 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootOOD: Self-Supervised Out-of-Distribution Detection via Synthetic Sample Exposure under Neural Collapse
Nov 17, 2025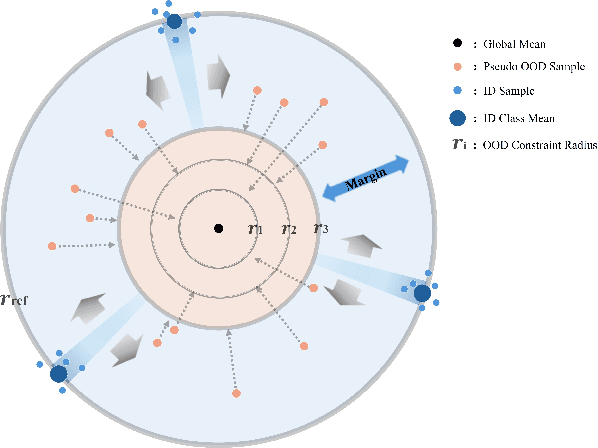
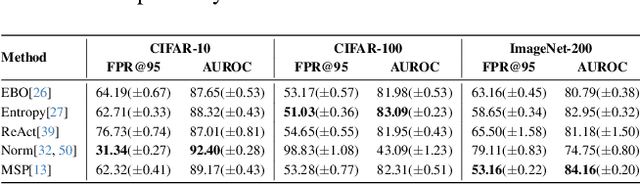
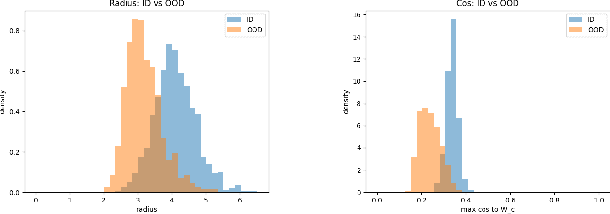
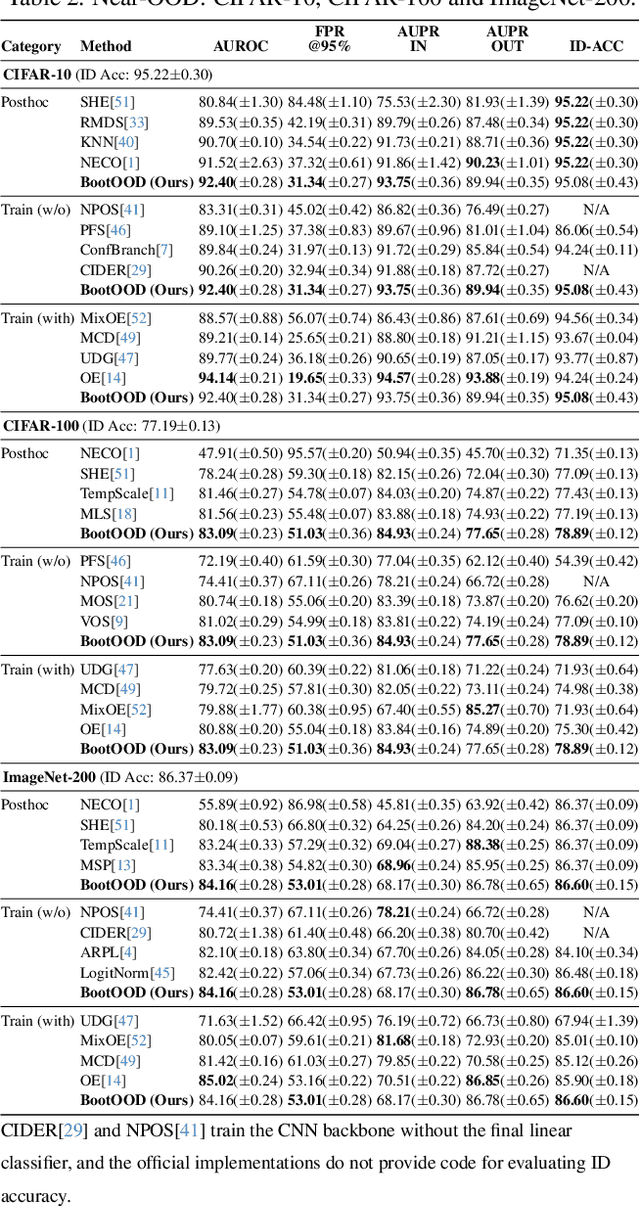
Out-of-distribution (OOD) detection is critical for deploying image classifiers in safety-sensitive environments, yet existing detectors often struggle when OOD samples are semantically similar to the in-distribution (ID) classes. We present BootOOD, a fully self-supervised OOD detection framework that bootstraps exclusively from ID data and is explicitly designed to handle semantically challenging OOD samples. BootOOD synthesizes pseudo-OOD features through simple transformations of ID representations and leverages Neural Collapse (NC), where ID features cluster tightly around class means with consistent feature norms. Unlike prior approaches that aim to constrain OOD features into subspaces orthogonal to the collapsed ID means, BootOOD introduces a lightweight auxiliary head that performs radius-based classification on feature norms. This design decouples OOD detection from the primary classifier and imposes a relaxed requirement: OOD samples are learned to have smaller feature norms than ID features, which is easier to satisfy when ID and OOD are semantically close. Experiments on CIFAR-10, CIFAR-100, and ImageNet-200 show that BootOOD outperforms prior post-hoc methods, surpasses training-based methods without outlier exposure, and is competitive with state-of-the-art outlier-exposure approaches while maintaining or improving ID accuracy.
VaViM and VaVAM: Autonomous Driving through Video Generative Modeling
Feb 21, 2025We explore the potential of large-scale generative video models for autonomous driving, introducing an open-source auto-regressive video model (VaViM) and its companion video-action model (VaVAM) to investigate how video pre-training transfers to real-world driving. VaViM is a simple auto-regressive video model that predicts frames using spatio-temporal token sequences. We show that it captures the semantics and dynamics of driving scenes. VaVAM, the video-action model, leverages the learned representations of VaViM to generate driving trajectories through imitation learning. Together, the models form a