 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCameraVDP: Perceptual Display Assessment with Uncertainty Estimation via Camera and Visual Difference Prediction
Sep 10, 2025Accurate measurement of images produced by electronic displays is critical for the evaluation of both traditional and computational displays. Traditional display measurement methods based on sparse radiometric sampling and fitting a model are inadequate for capturing spatially varying display artifacts, as they fail to capture high-frequency and pixel-level distortions. While cameras offer sufficient spatial resolution, they introduce optical, sampling, and photometric distortions. Furthermore, the physical measurement must be combined with a model of a visual system to assess whether the distortions are going to be visible. To enable perceptual assessment of displays, we propose a combination of a camera-based reconstruction pipeline with a visual difference predictor, which account for both the inaccuracy of camera measurements and visual difference prediction. The reconstruction pipeline combines HDR image stacking, MTF inversion, vignetting correction, geometric undistortion, homography transformation, and color correction, enabling cameras to function as precise display measurement instruments. By incorporating a Visual Difference Predictor (VDP), our system models the visibility of various stimuli under different viewing conditions for the human visual system. We validate the proposed CameraVDP framework through three applications: defective pixel detection, color fringing awareness, and display non-uniformity evaluation. Our uncertainty analysis framework enables the estimation of the theoretical upper bound for defect pixel detection performance and provides confidence intervals for VDP quality scores.
Do computer vision foundation models learn the low-level characteristics of the human visual system?
Feb 27, 2025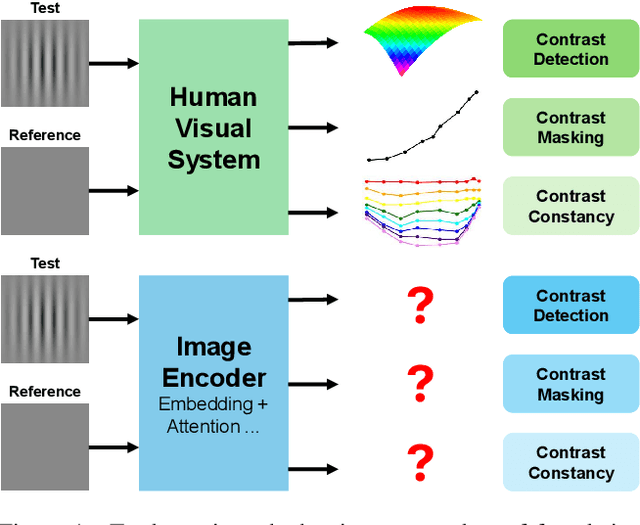
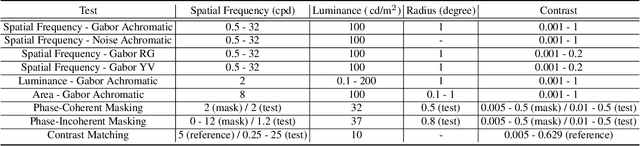
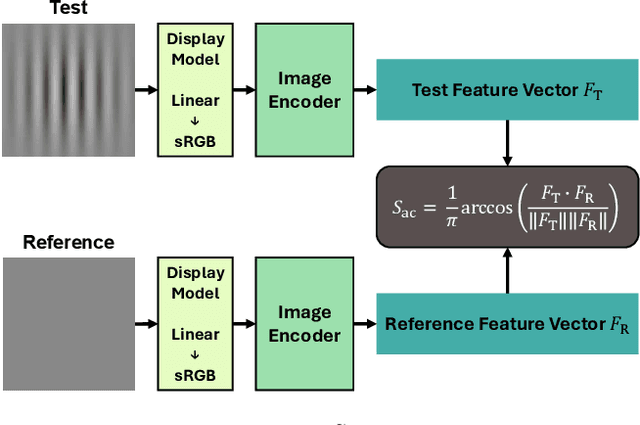
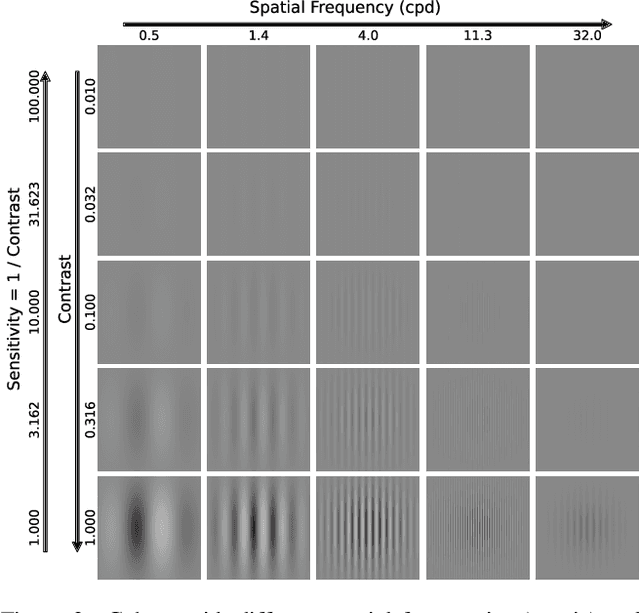
Computer vision foundation models, such as DINO or OpenCLIP, are trained in a self-supervised manner on large image datasets. Analogously, substantial evidence suggests that the human visual system (HVS) is influenced by the statistical distribution of colors and patterns in the natural world, characteristics also present in the training data of foundation models. The question we address in this paper is whether foundation models trained on natural images mimic some of the low-level characteristics of the human visual system, such as contrast detection, contrast masking, and contrast constancy. Specifically, we designed a protocol comprising nine test types to evaluate the image encoders of 45 foundation and generative models. Our results indicate that some foundation models (e.g., DINO, DINOv2, and OpenCLIP), share some of the characteristics of human vision, but other models show little resemblance. Foundation models tend to show smaller sensitivity to low contrast and rather irregular responses to contrast across frequencies. The foundation models show the best agreement with human data in terms of contrast masking. Our findings suggest that human vision and computer vision may take both similar and different paths when learning to interpret images of the real world. Overall, while differences remain, foundation models trained on vision tasks start to align with low-level human vision, with DINOv2 showing the closest resemblance.
Physically Based Neural Bidirectional Reflectance Distribution Function
