 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-guided Kansa collocation for forward and inverse PDEs beyond linearity
Feb 08, 2026Partial Differential Equations are precise in modelling the physical, biological and graphical phenomena. However, the numerical methods suffer from the curse of dimensionality, high computation costs and domain-specific discretization. We aim to explore pros and cons of different PDE solvers, and apply them to specific scientific simulation problems, including forwarding solution, inverse problems and equations discovery. In particular, we extend the recent CNF (NeurIPS 2023) framework solver to multi-dependent-variable and non-linear settings, together with down-stream applications. The outcomes include implementation of selected methods, self-tuning techniques, evaluation on benchmark problems and a comprehensive survey of neural PDE solvers and scientific simulation applications.
Twist and Compute: The Cost of Pose in 3D Generative Diffusion
Nov 11, 2025

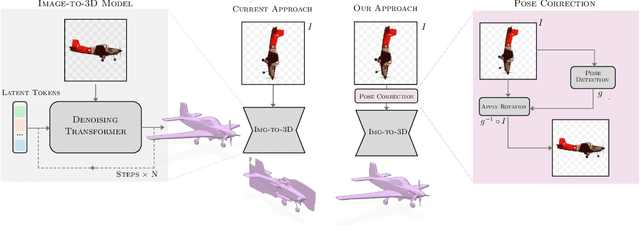

Despite their impressive results, large-scale image-to-3D generative models remain opaque in their inductive biases. We identify a significant limitation in image-conditioned 3D generative models: a strong canonical view bias. Through controlled experiments using simple 2D rotations, we show that the state-of-the-art Hunyuan3D 2.0 model can struggle to generalize across viewpoints, with performance degrading under rotated inputs. We show that this failure can be mitigated by a lightweight CNN that detects and corrects input orientation, restoring model performance without modifying the generative backbone. Our findings raise an important open question: Is scale enough, or should we pursue modular, symmetry-aware designs?
Self-Supervised Implicit Attention Priors for Point Cloud Reconstruction
Nov 06, 2025Recovering high-quality surfaces from irregular point cloud is ill-posed unless strong geometric priors are available. We introduce an implicit self-prior approach that distills a shape-specific prior directly from the input point cloud itself and embeds it within an implicit neural representation. This is achieved by jointly training a small dictionary of learnable embeddings with an implicit distance field; at every query location, the field attends to the dictionary via cross-attention, enabling the network to capture and reuse repeating structures and long-range correlations inherent to the shape. Optimized solely with self-supervised point cloud reconstruction losses, our approach requires no external training data. To effectively integrate this learned prior while preserving input fidelity, the trained field is then sampled to extract densely distributed points and analytic normals via automatic differentiation. We integrate the resulting dense point cloud and corresponding normals into a robust implicit moving least squares (RIMLS) formulation. We show this hybrid strategy preserves fine geometric details in the input data, while leveraging the learned prior to regularize sparse regions. Experiments show that our method outperforms both classical and learning-based approaches in generating high-fidelity surfaces with superior detail preservation and robustness to common data degradations.
CHOrD: Generation of Collision-Free, House-Scale, and Organized Digital Twins for 3D Indoor Scenes with Controllable Floor Plans and Optimal Layouts
Mar 15, 2025We introduce CHOrD, a novel framework for scalable synthesis of 3D indoor scenes, designed to create house-scale, collision-free, and hierarchically structured indoor digital twins. In contrast to existing methods that directly synthesize the scene layout as a scene graph or object list, CHOrD incorporates a 2D image-based intermediate layout representation, enabling effective prevention of collision artifacts by successfully capturing them as out-of-distribution (OOD) scenarios during generation. Furthermore, unlike existing methods, CHOrD is capable of generating scene layouts that adhere to complex floor plans with multi-modal controls, enabling the creation of coherent, house-wide layouts robust to both geometric and semantic variations in room structures. Additionally, we propose a novel dataset with expanded coverage of household items and room configurations, as well as significantly improved data quality. CHOrD demonstrates state-of-the-art performance on both the 3D-FRONT and our proposed datasets, delivering photorealistic, spatially coherent indoor scene synthesis adaptable to arbitrary floor plan variations.
