiT models have faced challenges with scalability and quadratic complexity efficiency. In this paper, we aim to leverage the long sequence modeling capability of Gated Linear Attention (GLA) Transformers, expanding its applicability to diffusion models. We introduce Diffusion Gated Linear Attention Transformers (DiG), a simple, adoptable solution with minimal parameter overhead, following the DiT design, but offering superior efficiency and effectiveness. In addition to better performance than DiT, DiG-S/2 exhibits $2.5\times$ higher training speed than DiT-S/2 and saves $75.7\%$ GPU memory at a resolution of $1792 \times 1792$. Moreover, we analyze the scalability of DiG across a variety of computational complexity. DiG models, with increased depth/width or augmentation of input tokens, consistently exhibit decreasing FID. We further compare DiG with other subquadratic-time diffusion models. With the same model size, DiG-XL/2 is $4.2\times$ faster than the recent Mamba-based diffusion model at a $1024$ resolution, and is $1.8\times$ faster than DiT with CUDA-optimized FlashAttention-2 under the $2048$ resolution. All these results demonstrate its superior efficiency among the latest diffusion models. Code is released at https://github.com/hustvl/DiG.
ClassDiffusion: More Aligned Personalization Tuning with Explicit Class Guidance
May 27, 2024Recent text-to-image customization works have been proven successful in generating images of given concepts by fine-tuning the diffusion models on a few examples. However, these methods tend to overfit the concepts, resulting in failure to create the concept under multiple conditions (e.g. headphone is missing when generating a <sks> dog wearing a headphone'). Interestingly, we notice that the base model before fine-tuning exhibits the capability to compose the base concept with other elements (e.g. a dog wearing a headphone) implying that the compositional ability only disappears after personalization tuning. Inspired by this observation, we present ClassDiffusion, a simple technique that leverages a semantic preservation loss to explicitly regulate the concept space when learning the new concept. Despite its simplicity, this helps avoid semantic drift when fine-tuning on the target concepts. Extensive qualitative and quantitative experiments demonstrate that the use of semantic preservation loss effectively improves the compositional abilities of the fine-tune models. In response to the ineffective evaluation of CLIP-T metrics, we introduce BLIP2-T metric, a more equitable and effective evaluation metric for this particular domain. We also provide in-depth empirical study and theoretical analysis to better understand the role of the proposed loss. Lastly, we also extend our ClassDiffusion to personalized video generation, demonstrating its flexibility.
InstaDrag: Lightning Fast and Accurate Drag-based Image Editing Emerging from Videos
May 22, 2024


Accuracy and speed are critical in image editing tasks. Pan et al. introduced a drag-based image editing framework that achieves pixel-level control using Generative Adversarial Networks (GANs). A flurry of subsequent studies enhanced this framework's generality by leveraging large-scale diffusion models. However, these methods often suffer from inordinately long processing times (exceeding 1 minute per edit) and low success rates. Addressing these issues head on, we present InstaDrag, a rapid approach enabling high quality drag-based image editing in ~1 second. Unlike most previous methods, we redefine drag-based editing as a conditional generation task, eliminating the need for time-consuming latent optimization or gradient-based guidance during inference. In addition, the design of our pipeline allows us to train our model on large-scale paired video frames, which contain rich motion information such as object translations, changing poses and orientations, zooming in and out, etc. By learning from videos, our approach can significantly outperform previous methods in terms of accuracy and consistency. Despite being trained solely on videos, our model generalizes well to perform local shape deformations not presented in the training data (e.g., lengthening of hair, twisting rainbows, etc.). Extensive qualitative and quantitative evaluations on benchmark datasets corroborate the superiority of our approach. The code and model will be released at https://github.com/magic-research/InstaDrag.
PeRFlow: Piecewise Rectified Flow as Universal Plug-and-Play Accelerator
May 13, 2024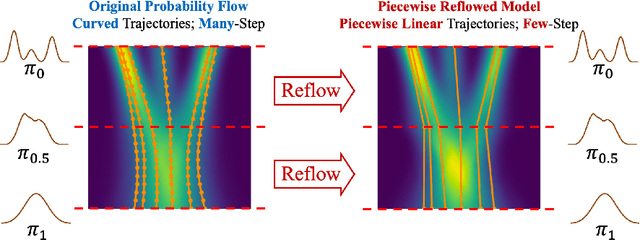



