 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeRF-NQA: No-Reference Quality Assessment for Scenes Generated by NeRF and Neural View Synthesis Methods
Dec 11, 2024Neural View Synthesis (NVS) has demonstrated efficacy in generating high-fidelity dense viewpoint videos using a image set with sparse views. However, existing quality assessment methods like PSNR, SSIM, and LPIPS are not tailored for the scenes with dense viewpoints synthesized by NVS and NeRF variants, thus, they often fall short in capturing the perceptual quality, including spatial and angular aspects of NVS-synthesized scenes. Furthermore, the lack of dense ground truth views makes the full reference quality assessment on NVS-synthesized scenes challenging. For instance, datasets such as LLFF provide only sparse images, insufficient for complete full-reference assessments. To address the issues above, we propose NeRF-NQA, the first no-reference quality assessment method for densely-observed scenes synthesized from the NVS and NeRF variants. NeRF-NQA employs a joint quality assessment strategy, integrating both viewwise and pointwise approaches, to evaluate the quality of NVS-generated scenes. The viewwise approach assesses the spatial quality of each individual synthesized view and the overall inter-views consistency, while the pointwise approach focuses on the angular qualities of scene surface points and their compound inter-point quality. Extensive evaluations are conducted to compare NeRF-NQA with 23 mainstream visual quality assessment methods (from fields of image, video, and light-field assessment). The results demonstrate NeRF-NQA outperforms the existing assessment methods significantly and it shows substantial superiority on assessing NVS-synthesized scenes without references. An implementation of this paper are available at https://github.com/VincentQQu/NeRF-NQA.
Feed-Forward Bullet-Time Reconstruction of Dynamic Scenes from Monocular Videos
Dec 04, 2024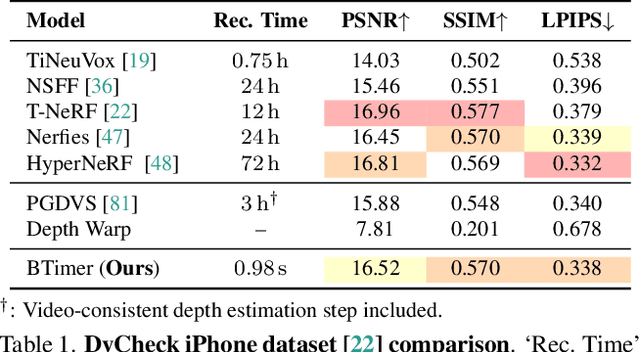
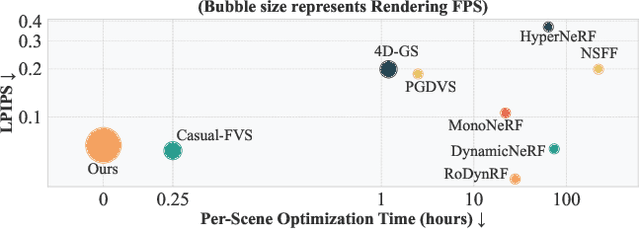
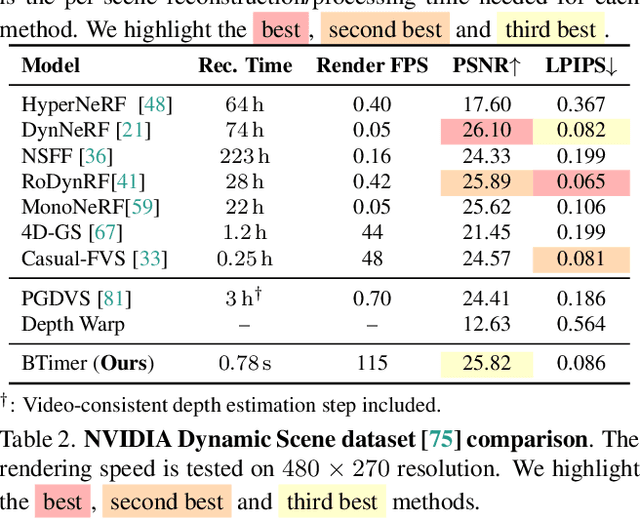
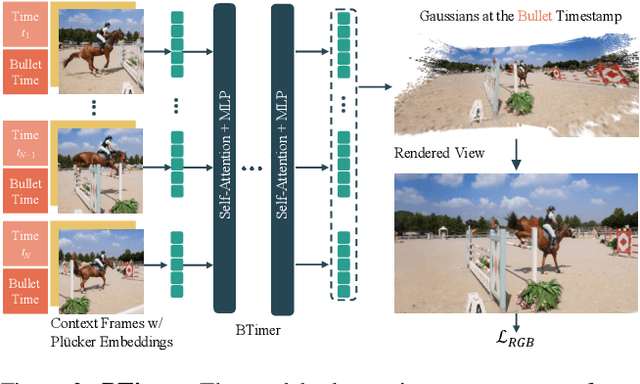
Recent advancements in static feed-forward scene reconstruction have demonstrated significant progress in high-quality novel view synthesis. However, these models often struggle with generalizability across diverse environments and fail to effectively handle dynamic content. We present BTimer (short for BulletTimer), the first motion-aware feed-forward model for real-time reconstruction and novel view synthesis of dynamic scenes. Our approach reconstructs the full scene in a 3D Gaussian Splatting representation at a given target ('bullet') timestamp by aggregating information from all the context frames. Such a formulation allows BTimer to gain scalability and generalization by leveraging both static and dynamic scene datasets. Given a casual monocular dynamic video, BTimer reconstructs a bullet-time scene within 150ms while reaching state-of-the-art performance on both static and dynamic scene datasets, even compared with optimization-based approaches.