UMBRAE: Unified Multimodal Decoding of Brain Signals
Apr 10, 2024
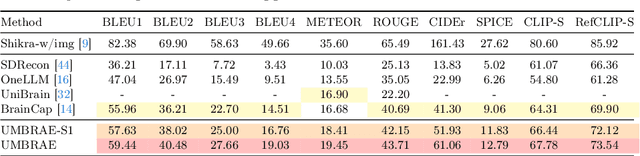
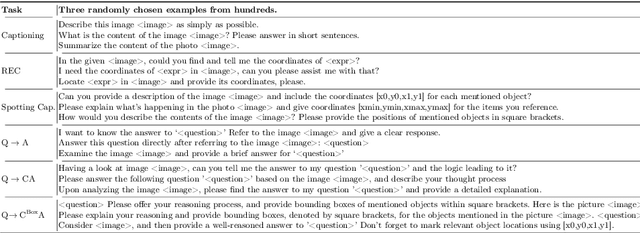
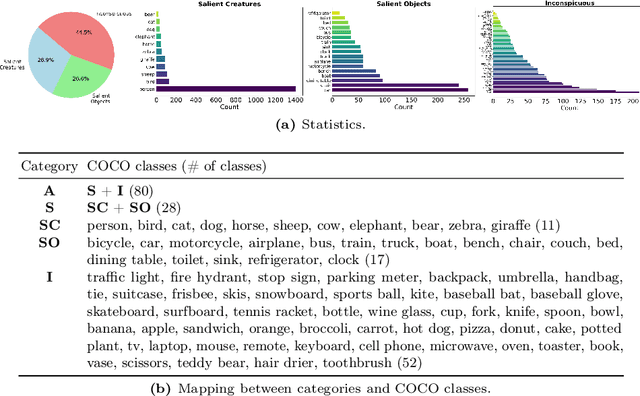
We address prevailing challenges of the brain-powered research, departing from the observation that the literature hardly recover accurate spatial information and require subject-specific models. To address these challenges, we propose UMBRAE, a unified multimodal decoding of brain signals. First, to extract instance-level conceptual and spatial details from neural signals, we introduce an efficient universal brain encoder for multimodal-brain alignment and recover object descriptions at multiple levels of granularity from subsequent multimodal large language model (MLLM). Second, we introduce a cross-subject training strategy mapping subject-specific features to a common feature space. This allows a model to be trained on multiple subjects without extra resources, even yielding superior results compared to subject-specific models. Further, we demonstrate this supports weakly-supervised adaptation to new subjects, with only a fraction of the total training data. Experiments demonstrate that UMBRAE not only achieves superior results in the newly introduced tasks but also outperforms methods in well established tasks. To assess our method, we construct and share with the community a comprehensive brain understanding benchmark BrainHub. Our code and benchmark are available at https://weihaox.github.io/UMBRAE.
Blue noise for diffusion models
Feb 07, 2024



Most of the existing diffusion models use Gaussian noise for training and sampling across all time steps, which may not optimally account for the frequency contents reconstructed by the denoising network. Despite the diverse applications of correlated noise in computer graphics, its potential for improving the training process has been underexplored. In this paper, we introduce a novel and general class of diffusion models taking correlated noise within and across images into account. More specifically, we propose a time-varying noise model to incorporate correlated noise into the training process, as well as a method for fast generation of correlated noise mask. Our model is built upon deterministic diffusion models and utilizes blue noise to help improve the generation quality compared to using Gaussian white (random) noise only. Further, our framework allows introducing correlation across images within a single mini-batch to improve gradient flow. We perform both qualitative and quantitative evaluations on a variety of datasets using our method, achieving improvements on different tasks over existing deterministic diffusion models in terms of FID metric.
Zero-Shot Machine Unlearning at Scale via Lipschitz Regularization
Feb 05, 2024



To comply with AI and data regulations, the need to forget private or copyrighted information from trained machine learning models is increasingly important. The key challenge in unlearning is forgetting the necessary data in a timely manner, while preserving model performance. In this work, we address the zero-shot unlearning scenario, whereby an unlearning algorithm must be able to remove data given only a trained model and the data to be forgotten. Under such a definition, existing state-of-the-art methods are insufficient. Building on the concepts of Lipschitz continuity, we present a method that induces smoothing of the forget sample's output, with respect to perturbations of that sample. We show this smoothing successfully results in forgetting while preserving general model performance. We perform extensive empirical evaluation of our method over a range of contemporary benchmarks, verifying that our method achieves state-of-the-art performance under the strict constraints of zero-shot unlearning.
