 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Diversity in Image Generation via Attribute-Conditional Human Evaluation
Nov 13, 2025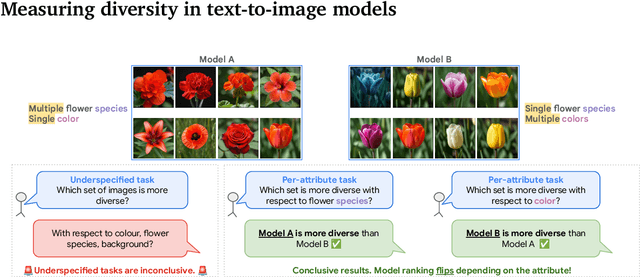


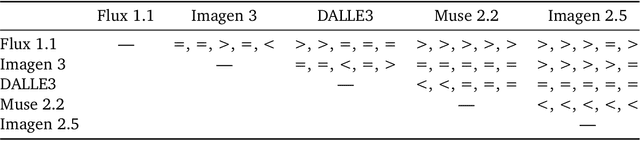
Despite advances in generation quality, current text-to-image (T2I) models often lack diversity, generating homogeneous outputs. This work introduces a framework to address the need for robust diversity evaluation in T2I models. Our framework systematically assesses diversity by evaluating individual concepts and their relevant factors of variation. Key contributions include: (1) a novel human evaluation template for nuanced diversity assessment; (2) a curated prompt set covering diverse concepts with their identified factors of variation (e.g. prompt: An image of an apple, factor of variation: color); and (3) a methodology for comparing models in terms of human annotations via binomial tests. Furthermore, we rigorously compare various image embeddings for diversity measurement. Notably, our principled approach enables ranking of T2I models by diversity, identifying categories where they particularly struggle. This research offers a robust methodology and insights, paving the way for improvements in T2I model diversity and metric development.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Blue noise for diffusion models
Feb 07, 2024



Most of the existing diffusion models use Gaussian noise for training and sampling across all time steps, which may not optimally account for the frequency contents reconstructed by the denoising network. Despite the diverse applications of correlated noise in computer graphics, its potential for improving the training process has been underexplored. In this paper, we introduce a novel and general class of diffusion models taking correlated noise within and across images into account. More specifically, we propose a time-varying noise model to incorporate correlated noise into the training process, as well as a method for fast generation of correlated noise mask. Our model is built upon deterministic diffusion models and utilizes blue noise to help improve the generation quality compared to using Gaussian white (random) noise only. Further, our framework allows introducing correlation across images within a single mini-batch to improve gradient flow. We perform both qualitative and quantitative evaluations on a variety of datasets using our method, achieving improvements on different tasks over existing deterministic diffusion models in terms of FID metric.
Scaling Vision Transformers to 22 Billion Parameters
Feb 10, 2023



The scaling of Transformers has driven breakthrough capabilities for language models. At present, the largest large language models (LLMs) contain upwards of 100B parameters. Vision Transformers (ViT) have introduced the same architecture to image and video modelling, but these have not yet been successfully scaled to nearly the same degree; the largest dense ViT contains 4B parameters (Chen et al., 2022). We present a recipe for highly efficient and stable training of a 22B-parameter ViT (ViT-22B) and perform a wide variety of experiments on the resulting model. When evaluated on downstream tasks (often with a lightweight linear model on frozen features), ViT-22B demonstrates increasing performance with scale. We further observe other interesting benefits of scale, including an improved tradeoff between fairness and performance, state-of-the-art alignment to human visual perception in terms of shape/texture bias, and improved robustness. ViT-22B demonstrates the potential for "LLM-like" scaling in vision, and provides key steps towards getting there.
CUF: Continuous Upsampling Filters
Oct 20, 2022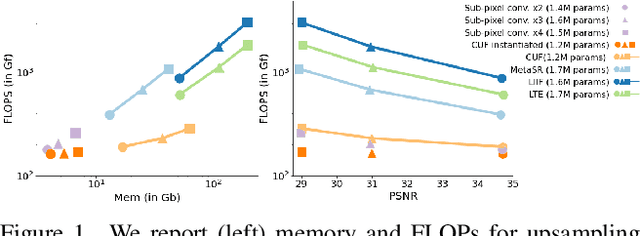