SCube: Instant Large-Scale Scene Reconstruction using VoxSplats
Oct 26, 2024



We present SCube, a novel method for reconstructing large-scale 3D scenes (geometry, appearance, and semantics) from a sparse set of posed images. Our method encodes reconstructed scenes using a novel representation VoxSplat, which is a set of 3D Gaussians supported on a high-resolution sparse-voxel scaffold. To reconstruct a VoxSplat from images, we employ a hierarchical voxel latent diffusion model conditioned on the input images followed by a feedforward appearance prediction model. The diffusion model generates high-resolution grids progressively in a coarse-to-fine manner, and the appearance network predicts a set of Gaussians within each voxel. From as few as 3 non-overlapping input images, SCube can generate millions of Gaussians with a 1024^3 voxel grid spanning hundreds of meters in 20 seconds. Past works tackling scene reconstruction from images either rely on per-scene optimization and fail to reconstruct the scene away from input views (thus requiring dense view coverage as input) or leverage geometric priors based on low-resolution models, which produce blurry results. In contrast, SCube leverages high-resolution sparse networks and produces sharp outputs from few views. We show the superiority of SCube compared to prior art using the Waymo self-driving dataset on 3D reconstruction and demonstrate its applications, such as LiDAR simulation and text-to-scene generation.
L4GM: Large 4D Gaussian Reconstruction Model
Jun 14, 2024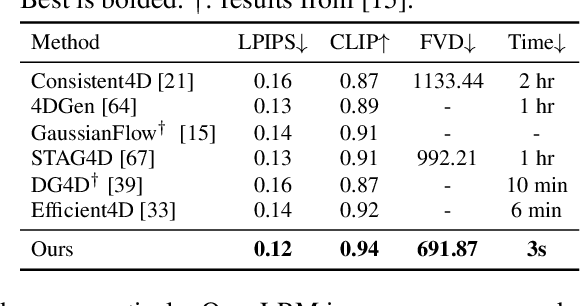
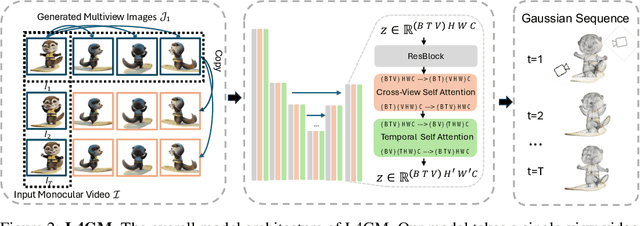
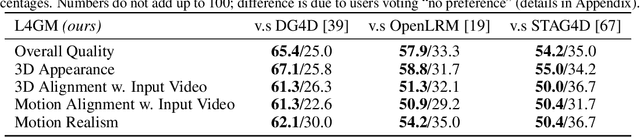
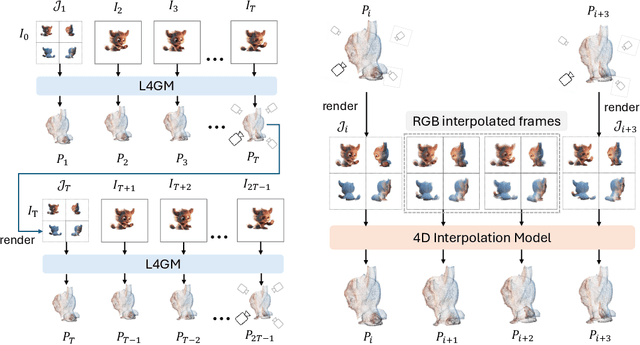
We present L4GM, the first 4D Large Reconstruction Model that produces animated objects from a single-view video input -- in a single feed-forward pass that takes only a second. Key to our success is a novel dataset of multiview videos containing curated, rendered animated objects from Objaverse. This dataset depicts 44K diverse objects with 110K animations rendered in 48 viewpoints, resulting in 12M videos with a total of 300M frames. We keep our L4GM simple for scalability and build directly on top of LGM, a pretrained 3D Large Reconstruction Model that outputs 3D Gaussian ellipsoids from multiview image input. L4GM outputs a per-frame 3D Gaussian Splatting representation from video frames sampled at a low fps and then upsamples the representation to a higher fps to achieve temporal smoothness. We add temporal self-attention layers to the base LGM to help it learn consistency across time, and utilize a per-timestep multiview rendering loss to train the model. The representation is upsampled to a higher framerate by training an interpolation model which produces intermediate 3D Gaussian representations. We showcase that L4GM that is only trained on synthetic data generalizes extremely well on in-the-wild videos, producing high quality animated 3D assets.