DREAM: Visual Decoding from Reversing Human Visual System
Oct 03, 2023



In this work we present DREAM, an fMRI-to-image method for reconstructing viewed images from brain activities, grounded on fundamental knowledge of the human visual system. We craft reverse pathways that emulate the hierarchical and parallel nature of how humans perceive the visual world. These tailored pathways are specialized to decipher semantics, color, and depth cues from fMRI data, mirroring the forward pathways from visual stimuli to fMRI recordings. To do so, two components mimic the inverse processes within the human visual system: the Reverse Visual Association Cortex (R-VAC) which reverses pathways of this brain region, extracting semantics from fMRI data; the Reverse Parallel PKM (R-PKM) component simultaneously predicting color and depth from fMRI signals. The experiments indicate that our method outperforms the current state-of-the-art models in terms of the consistency of appearance, structure, and semantics. Code will be made publicly available to facilitate further research in this field.
Statistical shape representations for temporal registration of plant components in 3D
Sep 23, 2022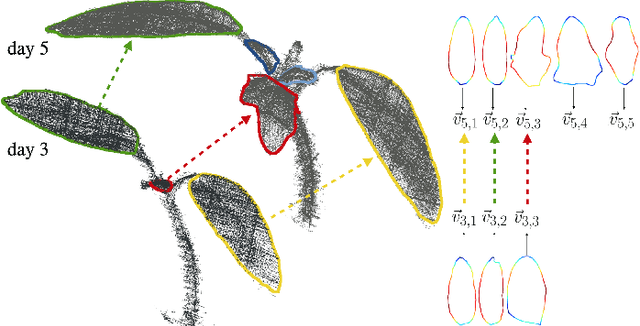
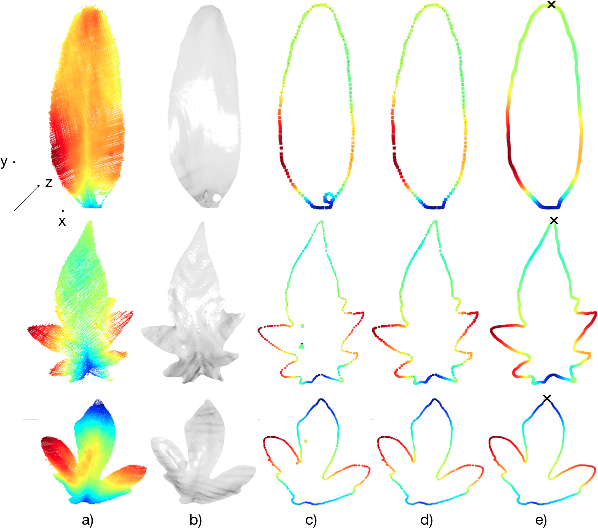
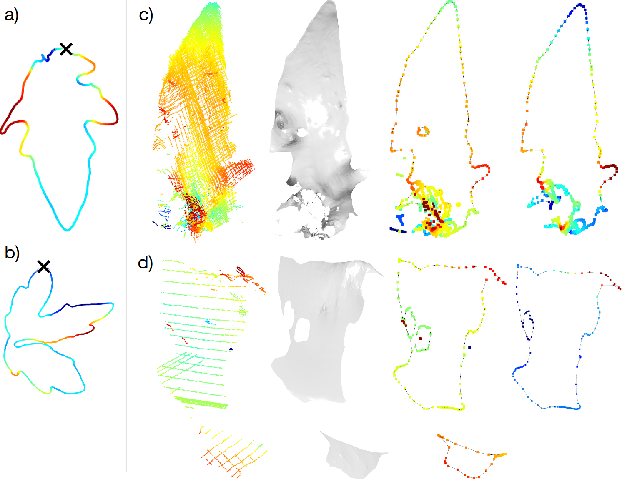
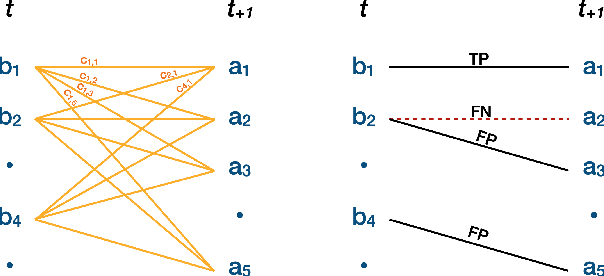
Plants are dynamic organisms. Understanding temporal variations in vegetation is an essential problem for all robots in the wild. However, associating repeated 3D scans of plants across time is challenging. A key step in this process is re-identifying and tracking the same individual plant components over time. Previously, this has been achieved by comparing their global spatial or topological location. In this work, we demonstrate how using shape features improves temporal organ matching. We present a landmark-free shape compression algorithm, which allows for the extraction of 3D shape features of leaves, characterises leaf shape and curvature efficiently in few parameters, and makes the association of individual leaves in feature space possible. The approach combines 3D contour extraction and further compression using Principal Component Analysis (PCA) to produce a shape space encoding, which is entirely learned from data and retains information about edge contours and 3D curvature. Our evaluation on temporal scan sequences of tomato plants shows, that incorporating shape features improves temporal leaf-matching. A combination of shape, location, and rotation information proves most informative for recognition of leaves over time and yields a true positive rate of 75%, a 15% improvement on sate-of-the-art methods. This is essential for robotic crop monitoring, which enables whole-of-lifecycle phenotyping.
Path Guiding Using Spatio-Directional Mixture Models
Nov 25, 2021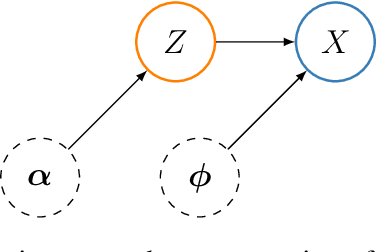
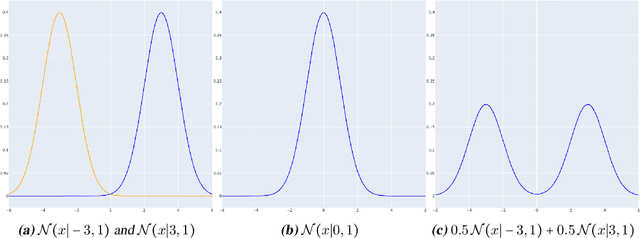
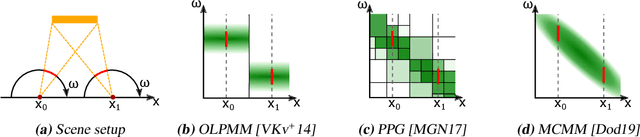
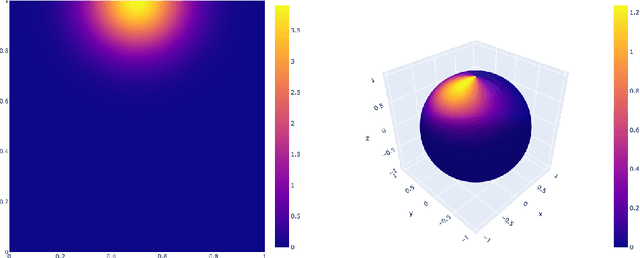
We propose a learning-based method for light-path construction in path tracing algorithms, which iteratively optimizes and samples from what we refer to as spatio-directional Gaussian mixture models (SDMMs). In particular, we approximate incident radiance as an online-trained $5$D mixture that is accelerated by a $k$D-tree. Using the same framework, we approximate BSDFs as pre-trained $n$D mixtures, where $n$ is the number of BSDF parameters. Such an approach addresses two major challenges in path-guiding models. First, the $5$D radiance representation naturally captures correlation between the spatial and directional dimensions. Such correlations are present in e.g.\ parallax and caustics. Second, by using a tangent-space parameterization of Gaussians, our spatio-directional mixtures can perform approximate product sampling with arbitrarily oriented BSDFs. Existing models are only able to do this by either foregoing anisotropy of the mixture components or by representing the radiance field in local (normal aligned) coordinates, which both make the radiance field more difficult to learn. An additional benefit of the tangent-space parameterization is that each individual Gaussian is mapped to the solid sphere with low distortion near its center of mass. Our method performs especially well on scenes with small, localized luminaires that induce high spatio-directional correlation in the incident radiance.