Nov 04, 2024We introduce the physically based neural bidirectional reflectance distribution function (PBNBRDF), a novel, continuous representation for material appearance based on neural fields. Our model accurately reconstructs real-world materials while uniquely enforcing physical properties for realistic BRDFs, specifically Helmholtz reciprocity via reparametrization and energy passivity via efficient analytical integration. We conduct a systematic analysis demonstrating the benefits of adhering to these physical laws on the visual quality of reconstructed materials. Additionally, we enhance the color accuracy of neural BRDFs by introducing chromaticity enforcement supervising the norms of RGB channels. Through both qualitative and quantitative experiments on multiple databases of measured real-world BRDFs, we show that adhering to these physical constraints enables neural fields to more faithfully and stably represent the original data and achieve higher rendering quality.
Training Neural Networks on RAW and HDR Images for Restoration Tasks
Dec 06, 2023The vast majority of standard image and video content available online is represented in display-encoded color spaces, in which pixel values are conveniently scaled to a limited range (0-1) and the color distribution is approximately perceptually uniform. In contrast, both camera RAW and high dynamic range (HDR) images are often represented in linear color spaces, in which color values are linearly related to colorimetric quantities of light. While training on commonly available display-encoded images is a well-established practice, there is no consensus on how neural networks should be trained for tasks on RAW and HDR images in linear color spaces. In this work, we test several approaches on three popular image restoration applications: denoising, deblurring, and single-image super-resolution. We examine whether HDR/RAW images need to be display-encoded using popular transfer functions (PQ, PU21, mu-law), or whether it is better to train in linear color spaces, but use loss functions that correct for perceptual non-uniformity. Our results indicate that neural networks train significantly better on HDR and RAW images represented in display-encoded color spaces, which offer better perceptual uniformity than linear spaces. This small change to the training strategy can bring a very substantial gain in performance, up to 10-15 dB.
Stereoscopic Depth Perception Through Foliage
Oct 24, 2023Both humans and computational methods struggle to discriminate the depths of objects hidden beneath foliage. However, such discrimination becomes feasible when we combine computational optical synthetic aperture sensing with the human ability to fuse stereoscopic images. For object identification tasks, as required in search and rescue, wildlife observation, surveillance, and early wildfire detection, depth assists in differentiating true from false findings, such as people, animals, or vehicles vs. sun-heated patches at the ground level or in the tree crowns, or ground fires vs. tree trunks. We used video captured by a drone above dense woodland to test users' ability to discriminate depth. We found that this is impossible when viewing monoscopic video and relying on motion parallax. The same was true with stereoscopic video because of the occlusions caused by foliage. However, when synthetic aperture sensing was used to reduce occlusions and disparity-scaled stereoscopic video was presented, whereas computational (stereoscopic matching) methods were unsuccessful, human observers successfully discriminated depth. This shows the potential of systems which exploit the synergy between computational methods and human vision to perform tasks that neither can perform alone.