Evolutive Rendering Models
May 27, 2024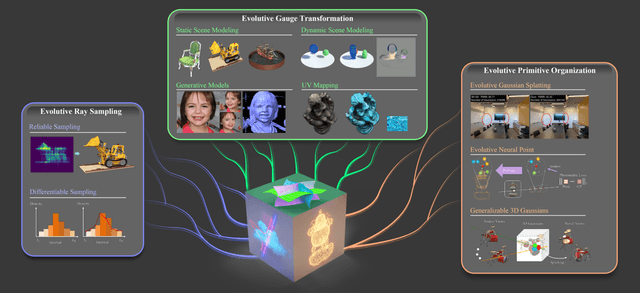
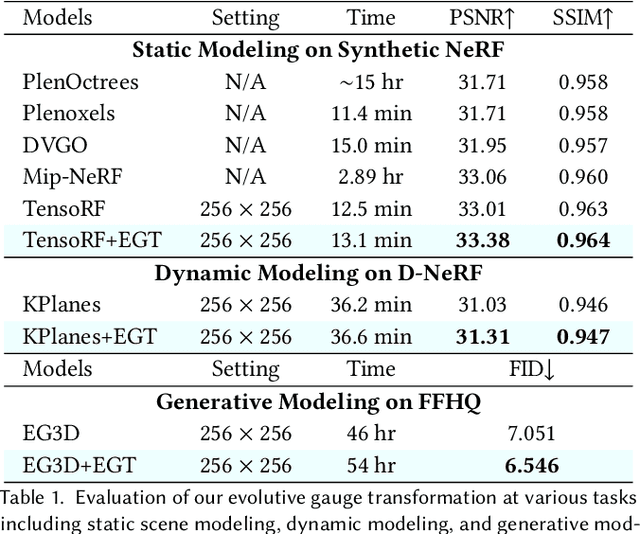
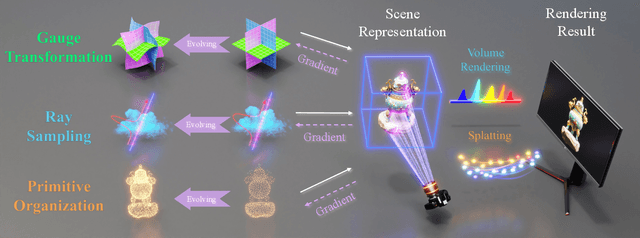
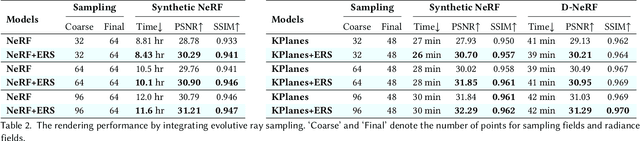
The landscape of computer graphics has undergone significant transformations with the recent advances of differentiable rendering models. These rendering models often rely on heuristic designs that may not fully align with the final rendering objectives. We address this gap by pioneering \textit{evolutive rendering models}, a methodology where rendering models possess the ability to evolve and adapt dynamically throughout the rendering process. In particular, we present a comprehensive learning framework that enables the optimization of three principal rendering elements, including the gauge transformations, the ray sampling mechanisms, and the primitive organization. Central to this framework is the development of differentiable versions of these rendering elements, allowing for effective gradient backpropagation from the final rendering objectives. A detailed analysis of gradient characteristics is performed to facilitate a stable and goal-oriented elements evolution. Our extensive experiments demonstrate the large potential of evolutive rendering models for enhancing the rendering performance across various domains, including static and dynamic scene representations, generative modeling, and texture mapping.
