 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHY-World 2.0: A Multi-Modal World Model for Reconstructing, Generating, and Simulating 3D Worlds
Apr 15, 2026We introduce HY-World 2.0, a multi-modal world model framework that advances our prior project HY-World 1.0. HY-World 2.0 accommodates diverse input modalities, including text prompts, single-view images, multi-view images, and videos, and produces 3D world representations. With text or single-view image inputs, the model performs world generation, synthesizing high-fidelity, navigable 3D Gaussian Splatting (3DGS) scenes. This is achieved through a four-stage method: a) Panorama Generation with HY-Pano 2.0, b) Trajectory Planning with WorldNav, c) World Expansion with WorldStereo 2.0, and d) World Composition with WorldMirror 2.0. Specifically, we introduce key innovations to enhance panorama fidelity, enable 3D scene understanding and planning, and upgrade WorldStereo, our keyframe-based view generation model with consistent memory. We also upgrade WorldMirror, a feed-forward model for universal 3D prediction, by refining model architecture and learning strategy, enabling world reconstruction from multi-view images or videos. Also, we introduce WorldLens, a high-performance 3DGS rendering platform featuring a flexible engine-agnostic architecture, automatic IBL lighting, efficient collision detection, and training-rendering co-design, enabling interactive exploration of 3D worlds with character support. Extensive experiments demonstrate that HY-World 2.0 achieves state-of-the-art performance on several benchmarks among open-source approaches, delivering results comparable to the closed-source model Marble. We release all model weights, code, and technical details to facilitate reproducibility and support further research on 3D world models.
WebForge: Breaking the Realism-Reproducibility-Scalability Trilemma in Browser Agent Benchmark
Apr 13, 2026Existing browser agent benchmarks face a fundamental trilemma: real-website benchmarks lack reproducibility due to content drift, controlled environments sacrifice realism by omitting real-web noise, and both require costly manual curation that limits scalability. We present WebForge, the first fully automated framework that resolves this trilemma through a four-agent pipeline -- Plan, Generate, Refine, and Validate -- that produces interactive, self-contained web environments end-to-end without human annotation. A seven-dimensional difficulty control framework structures task design along navigation depth, visual complexity, reasoning difficulty, and more, enabling systematic capability profiling beyond single aggregate scores. Using WebForge, we construct WebForge-Bench, a benchmark of 934 tasks spanning 7 domains and 3 difficulty levels. Multi-model experiments show that difficulty stratification effectively differentiates model capabilities, while cross-domain analysis exposes capability biases invisible to aggregate metrics. Together, these results confirm that multi-dimensional evaluation reveals distinct capability profiles that a single aggregate score cannot capture. Code and benchmark are publicly available at https://github.com/yuandaxia2001/WebForge.
Geometry-Guided Reinforcement Learning for Multi-view Consistent 3D Scene Editing
Mar 03, 2026Leveraging the priors of 2D diffusion models for 3D editing has emerged as a promising paradigm. However, maintaining multi-view consistency in edited results remains challenging, and the extreme scarcity of 3D-consistent editing paired data renders supervised fine-tuning (SFT), the most effective training strategy for editing tasks, infeasible. In this paper, we observe that, while generating multi-view consistent 3D content is highly challenging, verifying 3D consistency is tractable, naturally positioning reinforcement learning (RL) as a feasible solution. Motivated by this, we propose \textbf{RL3DEdit}, a single-pass framework driven by RL optimization with novel rewards derived from the 3D foundation model, VGGT. Specifically, we leverage VGGT's robust priors learned from massive real-world data, feed the edited images, and utilize the output confidence maps and pose estimation errors as reward signals, effectively anchoring the 2D editing priors onto a 3D-consistent manifold via RL. Extensive experiments demonstrate that RL3DEdit achieves stable multi-view consistency and outperforms state-of-the-art methods in editing quality with high efficiency. To promote the development of 3D editing, we will release the code and model.
Yunque DeepResearch Technical Report
Jan 27, 2026Deep research has emerged as a transformative capability for autonomous agents, empowering Large Language Models to navigate complex, open-ended tasks. However, realizing its full potential is hindered by critical limitations, including escalating contextual noise in long-horizon tasks, fragility leading to cascading errors, and a lack of modular extensibility. To address these challenges, we introduce Yunque DeepResearch, a hierarchical, modular, and robust framework. The architecture is characterized by three key components: (1) a centralized Multi-Agent Orchestration System that routes subtasks to an Atomic Capability Pool of tools and specialized sub-agents; (2) a Dynamic Context Management mechanism that structures completed sub-goals into semantic summaries to mitigate information overload; and (3) a proactive Supervisor Module that ensures resilience through active anomaly detection and context pruning. Yunque DeepResearch achieves state-of-the-art performance across a range of agentic deep research benchmarks, including GAIA, BrowseComp, BrowseComp-ZH, and Humanity's Last Exam. We open-source the framework, reproducible implementations, and application cases to empower the community.
