 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal Deep Research for AI, Robotics and Beyond
Oct 23, 2025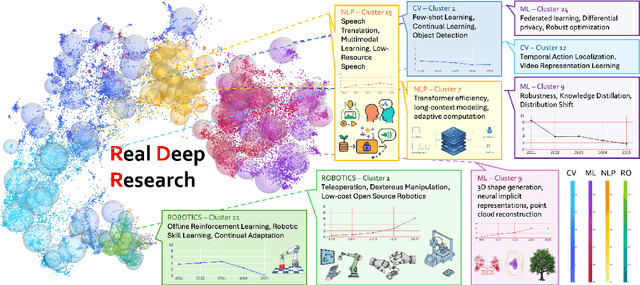
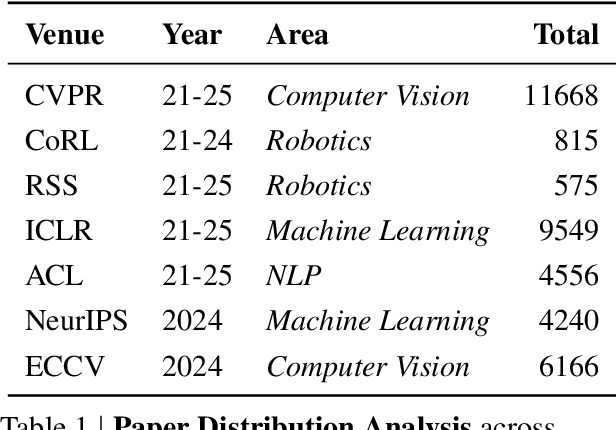
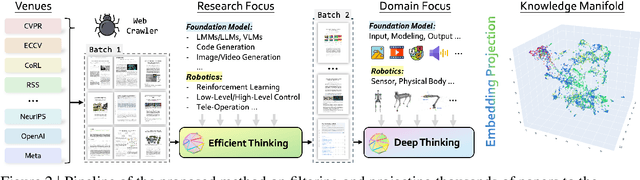
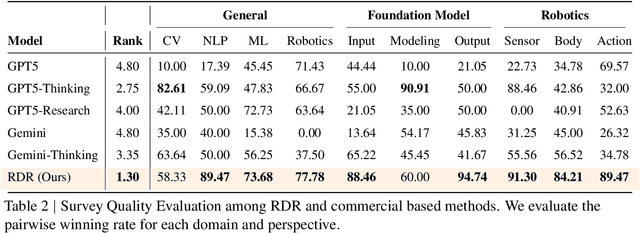
With the rapid growth of research in AI and robotics now producing over 10,000 papers annually it has become increasingly difficult for researchers to stay up to date. Fast evolving trends, the rise of interdisciplinary work, and the need to explore domains beyond one's expertise all contribute to this challenge. To address these issues, we propose a generalizable pipeline capable of systematically analyzing any research area: identifying emerging trends, uncovering cross domain opportunities, and offering concrete starting points for new inquiry. In this work, we present Real Deep Research (RDR) a comprehensive framework applied to the domains of AI and robotics, with a particular focus on foundation models and robotics advancements. We also briefly extend our analysis to other areas of science. The main paper details the construction of the RDR pipeline, while the appendix provides extensive results across each analyzed topic. We hope this work sheds light for researchers working in the field of AI and beyond.
A Survey on Text-Driven 360-Degree Panorama Generation
Feb 20, 2025



The advent of text-driven 360-degree panorama generation, enabling the synthesis of 360-degree panoramic images directly from textual descriptions, marks a transformative advancement in immersive visual content creation. This innovation significantly simplifies the traditionally complex process of producing such content. Recent progress in text-to-image diffusion models has accelerated the rapid development in this emerging field. This survey presents a comprehensive review of text-driven 360-degree panorama generation, offering an in-depth analysis of state-of-the-art algorithms and their expanding applications in 360-degree 3D scene generation. Furthermore, we critically examine current limitations and propose promising directions for future research. A curated project page with relevant resources and research papers is available at https://littlewhitesea.github.io/Text-Driven-Pano-Gen/.
Make-A-Texture: Fast Shape-Aware Texture Generation in 3 Seconds
Dec 10, 2024