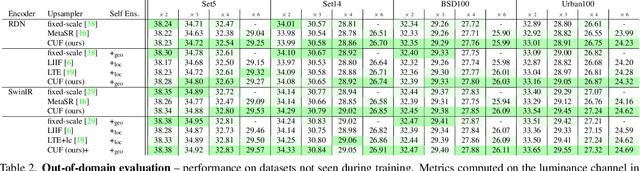
Neural fields have rapidly been adopted for representing 3D signals, but their application to more classical 2D image-processing has been relatively limited. In this paper, we consider one of the most important operations in image processing: upsampling. In deep learning, learnable upsampling layers have extensively been used for single image super-resolution. We propose to parameterize upsampling kernels as neural fields. This parameterization leads to a compact architecture that obtains a 40-fold reduction in the number of parameters when compared with competing arbitrary-scale super-resolution architectures. When upsampling images of size 256x256 we show that our architecture is 2x-10x more efficient than competing arbitrary-scale super-resolution architectures, and more efficient than sub-pixel convolutions when instantiated to a single-scale model. In the general setting, these gains grow polynomially with the square of the target scale. We validate our method on standard benchmarks showing such efficiency gains can be achieved without sacrifices in super-resolution performance.
Proper Reuse of Image Classification Features Improves Object Detection
Apr 01, 2022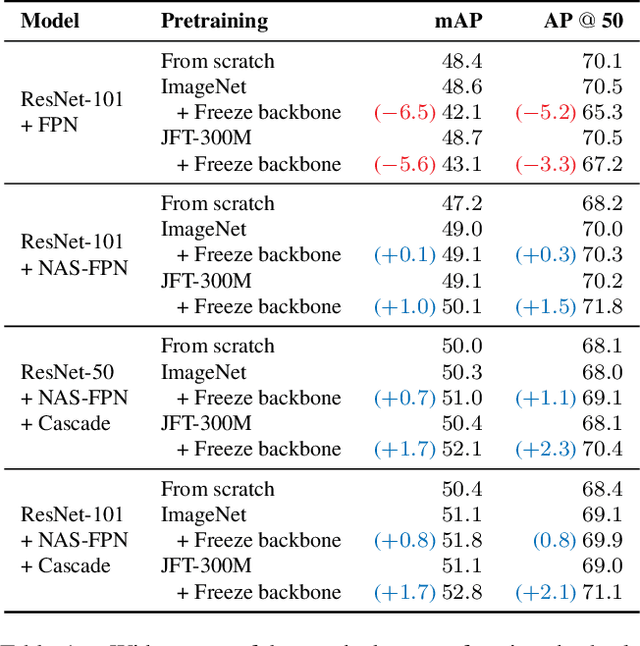
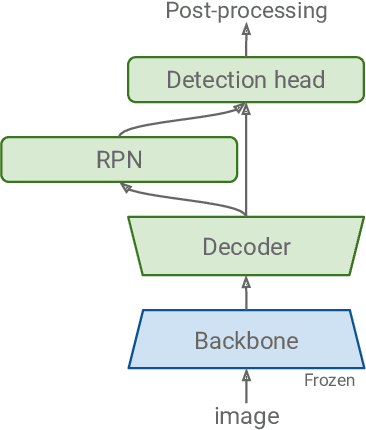
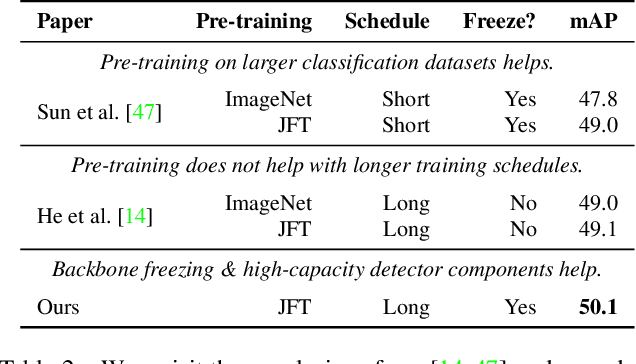