complete perception-to-action pipeline. We evaluate our models in open- and closed-loop driving scenarios, revealing that video-based pre-training holds promise for autonomous driving. Key insights include the semantic richness of the learned representations, the benefits of scaling for video synthesis, and the complex relationship between model size, data, and safety metrics in closed-loop evaluations. We release code and model weights at https://github.com/valeoai/VideoActionModel
GIFT: A Framework for Global Interpretable Faithful Textual Explanations of Vision Classifiers
Nov 23, 2024



Understanding deep models is crucial for deploying them in safety-critical applications. We introduce GIFT, a framework for deriving post-hoc, global, interpretable, and faithful textual explanations for vision classifiers. GIFT starts from local faithful visual counterfactual explanations and employs (vision) language models to translate those into global textual explanations. Crucially, GIFT provides a verification stage measuring the causal effect of the proposed explanations on the classifier decision. Through experiments across diverse datasets, including CLEVR, CelebA, and BDD, we demonstrate that GIFT effectively reveals meaningful insights, uncovering tasks, concepts, and biases used by deep vision classifiers. Our code, data, and models are released at https://github.com/valeoai/GIFT.
PAFUSE: Part-based Diffusion for 3D Whole-Body Pose Estimation
Jul 14, 2024We introduce a novel approach for 3D whole-body pose estimation, addressing the challenge of scale- and deformability- variance across body parts brought by the challenge of extending the 17 major joints on the human body to fine-grained keypoints on the face and hands. In addition to addressing the challenge of exploiting motion in unevenly sampled data, we combine stable diffusion to a hierarchical part representation which predicts the relative locations of fine-grained keypoints within each part (e.g., face) with respect to the part's local reference frame. On the H3WB dataset, our method greatly outperforms the current state of the art, which fails to exploit the temporal information. We also show considerable improvements compared to other spatiotemporal 3D human-pose estimation approaches that fail to account for the body part specificities. Code is available at https://github.com/valeoai/PAFUSE.