We present Make-A-Texture, a new framework that efficiently synthesizes high-resolution texture maps from textual prompts for given 3D geometries. Our approach progressively generates textures that are consistent across multiple viewpoints with a depth-aware inpainting diffusion model, in an optimized sequence of viewpoints determined by an automatic view selection algorithm. A significant feature of our method is its remarkable efficiency, achieving a full texture generation within an end-to-end runtime of just 3.07 seconds on a single NVIDIA H100 GPU, significantly outperforming existing methods. Such an acceleration is achieved by optimizations in the diffusion model and a specialized backprojection method. Moreover, our method reduces the artifacts in the backprojection phase, by selectively masking out non-frontal faces, and internal faces of open-surfaced objects. Experimental results demonstrate that Make-A-Texture matches or exceeds the quality of other state-of-the-art methods. Our work significantly improves the applicability and practicality of texture generation models for real-world 3D content creation, including interactive creation and text-guided texture editing.
Efficient Track Anything
Nov 28, 2024Segment Anything Model 2 (SAM 2) has emerged as a powerful tool for video object segmentation and tracking anything. Key components of SAM 2 that drive the impressive video object segmentation performance include a large multistage image encoder for frame feature extraction and a memory mechanism that stores memory contexts from past frames to help current frame segmentation. The high computation complexity of multistage image encoder and memory module has limited its applications in real-world tasks, e.g., video object segmentation on mobile devices. To address this limitation, we propose EfficientTAMs, lightweight track anything models that produce high-quality results with low latency and model size. Our idea is based on revisiting the plain, nonhierarchical Vision Transformer (ViT) as an image encoder for video object segmentation, and introducing an efficient memory module, which reduces the complexity for both frame feature extraction and memory computation for current frame segmentation. We take vanilla lightweight ViTs and efficient memory module to build EfficientTAMs, and train the models on SA-1B and SA-V datasets for video object segmentation and track anything tasks. We evaluate on multiple video segmentation benchmarks including semi-supervised VOS and promptable video segmentation, and find that our proposed EfficientTAM with vanilla ViT perform comparably to SAM 2 model (HieraB+SAM 2) with ~2x speedup on A100 and ~2.4x parameter reduction. On segment anything image tasks, our EfficientTAMs also perform favorably over original SAM with ~20x speedup on A100 and ~20x parameter reduction. On mobile devices such as iPhone 15 Pro Max, our EfficientTAMs can run at ~10 FPS for performing video object segmentation with reasonable quality, highlighting the capability of small models for on-device video object segmentation applications.
UnSAMFlow: Unsupervised Optical Flow Guided by Segment Anything Model
May 04, 2024



Traditional unsupervised optical flow methods are vulnerable to occlusions and motion boundaries due to lack of object-level information. Therefore, we propose UnSAMFlow, an unsupervised flow network that also leverages object information from the latest foundation model Segment Anything Model (SAM). We first include a self-supervised semantic augmentation module tailored to SAM masks. We also analyze the poor gradient landscapes of traditional smoothness losses and propose a new smoothness definition based on homography instead. A simple yet effective mask feature module has also been added to further aggregate features on the object level. With all these adaptations, our method produces clear optical flow estimation with sharp boundaries around objects, which outperforms state-of-the-art methods on both KITTI and Sintel datasets. Our method also generalizes well across domains and runs very efficiently.
Garment3DGen: 3D Garment Stylization and Texture Generation
Mar 27, 2024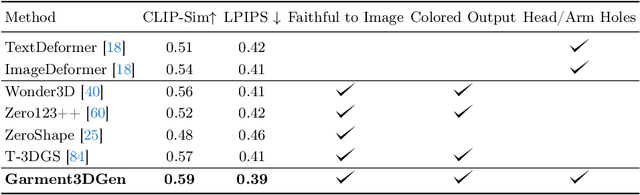
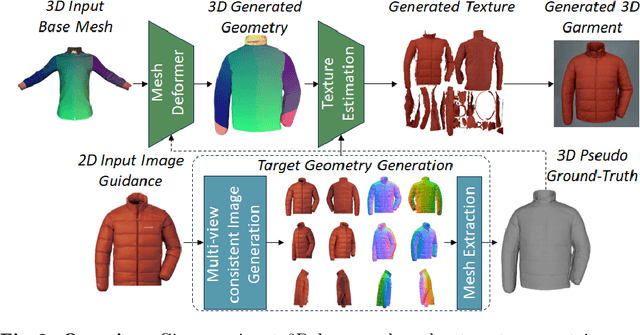


We introduce Garment3DGen a new method to synthesize 3D garment assets from a base mesh given a single input image as guidance. Our proposed approach allows users to generate 3D textured clothes based on both real and synthetic images, such as those generated by text prompts. The generated assets can be directly draped and simulated on human bodies. First, we leverage the recent progress of image to 3D diffusion methods to generate 3D garment geometries. However, since these geometries cannot be utilized directly for downstream tasks, we propose to use them as pseudo ground-truth and set up a mesh deformation optimization procedure that deforms a base template mesh to match the generated 3D target. Second, we introduce carefully designed losses that allow the input base mesh to freely deform towards the desired target, yet preserve mesh quality and topology such that they can be simulated. Finally, a texture estimation module generates high-fidelity texture maps that are globally and locally consistent and faithfully capture the input guidance, allowing us to render the generated 3D assets. With Garment3DGen users can generate the textured 3D garment of their choice without the need of artist intervention. One can provide a textual prompt describing the garment they desire to generate a simulation-ready 3D asset. We present a plethora of quantitative and qualitative comparisons on various assets both real and generated and provide use-cases of how one can generate simulation-ready 3D garments.
PlatoNeRF: 3D Reconstruction in Plato's Cave via Single-View Two-Bounce Lidar
Dec 21, 2023