A common practice in transfer learning is to initialize the downstream model weights by pre-training on a data-abundant upstream task. In object detection specifically, the feature backbone is typically initialized with Imagenet classifier weights and fine-tuned on the object detection task. Recent works show this is not strictly necessary under longer training regimes and provide recipes for training the backbone from scratch. We investigate the opposite direction of this end-to-end training trend: we show that an extreme form of knowledge preservation -- freezing the classifier-initialized backbone -- consistently improves many different detection models, and leads to considerable resource savings. We hypothesize and corroborate experimentally that the remaining detector components capacity and structure is a crucial factor in leveraging the frozen backbone. Immediate applications of our findings include performance improvements on hard cases like detection of long-tail object classes and computational and memory resource savings that contribute to making the field more accessible to researchers with access to fewer computational resources.
Impact of Aliasing on Generalization in Deep Convolutional Networks
Aug 07, 2021

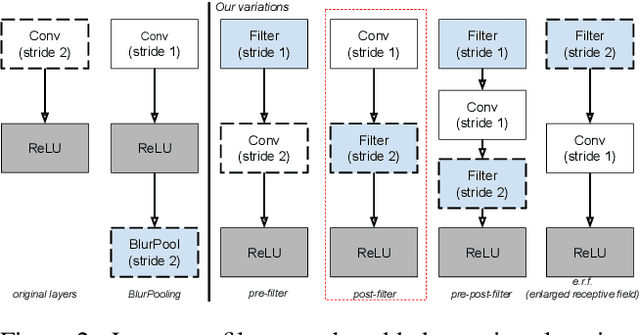
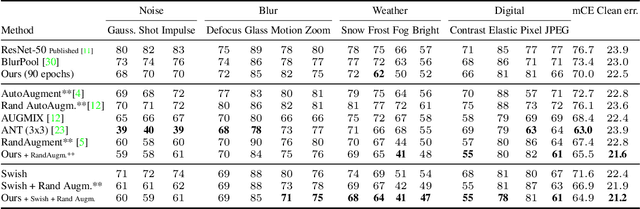
We investigate the impact of aliasing on generalization in Deep Convolutional Networks and show that data augmentation schemes alone are unable to prevent it due to structural limitations in widely used architectures. Drawing insights from frequency analysis theory, we take a closer look at ResNet and EfficientNet architectures and review the trade-off between aliasing and information loss in each of their major components. We show how to mitigate aliasing by inserting non-trainable low-pass filters at key locations, particularly where networks lack the capacity to learn them. These simple architectural changes lead to substantial improvements in generalization on i.i.d. and even more on out-of-distribution conditions, such as image classification under natural corruptions on ImageNet-C [11] and few-shot learning on Meta-Dataset [26]. State-of-the art results are achieved on both datasets without introducing additional trainable parameters and using the default hyper-parameters of open source codebases.
Bridging the Gap Between Adversarial Robustness and Optimization Bias
Feb 17, 2021
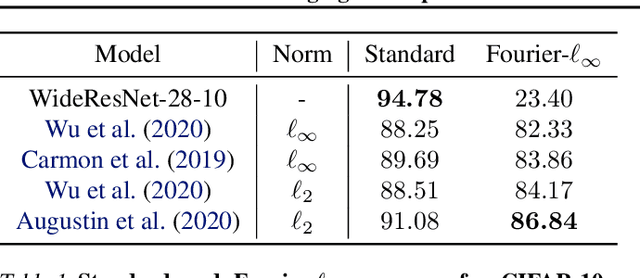
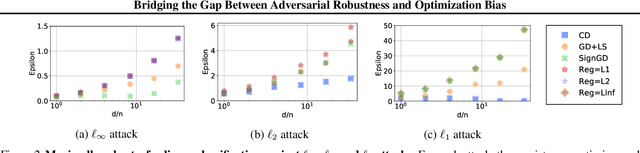