Diffusion4D: Fast Spatial-temporal Consistent 4D Generation via Video Diffusion Models
May 26, 2024



The availability of large-scale multimodal datasets and advancements in diffusion models have significantly accelerated progress in 4D content generation. Most prior approaches rely on multiple image or video diffusion models, utilizing score distillation sampling for optimization or generating pseudo novel views for direct supervision. However, these methods are hindered by slow optimization speeds and multi-view inconsistency issues. Spatial and temporal consistency in 4D geometry has been extensively explored respectively in 3D-aware diffusion models and traditional monocular video diffusion models. Building on this foundation, we propose a strategy to migrate the temporal consistency in video diffusion models to the spatial-temporal consistency required for 4D generation. Specifically, we present a novel framework, \textbf{Diffusion4D}, for efficient and scalable 4D content generation. Leveraging a meticulously curated dynamic 3D dataset, we develop a 4D-aware video diffusion model capable of synthesizing orbital views of dynamic 3D assets. To control the dynamic strength of these assets, we introduce a 3D-to-4D motion magnitude metric as guidance. Additionally, we propose a novel motion magnitude reconstruction loss and 3D-aware classifier-free guidance to refine the learning and generation of motion dynamics. After obtaining orbital views of the 4D asset, we perform explicit 4D construction with Gaussian splatting in a coarse-to-fine manner. The synthesized multi-view consistent 4D image set enables us to swiftly generate high-fidelity and diverse 4D assets within just several minutes. Extensive experiments demonstrate that our method surpasses prior state-of-the-art techniques in terms of generation efficiency and 4D geometry consistency across various prompt modalities.
Comp4D: LLM-Guided Compositional 4D Scene Generation
Mar 25, 2024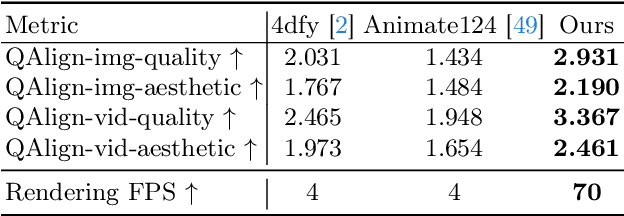
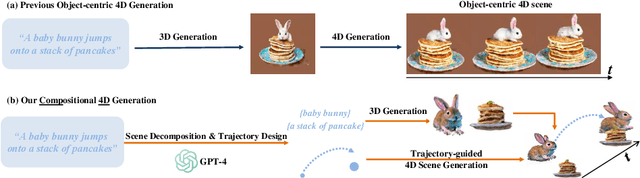

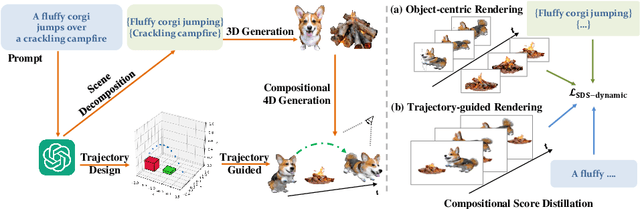
Recent advancements in diffusion models for 2D and 3D content creation have sparked a surge of interest in generating 4D content. However, the scarcity of 3D scene datasets constrains current methodologies to primarily object-centric generation. To overcome this limitation, we present Comp4D, a novel framework for Compositional 4D Generation. Unlike conventional methods that generate a singular 4D representation of the entire scene, Comp4D innovatively constructs each 4D object within the scene separately. Utilizing Large Language Models (LLMs), the framework begins by decomposing an input text prompt into distinct entities and maps out their trajectories. It then constructs the compositional 4D scene by accurately positioning these objects along their designated paths. To refine the scene, our method employs a compositional score distillation technique guided by the pre-defined trajectories, utilizing pre-trained diffusion models across text-to-image, text-to-video, and text-to-3D domains. Extensive experiments demonstrate our outstanding 4D content creation capability compared to prior arts, showcasing superior visual quality, motion fidelity, and enhanced object interactions.
