 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuartet of Diffusions: Structure-Aware Point Cloud Generation through Part and Symmetry Guidance
Jan 28, 2026We introduce the Quartet of Diffusions, a structure-aware point cloud generation framework that explicitly models part composition and symmetry. Unlike prior methods that treat shape generation as a holistic process or only support part composition, our approach leverages four coordinated diffusion models to learn distributions of global shape latents, symmetries, semantic parts, and their spatial assembly. This structured pipeline ensures guaranteed symmetry, coherent part placement, and diverse, high-quality outputs. By disentangling the generative process into interpretable components, our method supports fine-grained control over shape attributes, enabling targeted manipulation of individual parts while preserving global consistency. A central global latent further reinforces structural coherence across assembled parts. Our experiments show that the Quartet achieves state-of-the-art performance. To our best knowledge, this is the first 3D point cloud generation framework that fully integrates and enforces both symmetry and part priors throughout the generative process.
DMSORT: An efficient parallel maritime multi-object tracking architecture for unmanned vessel platforms
Nov 16, 2025



Accurate perception of the marine environment through robust multi-object tracking (MOT) is essential for ensuring safe vessel navigation and effective maritime surveillance. However, the complicated maritime environment often causes camera motion and subsequent visual degradation, posing significant challenges to MOT. To address this challenge, we propose an efficient Dual-branch Maritime SORT (DMSORT) method for maritime MOT. The core of the framework is a parallel tracker with affine compensation, which incorporates an object detection and re-identification (ReID) branch, along with a dedicated branch for dynamic camera motion estimation. Specifically, a Reversible Columnar Detection Network (RCDN) is integrated into the detection module to leverage multi-level visual features for robust object detection. Furthermore, a lightweight Transformer-based appearance extractor (Li-TAE) is designed to capture global contextual information and generate robust appearance features. Another branch decouples platform-induced and target-intrinsic motion by constructing a projective transformation, applying platform-motion compensation within the Kalman filter, and thereby stabilizing true object trajectories. Finally, a clustering-optimized feature fusion module effectively combines motion and appearance cues to ensure identity consistency under noise, occlusion, and drift. Extensive evaluations on the Singapore Maritime Dataset demonstrate that DMSORT achieves state-of-the-art performance. Notably, DMSORT attains the fastest runtime among existing ReID-based MOT frameworks while maintaining high identity consistency and robustness to jitter and occlusion. Code is available at: https://github.com/BiscuitsLzy/DMSORT-An-efficient-parallel-maritime-multi-object-tracking-architecture-.
Multigranular Evaluation for Brain Visual Decoding
Jul 10, 2025Existing evaluation protocols for brain visual decoding predominantly rely on coarse metrics that obscure inter-model differences, lack neuroscientific foundation, and fail to capture fine-grained visual distinctions. To address these limitations, we introduce BASIC, a unified, multigranular evaluation framework that jointly quantifies structural fidelity, inferential alignment, and contextual coherence between decoded and ground truth images. For the structural level, we introduce a hierarchical suite of segmentation-based metrics, including foreground, semantic, instance, and component masks, anchored in granularity-aware correspondence across mask structures. For the semantic level, we extract structured scene representations encompassing objects, attributes, and relationships using multimodal large language models, enabling detailed, scalable, and context-rich comparisons with ground-truth stimuli. We benchmark a diverse set of visual decoding methods across multiple stimulus-neuroimaging datasets within this unified evaluation framework. Together, these criteria provide a more discriminative, interpretable, and comprehensive foundation for measuring brain visual decoding methods.
Exploring The Visual Feature Space for Multimodal Neural Decoding
May 21, 2025The intrication of brain signals drives research that leverages multimodal AI to align brain modalities with visual and textual data for explainable descriptions. However, most existing studies are limited to coarse interpretations, lacking essential details on object descriptions, locations, attributes, and their relationships. This leads to imprecise and ambiguous reconstructions when using such cues for visual decoding. To address this, we analyze different choices of vision feature spaces from pre-trained visual components within Multimodal Large Language Models (MLLMs) and introduce a zero-shot multimodal brain decoding method that interacts with these models to decode across multiple levels of granularities. % To assess a model's ability to decode fine details from brain signals, we propose the Multi-Granularity Brain Detail Understanding Benchmark (MG-BrainDub). This benchmark includes two key tasks: detailed descriptions and salient question-answering, with metrics highlighting key visual elements like objects, attributes, and relationships. Our approach enhances neural decoding precision and supports more accurate neuro-decoding applications. Code will be available at https://github.com/weihaox/VINDEX.