Perceptual Quality Assessment of NeRF and Neural View Synthesis Methods for Front-Facing Views
Apr 02, 2023Neural view synthesis (NVS) is one of the most successful techniques for synthesizing free viewpoint videos, capable of achieving high fidelity from only a sparse set of captured images. This success has led to many variants of the techniques, each evaluated on a set of test views typically using image quality metrics such as PSNR, SSIM, or LPIPS. There has been a lack of research on how NVS methods perform with respect to perceived video quality. We present the first study on perceptual evaluation of NVS and NeRF variants. For this study, we collected two datasets of scenes captured in a controlled lab environment as well as in-the-wild. In contrast to existing datasets, these scenes come with reference video sequences, allowing us to test for temporal artifacts and subtle distortions that are easily overlooked when viewing only static images. We measured the quality of videos synthesized by several NVS methods in a well-controlled perceptual quality assessment experiment as well as with many existing state-of-the-art image/video quality metrics. We present a detailed analysis of the results and recommendations for dataset and metric selection for NVS evaluation.
G-SemTMO: Tone Mapping with a Trainable Semantic Graph
Aug 30, 2022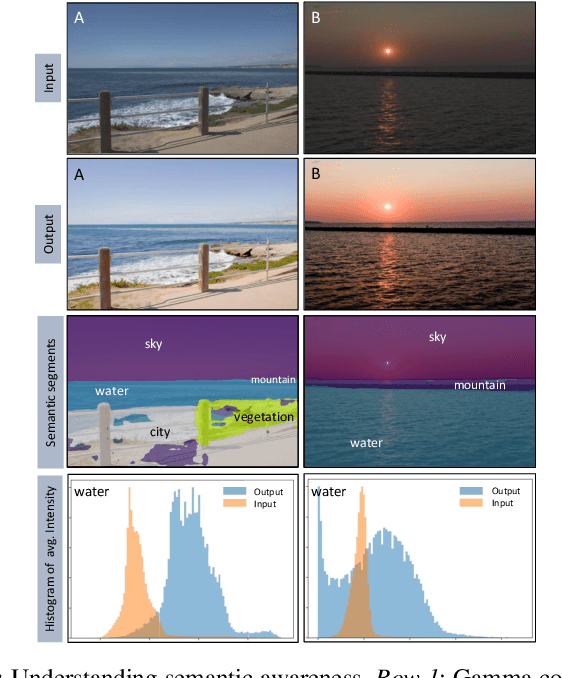
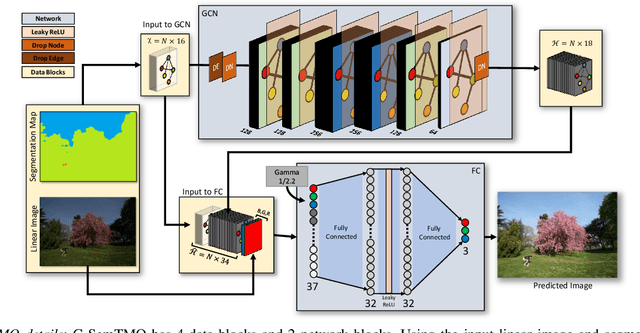
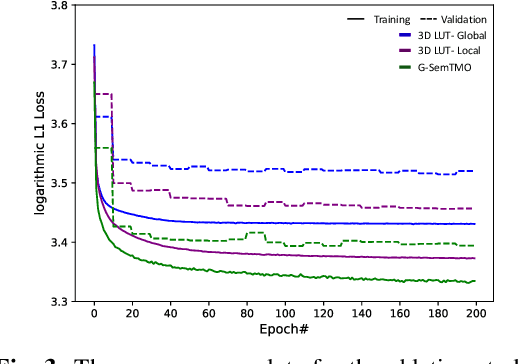

A Tone Mapping Operator (TMO) is required to render images with a High Dynamic Range (HDR) on media with limited dynamic capabilities. TMOs compress the dynamic range with the aim of preserving the visually perceptual cues of the scene. Previous literature has established the benefits of TMOs being semantic aware, understanding the content in the scene to preserve the cues better. Expert photographers analyze the semantic and the contextual information of a scene and decide tonal transformations or local luminance adjustments. This process can be considered a manual analogy to tone mapping. In this work, we draw inspiration from an expert photographer's approach and present a Graph-based Semantic-aware Tone Mapping Operator, G-SemTMO. We leverage semantic information as well as the contextual information of the scene in the form of a graph capturing the spatial arrangements of its semantic segments. Using Graph Convolutional Network (GCN), we predict intermediate parameters called Semantic Hints and use these parameters to apply tonal adjustments locally to different semantic segments in the image. In addition, we also introduce LocHDR, a dataset of 781 HDR images tone mapped manually by an expert photo-retoucher with local tonal enhancements. We conduct ablation studies to show that our approach, G-SemTMO\footnote{Code and dataset to be published with the final version of the manuscript}, can learn both global and local tonal transformations from a pair of input linear and manually retouched images by leveraging the semantic graphs and produce better results than both classical and learning based TMOs. We also conduct ablation experiments to validate the advantage of using GCN.