StereoWorld: Geometry-Aware Monocular-to-Stereo Video Generation
Dec 11, 2025The growing adoption of XR devices has fueled strong demand for high-quality stereo video, yet its production remains costly and artifact-prone. To address this challenge, we present StereoWorld, an end-to-end framework that repurposes a pretrained video generator for high-fidelity monocular-to-stereo video generation. Our framework jointly conditions the model on the monocular video input while explicitly supervising the generation with a geometry-aware regularization to ensure 3D structural fidelity. A spatio-temporal tiling scheme is further integrated to enable efficient, high-resolution synthesis. To enable large-scale training and evaluation, we curate a high-definition stereo video dataset containing over 11M frames aligned to natural human interpupillary distance (IPD). Extensive experiments demonstrate that StereoWorld substantially outperforms prior methods, generating stereo videos with superior visual fidelity and geometric consistency. The project webpage is available at https://ke-xing.github.io/StereoWorld/.
TiP4GEN: Text to Immersive Panorama 4D Scene Generation
Aug 17, 2025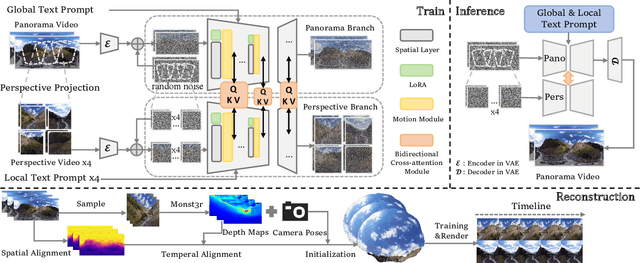
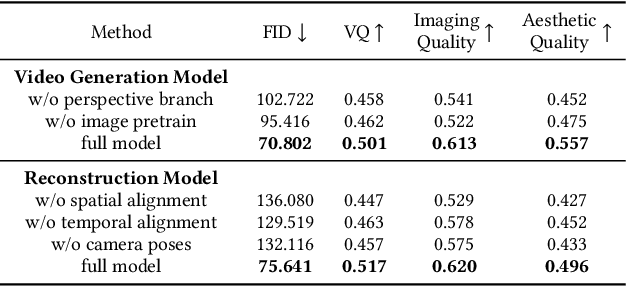
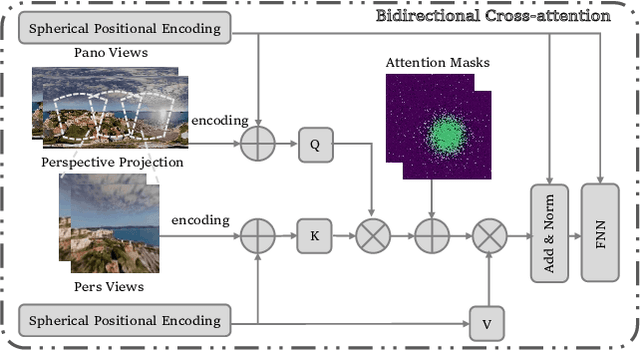
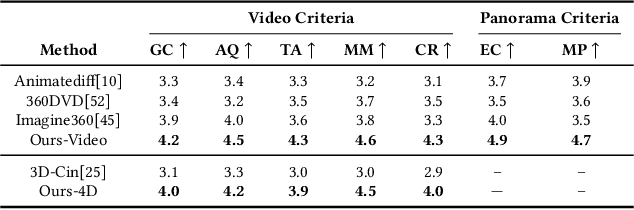
With the rapid advancement and widespread adoption of VR/AR technologies, there is a growing demand for the creation of high-quality, immersive dynamic scenes. However, existing generation works predominantly concentrate on the creation of static scenes or narrow perspective-view dynamic scenes, falling short of delivering a truly 360-degree immersive experience from any viewpoint. In this paper, we introduce \textbf{TiP4GEN}, an advanced text-to-dynamic panorama scene generation framework that enables fine-grained content control and synthesizes motion-rich, geometry-consistent panoramic 4D scenes. TiP4GEN integrates panorama video generation and dynamic scene reconstruction to create 360-degree immersive virtual environments. For video generation, we introduce a \textbf{Dual-branch Generation Model} consisting of a panorama branch and a perspective branch, responsible for global and local view generation, respectively. A bidirectional cross-attention mechanism facilitates comprehensive information exchange between the branches. For scene reconstruction, we propose a \textbf{Geometry-aligned Reconstruction Model} based on 3D Gaussian Splatting. By aligning spatial-temporal point clouds using metric depth maps and initializing scene cameras with estimated poses, our method ensures geometric consistency and temporal coherence for the reconstructed scenes. Extensive experiments demonstrate the effectiveness of our proposed designs and the superiority of TiP4GEN in generating visually compelling and motion-coherent dynamic panoramic scenes. Our project page is at https://ke-xing.github.io/TiP4GEN/.