Valeo4Cast: A Modular Approach to End-to-End Forecasting
Jun 12, 2024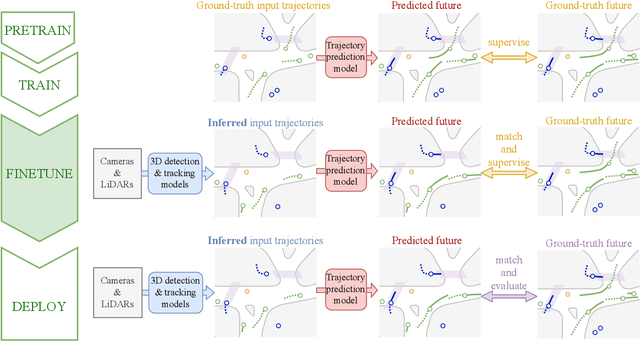
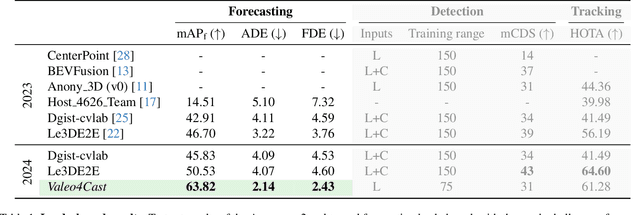
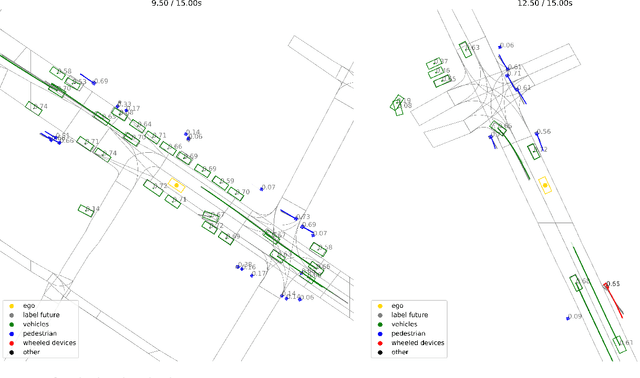
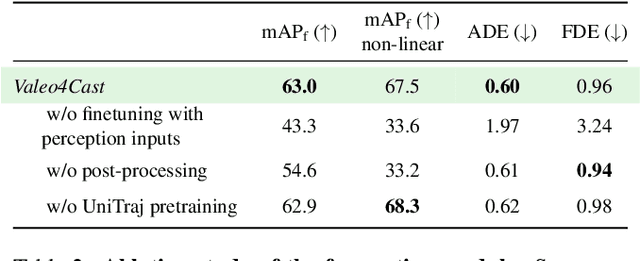
Motion forecasting is crucial in autonomous driving systems to anticipate the future trajectories of surrounding agents such as pedestrians, vehicles, and traffic signals. In end-to-end forecasting, the model must jointly detect from sensor data (cameras or LiDARs) the position and past trajectories of the different elements of the scene and predict their future location. We depart from the current trend of tackling this task via end-to-end training from perception to forecasting and we use a modular approach instead. Following a recent study, we individually build and train detection, tracking, and forecasting modules. We then only use consecutive finetuning steps to integrate the modules better and alleviate compounding errors. Our study reveals that this simple yet effective approach significantly improves performance on the end-to-end forecasting benchmark. Consequently, our solution ranks first in the Argoverse 2 end-to-end Forecasting Challenge held at CVPR 2024 Workshop on Autonomous Driving (WAD), with 63.82 mAPf. We surpass forecasting results by +17.1 points over last year's winner and by +13.3 points over this year's runner-up. This remarkable performance in forecasting can be explained by our modular paradigm, which integrates finetuning strategies and significantly outperforms the end-to-end-trained counterparts.