Active Sampling for Pairwise Comparisons via Approximate Message Passing and Information Gain Maximization
Apr 12, 2020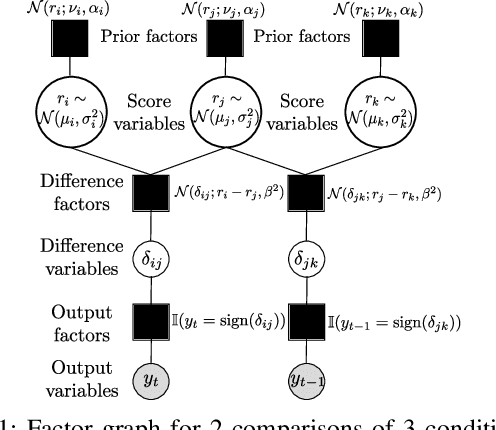
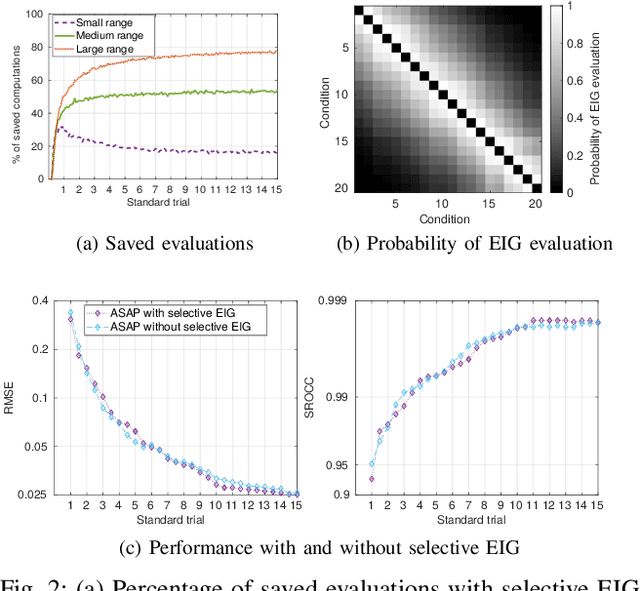
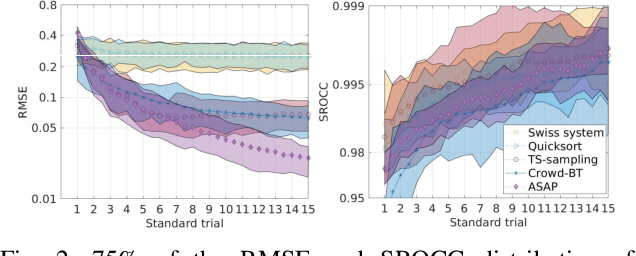
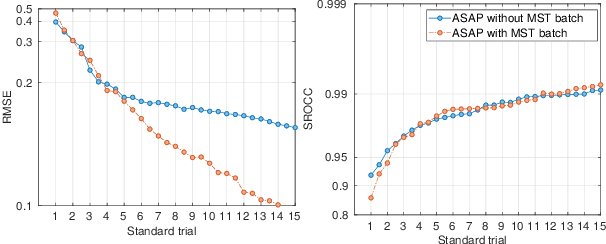
Pairwise comparison data arise in many domains with subjective assessment experiments, for example in image and video quality assessment. In these experiments observers are asked to express a preference between two conditions. However, many pairwise comparison protocols require a large number of comparisons to infer accurate scores, which may be unfeasible when each comparison is time-consuming (e.g. videos) or expensive (e.g. medical imaging). This motivates the use of an active sampling algorithm that chooses only the most informative pairs for comparison. In this paper we propose ASAP, an active sampling algorithm based on approximate message passing and expected information gain maximization. Unlike most existing methods, which rely on partial updates of the posterior distribution, we are able to perform full updates and therefore much improve the accuracy of the inferred scores. The algorithm relies on three techniques for reducing computational cost: inference based on approximate message passing, selective evaluations of the information gain, and selecting pairs in a batch that forms a minimum spanning tree of the inverse of information gain. We demonstrate, with real and synthetic data, that ASAP offers the highest accuracy of inferred scores compared to the existing methods. We also provide an open-source GPU implementation of ASAP for large-scale experiments.