RETRO: REthinking Tactile Representation Learning with Material PriOrs
May 20, 2025
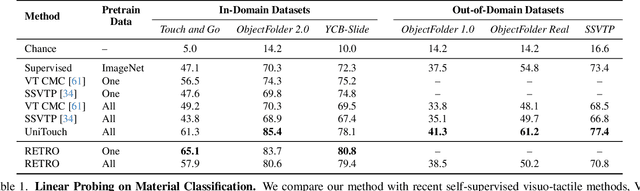
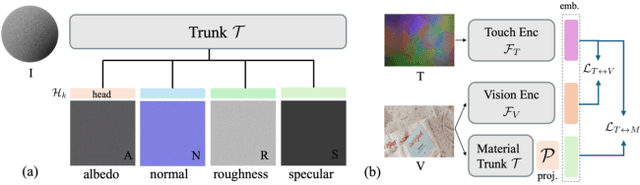
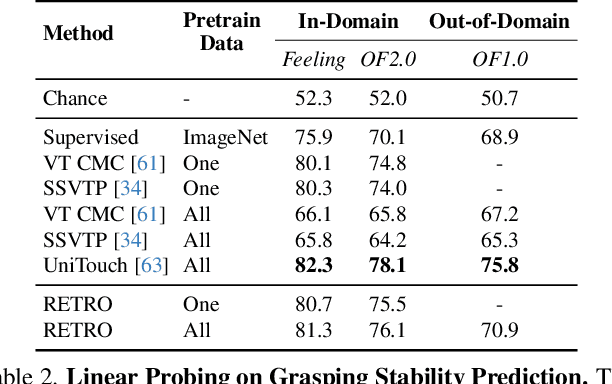
Tactile perception is profoundly influenced by the surface properties of objects in contact. However, despite their crucial role in shaping tactile experiences, these material characteristics have been largely neglected in existing tactile representation learning methods. Most approaches primarily focus on aligning tactile data with visual or textual information, overlooking the richness of tactile feedback that comes from understanding the materials' inherent properties. In this work, we address this gap by revisiting the tactile representation learning framework and incorporating material-aware priors into the learning process. These priors, which represent pre-learned characteristics specific to different materials, allow tactile models to better capture and generalize the nuances of surface texture. Our method enables more accurate, contextually rich tactile feedback across diverse materials and textures, improving performance in real-world applications such as robotics, haptic feedback systems, and material editing.
A Survey on Text-Driven 360-Degree Panorama Generation
Feb 20, 2025



The advent of text-driven 360-degree panorama generation, enabling the synthesis of 360-degree panoramic images directly from textual descriptions, marks a transformative advancement in immersive visual content creation. This innovation significantly simplifies the traditionally complex process of producing such content. Recent progress in text-to-image diffusion models has accelerated the rapid development in this emerging field. This survey presents a comprehensive review of text-driven 360-degree panorama generation, offering an in-depth analysis of state-of-the-art algorithms and their expanding applications in 360-degree 3D scene generation. Furthermore, we critically examine current limitations and propose promising directions for future research. A curated project page with relevant resources and research papers is available at https://littlewhitesea.github.io/Text-Driven-Pano-Gen/.
Physically Based Neural Bidirectional Reflectance Distribution Function
Nov 04, 2024We introduce the physically based neural bidirectional reflectance distribution function (PBNBRDF), a novel, continuous representation for material appearance based on neural fields. Our model accurately reconstructs real-world materials while uniquely enforcing physical properties for realistic BRDFs, specifically Helmholtz reciprocity via reparametrization and energy passivity via efficient analytical integration. We conduct a systematic analysis demonstrating the benefits of adhering to these physical laws on the visual quality of reconstructed materials. Additionally, we enhance the color accuracy of neural BRDFs by introducing chromaticity enforcement supervising the norms of RGB channels. Through both qualitative and quantitative experiments on multiple databases of measured real-world BRDFs, we show that adhering to these physical constraints enables neural fields to more faithfully and stably represent the original data and achieve higher rendering quality.