Back to the Basics on Predicting Transfer Performance
May 30, 2024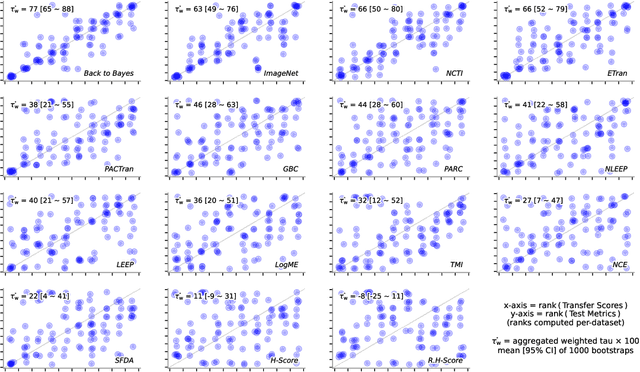
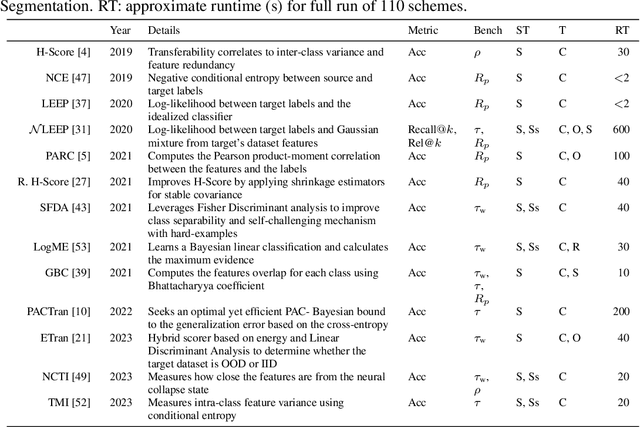
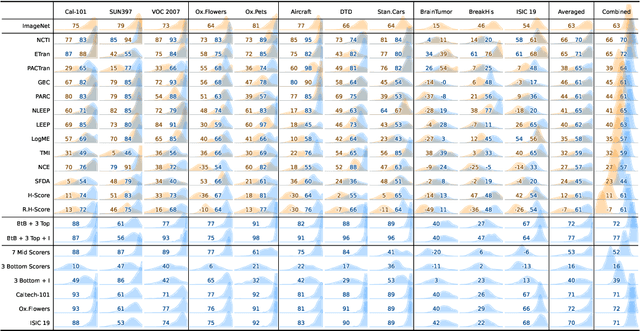
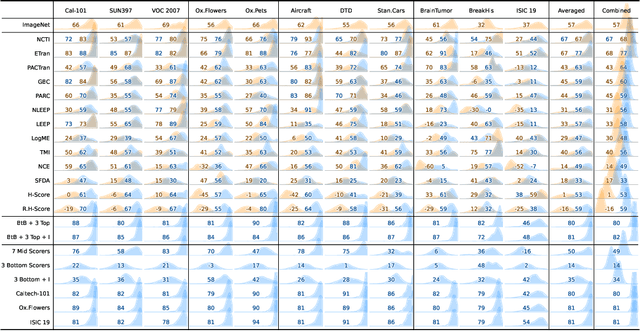
In the evolving landscape of deep learning, selecting the best pre-trained models from a growing number of choices is a challenge. Transferability scorers propose alleviating this scenario, but their recent proliferation, ironically, poses the challenge of their own assessment. In this work, we propose both robust benchmark guidelines for transferability scorers, and a well-founded technique to combine multiple scorers, which we show consistently improves their results. We extensively evaluate 13 scorers from literature across 11 datasets, comprising generalist, fine-grained, and medical imaging datasets. We show that few scorers match the predictive performance of the simple raw metric of models on ImageNet, and that all predictors suffer on medical datasets. Our results highlight the potential of combining different information sources for reliably predicting transferability across varied domains.