Matrix-3D: Omnidirectional Explorable 3D World Generation
Aug 11, 2025Explorable 3D world generation from a single image or text prompt forms a cornerstone of spatial intelligence. Recent works utilize video model to achieve wide-scope and generalizable 3D world generation. However, existing approaches often suffer from a limited scope in the generated scenes. In this work, we propose Matrix-3D, a framework that utilize panoramic representation for wide-coverage omnidirectional explorable 3D world generation that combines conditional video generation and panoramic 3D reconstruction. We first train a trajectory-guided panoramic video diffusion model that employs scene mesh renders as condition, to enable high-quality and geometrically consistent scene video generation. To lift the panorama scene video to 3D world, we propose two separate methods: (1) a feed-forward large panorama reconstruction model for rapid 3D scene reconstruction and (2) an optimization-based pipeline for accurate and detailed 3D scene reconstruction. To facilitate effective training, we also introduce the Matrix-Pano dataset, the first large-scale synthetic collection comprising 116K high-quality static panoramic video sequences with depth and trajectory annotations. Extensive experiments demonstrate that our proposed framework achieves state-of-the-art performance in panoramic video generation and 3D world generation. See more in https://matrix-3d.github.io.
TBAC-UniImage: Unified Understanding and Generation by Ladder-Side Diffusion Tuning
Aug 11, 2025This paper introduces TBAC-UniImage, a novel unified model for multimodal understanding and generation. We achieve this by deeply integrating a pre-trained Diffusion Model, acting as a generative ladder, with a Multimodal Large Language Model (MLLM). Previous diffusion-based unified models face two primary limitations. One approach uses only the MLLM's final hidden state as the generative condition. This creates a shallow connection, as the generator is isolated from the rich, hierarchical representations within the MLLM's intermediate layers. The other approach, pretraining a unified generative architecture from scratch, is computationally expensive and prohibitive for many researchers. To overcome these issues, our work explores a new paradigm. Instead of relying on a single output, we use representations from multiple, diverse layers of the MLLM as generative conditions for the diffusion model. This method treats the pre-trained generator as a ladder, receiving guidance from various depths of the MLLM's understanding process. Consequently, TBAC-UniImage achieves a much deeper and more fine-grained unification of understanding and generation.
Martian World Models: Controllable Video Synthesis with Physically Accurate 3D Reconstructions
Jul 10, 2025



Synthesizing realistic Martian landscape videos is crucial for mission rehearsal and robotic simulation. However, this task poses unique challenges due to the scarcity of high-quality Martian data and the significant domain gap between Martian and terrestrial imagery. To address these challenges, we propose a holistic solution composed of two key components: 1) A data curation pipeline Multimodal Mars Synthesis (M3arsSynth), which reconstructs 3D Martian environments from real stereo navigation images, sourced from NASA's Planetary Data System (PDS), and renders high-fidelity multiview 3D video sequences. 2) A Martian terrain video generator, MarsGen, which synthesizes novel videos visually realistic and geometrically consistent with the 3D structure encoded in the data. Our M3arsSynth engine spans a wide range of Martian terrains and acquisition dates, enabling the generation of physically accurate 3D surface models at metric-scale resolution. MarsGen, fine-tuned on M3arsSynth data, synthesizes videos conditioned on an initial image frame and, optionally, camera trajectories or textual prompts, allowing for video generation in novel environments. Experimental results show that our approach outperforms video synthesis models trained on terrestrial datasets, achieving superior visual fidelity and 3D structural consistency.
ChineseHarm-Bench: A Chinese Harmful Content Detection Benchmark
Jun 12, 2025Large language models (LLMs) have been increasingly applied to automated harmful content detection tasks, assisting moderators in identifying policy violations and improving the overall efficiency and accuracy of content review. However, existing resources for harmful content detection are predominantly focused on English, with Chinese datasets remaining scarce and often limited in scope. We present a comprehensive, professionally annotated benchmark for Chinese content harm detection, which covers six representative categories and is constructed entirely from real-world data. Our annotation process further yields a knowledge rule base that provides explicit expert knowledge to assist LLMs in Chinese harmful content detection. In addition, we propose a knowledge-augmented baseline that integrates both human-annotated knowledge rules and implicit knowledge from large language models, enabling smaller models to achieve performance comparable to state-of-the-art LLMs. Code and data are available at https://github.com/zjunlp/ChineseHarm-bench.