Adversarial robustness is an open challenge in deep learning, most often tackled using adversarial training. Adversarial training is computationally costly, involving alternated optimization with a trade-off between standard generalization and adversarial robustness. We explore training robust models without adversarial training by revisiting a known result linking maximally robust classifiers and minimum norm solutions, and combining it with recent results on the implicit bias of optimizers. First, we show that, under certain conditions, it is possible to achieve both perfect standard accuracy and a certain degree of robustness without a trade-off, simply by training an overparameterized model using the implicit bias of the optimization. In that regime, there is a direct relationship between the type of the optimizer and the attack to which the model is robust. Second, we investigate the role of the architecture in designing robust models. In particular, we characterize the robustness of linear convolutional models, showing that they resist attacks subject to a constraint on the Fourier-$\ell_\infty$ norm. This result explains the property of $\ell_p$-bounded adversarial perturbations that tend to be concentrated in the Fourier domain. This leads us to a novel attack in the Fourier domain that is inspired by the well-known frequency-dependent sensitivity of human perception. We evaluate Fourier-$\ell_\infty$ robustness of recent CIFAR-10 models with robust training and visualize adversarial perturbations.
An Effective Anti-Aliasing Approach for Residual Networks
Nov 20, 2020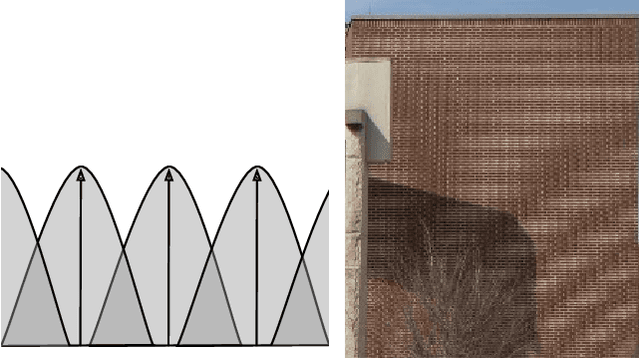

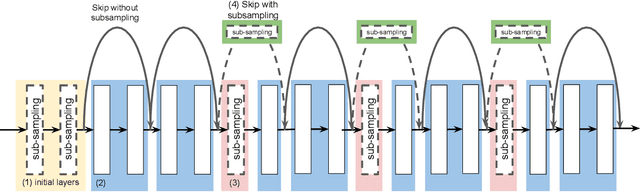

Image pre-processing in the frequency domain has traditionally played a vital role in computer vision and was even part of the standard pipeline in the early days of deep learning. However, with the advent of large datasets, many practitioners concluded that this was unnecessary due to the belief that these priors can be learned from the data itself. Frequency aliasing is a phenomenon that may occur when sub-sampling any signal, such as an image or feature map, causing distortion in the sub-sampled output. We show that we can mitigate this effect by placing non-trainable blur filters and using smooth activation functions at key locations, particularly where networks lack the capacity to learn them. These simple architectural changes lead to substantial improvements in out-of-distribution generalization on both image classification under natural corruptions on ImageNet-C [10] and few-shot learning on Meta-Dataset [17], without introducing additional trainable parameters and using the default hyper-parameters of open source codebases.
Data Augmentation for Skin Lesion Analysis
Sep 05, 2018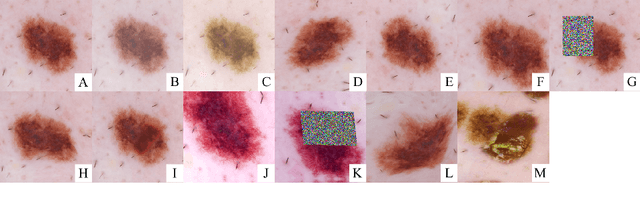


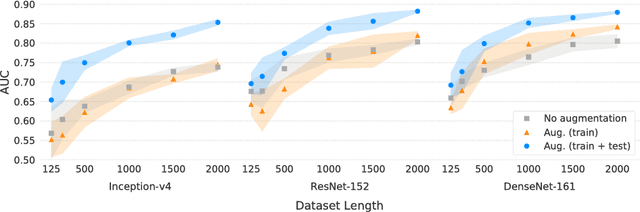
Deep learning models show remarkable results in automated skin lesion analysis. However, these models demand considerable amounts of data, while the availability of annotated skin lesion images is often limited. Data augmentation can expand the training dataset by transforming input images. In this work, we investigate the impact of 13 data augmentation scenarios for melanoma classification trained on three CNNs (Inception-v4, ResNet, and DenseNet). Scenarios include traditional color and geometric transforms, and more unusual augmentations such as elastic transforms, random erasing and a novel augmentation that mixes different lesions. We also explore the use of data augmentation at test-time and the impact of data augmentation on various dataset sizes. Our results confirm the importance of data augmentation in both training and testing and show that it can lead to more performance gains than obtaining new images. The best scenario results in an AUC of 0.882 for melanoma classification without using external data, outperforming the top-ranked submission (0.874) for the ISIC Challenge 2017, which was trained with additional data.