Exploiting Synthetically Generated Data with Semi-Supervised Learning for Small and Imbalanced Datasets
Mar 24, 2019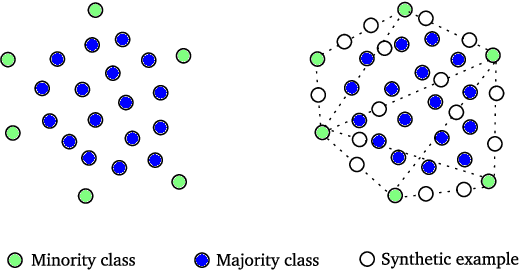
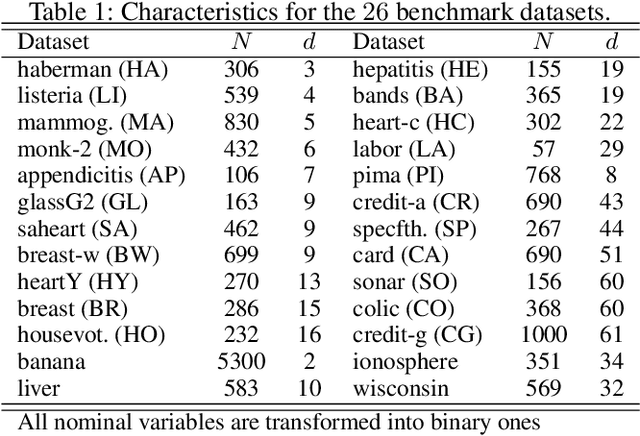
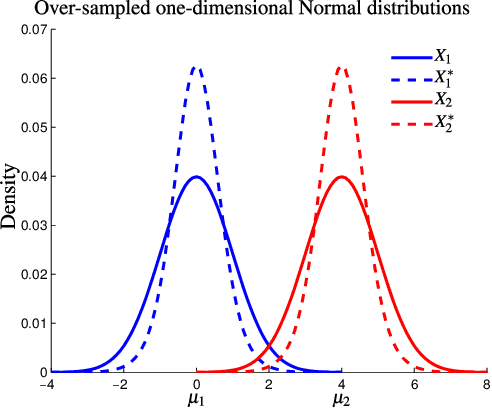
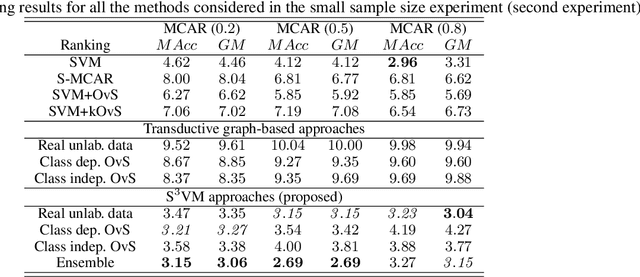
Data augmentation is rapidly gaining attention in machine learning. Synthetic data can be generated by simple transformations or through the data distribution. In the latter case, the main challenge is to estimate the label associated to new synthetic patterns. This paper studies the effect of generating synthetic data by convex combination of patterns and the use of these as unsupervised information in a semi-supervised learning framework with support vector machines, avoiding thus the need to label synthetic examples. We perform experiments on a total of 53 binary classification datasets. Our results show that this type of data over-sampling supports the well-known cluster assumption in semi-supervised learning, showing outstanding results for small high-dimensional datasets and imbalanced learning problems.