3D reconstruction from a single-view is challenging because of the ambiguity from monocular cues and lack of information about occluded regions. Neural radiance fields (NeRF), while popular for view synthesis and 3D reconstruction, are typically reliant on multi-view images. Existing methods for single-view 3D reconstruction with NeRF rely on either data priors to hallucinate views of occluded regions, which may not be physically accurate, or shadows observed by RGB cameras, which are difficult to detect in ambient light and low albedo backgrounds. We propose using time-of-flight data captured by a single-photon avalanche diode to overcome these limitations. Our method models two-bounce optical paths with NeRF, using lidar transient data for supervision. By leveraging the advantages of both NeRF and two-bounce light measured by lidar, we demonstrate that we can reconstruct visible and occluded geometry without data priors or reliance on controlled ambient lighting or scene albedo. In addition, we demonstrate improved generalization under practical constraints on sensor spatial- and temporal-resolution. We believe our method is a promising direction as single-photon lidars become ubiquitous on consumer devices, such as phones, tablets, and headsets.
CAD: Photorealistic 3D Generation via Adversarial Distillation
Dec 11, 2023



The increased demand for 3D data in AR/VR, robotics and gaming applications, gave rise to powerful generative pipelines capable of synthesizing high-quality 3D objects. Most of these models rely on the Score Distillation Sampling (SDS) algorithm to optimize a 3D representation such that the rendered image maintains a high likelihood as evaluated by a pre-trained diffusion model. However, finding a correct mode in the high-dimensional distribution produced by the diffusion model is challenging and often leads to issues such as over-saturation, over-smoothing, and Janus-like artifacts. In this paper, we propose a novel learning paradigm for 3D synthesis that utilizes pre-trained diffusion models. Instead of focusing on mode-seeking, our method directly models the distribution discrepancy between multi-view renderings and diffusion priors in an adversarial manner, which unlocks the generation of high-fidelity and photorealistic 3D content, conditioned on a single image and prompt. Moreover, by harnessing the latent space of GANs and expressive diffusion model priors, our method facilitates a wide variety of 3D applications including single-view reconstruction, high diversity generation and continuous 3D interpolation in the open domain. The experiments demonstrate the superiority of our pipeline compared to previous works in terms of generation quality and diversity.
SqueezeSAM: User friendly mobile interactive segmentation
Dec 11, 2023Segment Anything Model (SAM) is a foundation model for interactive segmentation, and it has catalyzed major advances in generative AI, computational photography, and medical imaging. This model takes in an arbitrary user input and provides segmentation masks of the corresponding objects. It is our goal to develop a version of SAM that is appropriate for use in a photography app. The original SAM model has a few challenges in this setting. First, original SAM a 600 million parameter based on ViT-H, and its high computational cost and large model size that are not suitable for todays mobile hardware. We address this by proposing the SqueezeSAM model architecture, which is 50x faster and 100x smaller than SAM. Next, when a user takes a photo on their phone, it might not occur to them to click on the image and get a mask. Our solution is to use salient object detection to generate the first few clicks. This produces an initial segmentation mask that the user can interactively edit. Finally, when a user clicks on an object, they typically expect all related pieces of the object to be segmented. For instance, if a user clicks on a person t-shirt in a photo, they expect the whole person to be segmented, but SAM typically segments just the t-shirt. We address this with a new data augmentation scheme, and the end result is that if the user clicks on a person holding a basketball, the person and the basketball are all segmented together.
Training Neural Networks on RAW and HDR Images for Restoration Tasks
Dec 06, 2023The vast majority of standard image and video content available online is represented in display-encoded color spaces, in which pixel values are conveniently scaled to a limited range (0-1) and the color distribution is approximately perceptually uniform. In contrast, both camera RAW and high dynamic range (HDR) images are often represented in linear color spaces, in which color values are linearly related to colorimetric quantities of light. While training on commonly available display-encoded images is a well-established practice, there is no consensus on how neural networks should be trained for tasks on RAW and HDR images in linear color spaces. In this work, we test several approaches on three popular image restoration applications: denoising, deblurring, and single-image super-resolution. We examine whether HDR/RAW images need to be display-encoded using popular transfer functions (PQ, PU21, mu-law), or whether it is better to train in linear color spaces, but use loss functions that correct for perceptual non-uniformity. Our results indicate that neural networks train significantly better on HDR and RAW images represented in display-encoded color spaces, which offer better perceptual uniformity than linear spaces. This small change to the training strategy can bring a very substantial gain in performance, up to 10-15 dB.