ManiPose: Manifold-Constrained Multi-Hypothesis 3D Human Pose Estimation
Dec 11, 2023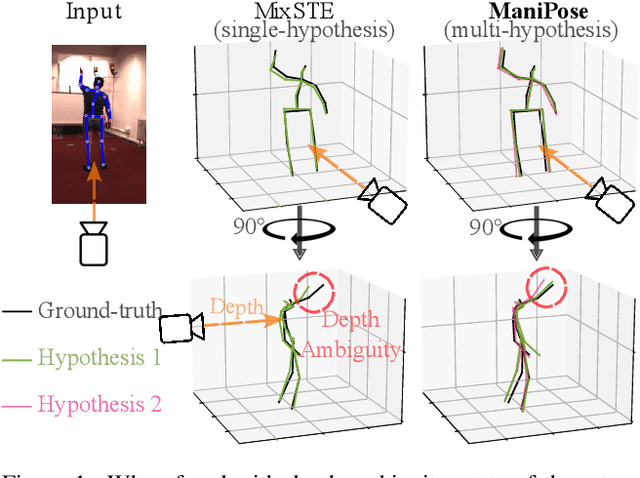
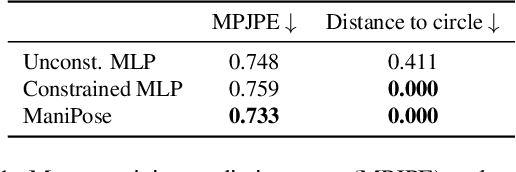
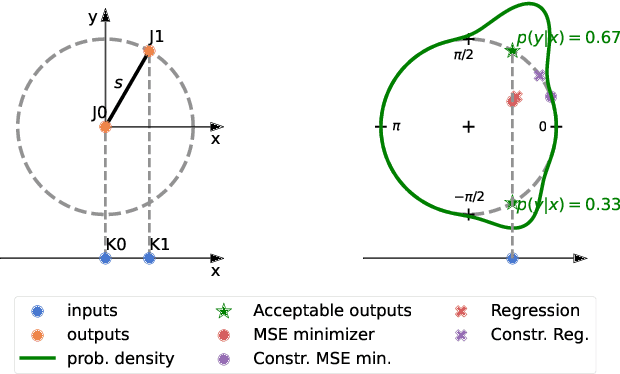
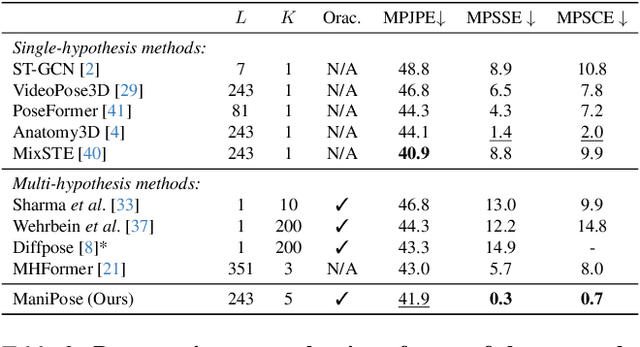
Monocular 3D human pose estimation (3D-HPE) is an inherently ambiguous task, as a 2D pose in an image might originate from different possible 3D poses. Yet, most 3D-HPE methods rely on regression models, which assume a one-to-one mapping between inputs and outputs. In this work, we provide theoretical and empirical evidence that, because of this ambiguity, common regression models are bound to predict topologically inconsistent poses, and that traditional evaluation metrics, such as the MPJPE, P-MPJPE and PCK, are insufficient to assess this aspect. As a solution, we propose ManiPose, a novel manifold-constrained multi-hypothesis model capable of proposing multiple candidate 3D poses for each 2D input, together with their corresponding plausibility. Unlike previous multi-hypothesis approaches, our solution is completely supervised and does not rely on complex generative models, thus greatly facilitating its training and usage. Furthermore, by constraining our model to lie within the human pose manifold, we can guarantee the consistency of all hypothetical poses predicted with our approach, which was not possible in previous works. We illustrate the usefulness of ManiPose in a synthetic 1D-to-2D lifting setting and demonstrate on real-world datasets that it outperforms state-of-the-art models in pose consistency by a large margin, while still reaching competitive MPJPE performance.