Enhancing NeRF akin to Enhancing LLMs: Generalizable NeRF Transformer with Mixture-of-View-Experts
Aug 22, 2023Cross-scene generalizable NeRF models, which can directly synthesize novel views of unseen scenes, have become a new spotlight of the NeRF field. Several existing attempts rely on increasingly end-to-end "neuralized" architectures, i.e., replacing scene representation and/or rendering modules with performant neural networks such as transformers, and turning novel view synthesis into a feed-forward inference pipeline. While those feedforward "neuralized" architectures still do not fit diverse scenes well out of the box, we propose to bridge them with the powerful Mixture-of-Experts (MoE) idea from large language models (LLMs), which has demonstrated superior generalization ability by balancing between larger overall model capacity and flexible per-instance specialization. Starting from a recent generalizable NeRF architecture called GNT, we first demonstrate that MoE can be neatly plugged in to enhance the model. We further customize a shared permanent expert and a geometry-aware consistency loss to enforce cross-scene consistency and spatial smoothness respectively, which are essential for generalizable view synthesis. Our proposed model, dubbed GNT with Mixture-of-View-Experts (GNT-MOVE), has experimentally shown state-of-the-art results when transferring to unseen scenes, indicating remarkably better cross-scene generalization in both zero-shot and few-shot settings. Our codes are available at https://github.com/VITA-Group/GNT-MOVE.
Edge-MoE: Memory-Efficient Multi-Task Vision Transformer Architecture with Task-level Sparsity via Mixture-of-Experts
May 30, 2023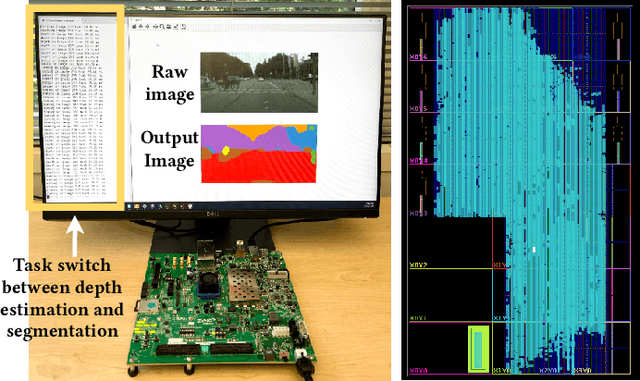


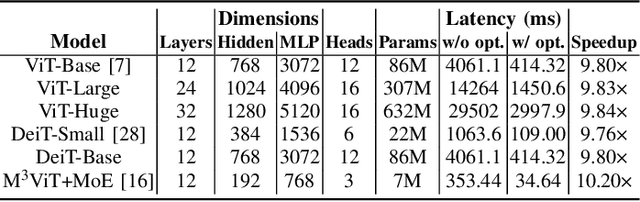
Computer vision researchers are embracing two promising paradigms: Vision Transformers (ViTs) and Multi-task Learning (MTL), which both show great performance but are computation-intensive, given the quadratic complexity of self-attention in ViT and the need to activate an entire large MTL model for one task. M$^3$ViT is the latest multi-task ViT model that introduces mixture-of-experts (MoE), where only a small portion of subnetworks ("experts") are sparsely and dynamically activated based on the current task. M$^3$ViT achieves better accuracy and over 80% computation reduction but leaves challenges for efficient deployment on FPGA. Our work, dubbed Edge-MoE, solves the challenges to introduce the first end-to-end FPGA accelerator for multi-task ViT with a collection of architectural innovations, including (1) a novel reordering mechanism for self-attention, which requires only constant bandwidth regardless of the target parallelism; (2) a fast single-pass softmax approximation; (3) an accurate and low-cost GELU approximation; (4) a unified and flexible computing unit that is shared by almost all computational layers to maximally reduce resource usage; and (5) uniquely for M$^3$ViT, a novel patch reordering method to eliminate memory access overhead. Edge-MoE achieves 2.24x and 4.90x better energy efficiency comparing with GPU and CPU, respectively. A real-time video demonstration is available online, along with our code written using High-Level Synthesis, which will be open-sourced.
Perceptual Quality Assessment of NeRF and Neural View Synthesis Methods for Front-Facing Views
Apr 02, 2023Neural view synthesis (NVS) is one of the most successful techniques for synthesizing free viewpoint videos, capable of achieving high fidelity from only a sparse set of captured images. This success has led to many variants of the techniques, each evaluated on a set of test views typically using image quality metrics such as PSNR, SSIM, or LPIPS. There has been a lack of research on how NVS methods perform with respect to perceived video quality. We present the first study on perceptual evaluation of NVS and NeRF variants. For this study, we collected two datasets of scenes captured in a controlled lab environment as well as in-the-wild. In contrast to existing datasets, these scenes come with reference video sequences, allowing us to test for temporal artifacts and subtle distortions that are easily overlooked when viewing only static images. We measured the quality of videos synthesized by several NVS methods in a well-controlled perceptual quality assessment experiment as well as with many existing state-of-the-art image/video quality metrics. We present a detailed analysis of the results and recommendations for dataset and metric selection for NVS evaluation.