Temporal Streaming Batch Principal Component Analysis for Time Series Classification
Oct 28, 2024


In multivariate time series classification, although current sequence analysis models have excellent classification capabilities, they show significant shortcomings when dealing with long sequence multivariate data, such as prolonged training times and decreased accuracy. This paper focuses on optimizing model performance for long-sequence multivariate data by mitigating the impact of extended time series and multiple variables on the model. We propose a principal component analysis (PCA)-based temporal streaming compression and dimensionality reduction algorithm for time series data (temporal streaming batch PCA, TSBPCA), which continuously updates the compact representation of the entire sequence through streaming PCA time estimation with time block updates, enhancing the data representation capability of a range of sequence analysis models. We evaluated this method using various models on five real datasets, and the experimental results show that our method performs well in terms of classification accuracy and time efficiency. Notably, our method demonstrates a trend of increasing effectiveness as sequence length grows; on the two longest sequence datasets, accuracy improved by about 7.2%, and execution time decreased by 49.5%.
UMBRAE: Unified Multimodal Decoding of Brain Signals
Apr 10, 2024
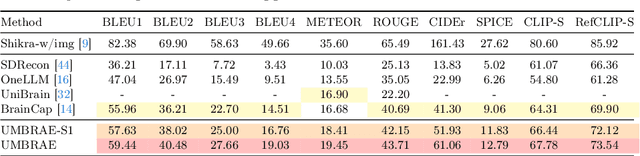
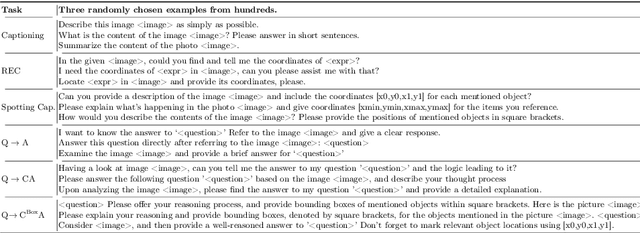
We address prevailing challenges of the brain-powered research, departing from the observation that the literature hardly recover accurate spatial information and require subject-specific models. To address these challenges, we propose UMBRAE, a unified multimodal decoding of brain signals. First, to extract instance-level conceptual and spatial details from neural signals, we introduce an efficient universal brain encoder for multimodal-brain alignment and recover object descriptions at multiple levels of granularity from subsequent multimodal large language model (MLLM). Second, we introduce a cross-subject training strategy mapping subject-specific features to a common feature space. This allows a model to be trained on multiple subjects without extra resources, even yielding superior results compared to subject-specific models. Further, we demonstrate this supports weakly-supervised adaptation to new subjects, with only a fraction of the total training data. Experiments demonstrate that UMBRAE not only achieves superior results in the newly introduced tasks but also outperforms methods in well established tasks. To assess our method, we construct and share with the community a comprehensive brain understanding benchmark BrainHub. Our code and benchmark are available at https://weihaox.github.io/UMBRAE.
DREAM: Visual Decoding from Reversing Human Visual System
Oct 03, 2023



In this work we present DREAM, an fMRI-to-image method for reconstructing viewed images from brain activities, grounded on fundamental knowledge of the human visual system. We craft reverse pathways that emulate the hierarchical and parallel nature of how humans perceive the visual world. These tailored pathways are specialized to decipher semantics, color, and depth cues from fMRI data, mirroring the forward pathways from visual stimuli to fMRI recordings. To do so, two components mimic the inverse processes within the human visual system: the Reverse Visual Association Cortex (R-VAC) which reverses pathways of this brain region, extracting semantics from fMRI data; the Reverse Parallel PKM (R-PKM) component simultaneously predicting color and depth from fMRI signals. The experiments indicate that our method outperforms the current state-of-the-art models in terms of the consistency of appearance, structure, and semantics. Code will be made publicly available to facilitate further research in this field.