DiffHPE: Robust, Coherent 3D Human Pose Lifting with Diffusion
Sep 04, 2023



We present an innovative approach to 3D Human Pose Estimation (3D-HPE) by integrating cutting-edge diffusion models, which have revolutionized diverse fields, but are relatively unexplored in 3D-HPE. We show that diffusion models enhance the accuracy, robustness, and coherence of human pose estimations. We introduce DiffHPE, a novel strategy for harnessing diffusion models in 3D-HPE, and demonstrate its ability to refine standard supervised 3D-HPE. We also show how diffusion models lead to more robust estimations in the face of occlusions, and improve the time-coherence and the sagittal symmetry of predictions. Using the Human\,3.6M dataset, we illustrate the effectiveness of our approach and its superiority over existing models, even under adverse situations where the occlusion patterns in training do not match those in inference. Our findings indicate that while standalone diffusion models provide commendable performance, their accuracy is even better in combination with supervised models, opening exciting new avenues for 3D-HPE research.
The Performance of Transferability Metrics does not Translate to Medical Tasks
Aug 14, 2023


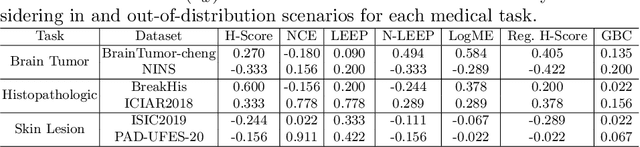
Transfer learning boosts the performance of medical image analysis by enabling deep learning (DL) on small datasets through the knowledge acquired from large ones. As the number of DL architectures explodes, exhaustively attempting all candidates becomes unfeasible, motivating cheaper alternatives for choosing them. Transferability scoring methods emerge as an enticing solution, allowing to efficiently calculate a score that correlates with the architecture accuracy on any target dataset. However, since transferability scores have not been evaluated on medical datasets, their use in this context remains uncertain, preventing them from benefiting practitioners. We fill that gap in this work, thoroughly evaluating seven transferability scores in three medical applications, including out-of-distribution scenarios. Despite promising results in general-purpose datasets, our results show that no transferability score can reliably and consistently estimate target performance in medical contexts, inviting further work in that direction.
Test-Time Selection for Robust Skin Lesion Analysis
Aug 10, 2023Skin lesion analysis models are biased by artifacts placed during image acquisition, which influence model predictions despite carrying no clinical information. Solutions that address this problem by regularizing models to prevent learning those spurious features achieve only partial success, and existing test-time debiasing techniques are inappropriate for skin lesion analysis due to either making unrealistic assumptions on the distribution of test data or requiring laborious annotation from medical practitioners. We propose TTS (Test-Time Selection), a human-in-the-loop method that leverages positive (e.g., lesion area) and negative (e.g., artifacts) keypoints in test samples. TTS effectively steers models away from exploiting spurious artifact-related correlations without retraining, and with less annotation requirements. Our solution is robust to a varying availability of annotations, and different levels of bias. We showcase on the ISIC2019 dataset (for which we release a subset of annotated images) how our model could be deployed in the real-world for mitigating bias.