We present Piecewise Rectified Flow (PeRFlow), a flow-based method for accelerating diffusion models. PeRFlow divides the sampling process of generative flows into several time windows and straightens the trajectories in each interval via the reflow operation, thereby approaching piecewise linear flows. PeRFlow achieves superior performance in a few-step generation. Moreover, through dedicated parameterizations, the obtained PeRFlow models show advantageous transfer ability, serving as universal plug-and-play accelerators that are compatible with various workflows based on the pre-trained diffusion models. The implementations of training and inference are fully open-sourced. https://github.com/magic-research/piecewise-rectified-flow
MagicVideo-V2: Multi-Stage High-Aesthetic Video Generation
Jan 09, 2024The growing demand for high-fidelity video generation from textual descriptions has catalyzed significant research in this field. In this work, we introduce MagicVideo-V2 that integrates the text-to-image model, video motion generator, reference image embedding module and frame interpolation module into an end-to-end video generation pipeline. Benefiting from these architecture designs, MagicVideo-V2 can generate an aesthetically pleasing, high-resolution video with remarkable fidelity and smoothness. It demonstrates superior performance over leading Text-to-Video systems such as Runway, Pika 1.0, Morph, Moon Valley and Stable Video Diffusion model via user evaluation at large scale.
Towards Accurate Guided Diffusion Sampling through Symplectic Adjoint Method
Dec 19, 2023
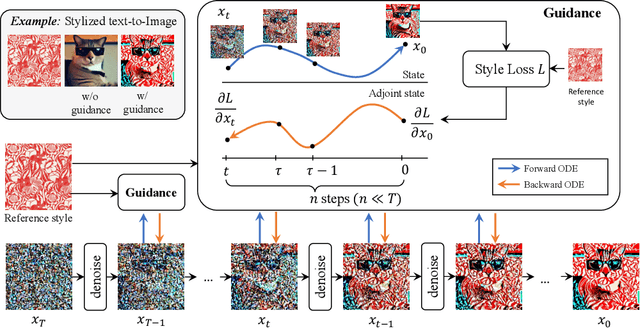

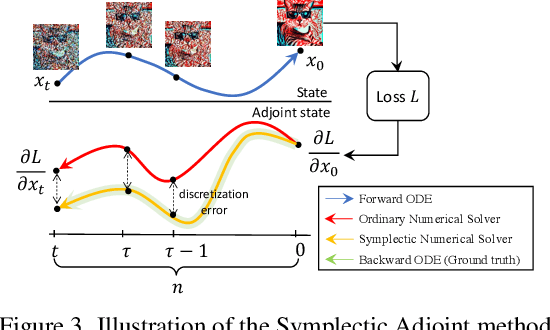
Training-free guided sampling in diffusion models leverages off-the-shelf pre-trained networks, such as an aesthetic evaluation model, to guide the generation process. Current training-free guided sampling algorithms obtain the guidance energy function based on a one-step estimate of the clean image. However, since the off-the-shelf pre-trained networks are trained on clean images, the one-step estimation procedure of the clean image may be inaccurate, especially in the early stages of the generation process in diffusion models. This causes the guidance in the early time steps to be inaccurate. To overcome this problem, we propose Symplectic Adjoint Guidance (SAG), which calculates the gradient guidance in two inner stages. Firstly, SAG estimates the clean image via $n$ function calls, where $n$ serves as a flexible hyperparameter that can be tailored to meet specific image quality requirements. Secondly, SAG uses the symplectic adjoint method to obtain the gradients accurately and efficiently in terms of the memory requirements. Extensive experiments demonstrate that SAG generates images with higher qualities compared to the baselines in both guided image and video generation tasks.
MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model
Nov 27, 2023



This paper studies the human image animation task, which aims to generate a video of a certain reference identity following a particular motion sequence. Existing animation works typically employ the frame-warping technique to animate the reference image towards the target motion. Despite achieving reasonable results, these approaches face challenges in maintaining temporal consistency throughout the animation due to the lack of temporal modeling and poor preservation of reference identity. In this work, we introduce MagicAnimate, a diffusion-based framework that aims at enhancing temporal consistency, preserving reference image faithfully, and improving animation fidelity. To achieve this, we first develop a video diffusion model to encode temporal information. Second, to maintain the appearance coherence across frames, we introduce a novel appearance encoder to retain the intricate details of the reference image. Leveraging these two innovations, we further employ a simple video fusion technique to encourage smooth transitions for long video animation. Empirical results demonstrate the superiority of our method over baseline approaches on two benchmarks. Notably, our approach outperforms the strongest baseline by over 38% in terms of video fidelity on the challenging TikTok dancing dataset. Code and model will be made available.