 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRIV-EX: Counterfactual Explanations for Driving LLMs
Feb 28, 2026Large language models (LLMs) are increasingly used as reasoning engines in autonomous driving, yet their decision-making remains opaque. We propose to study their decision process through counterfactual explanations, which identify the minimal semantic changes to a scene description required to alter a driving plan. We introduce DRIV-EX, a method that leverages gradient-based optimization on continuous embeddings to identify the input shifts required to flip the model's decision. Crucially, to avoid the incoherent text typical of unconstrained continuous optimization, DRIV-EX uses these optimized embeddings solely as a semantic guide: they are used to bias a controlled decoding process that re-generates the original scene description. This approach effectively steers the generation toward the counterfactual target while guaranteeing the linguistic fluency, domain validity, and proximity to the original input, essential for interpretability. Evaluated using the LC-LLM planner on a textual transcription of the highD dataset, DRIV-EX generates valid, fluent counterfactuals more reliably than existing baselines. It successfully exposes latent biases and provides concrete insights to improve the robustness of LLM-based driving agents.
GIFT: A Framework for Global Interpretable Faithful Textual Explanations of Vision Classifiers
Nov 23, 2024



Understanding deep models is crucial for deploying them in safety-critical applications. We introduce GIFT, a framework for deriving post-hoc, global, interpretable, and faithful textual explanations for vision classifiers. GIFT starts from local faithful visual counterfactual explanations and employs (vision) language models to translate those into global textual explanations. Crucially, GIFT provides a verification stage measuring the causal effect of the proposed explanations on the classifier decision. Through experiments across diverse datasets, including CLEVR, CelebA, and BDD, we demonstrate that GIFT effectively reveals meaningful insights, uncovering tasks, concepts, and biases used by deep vision classifiers. Our code, data, and models are released at https://github.com/valeoai/GIFT.
LLM-wrapper: Black-Box Semantic-Aware Adaptation of Vision-Language Foundation Models
Sep 18, 2024
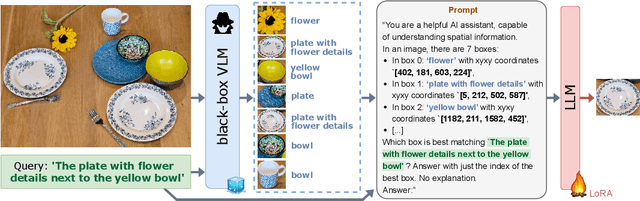
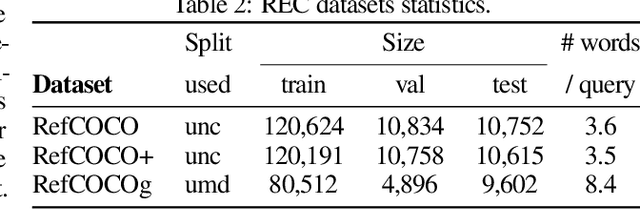
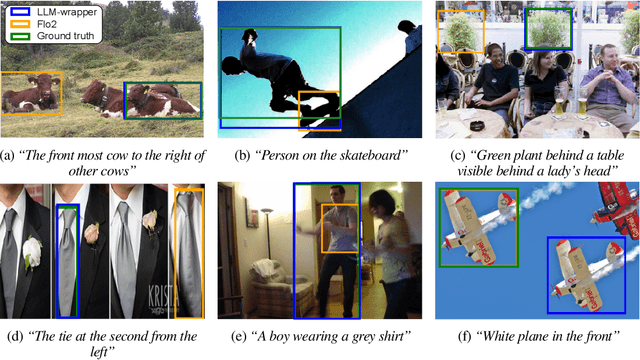
Vision Language Models (VLMs) have shown impressive performances on numerous tasks but their zero-shot capabilities can be limited compared to dedicated or fine-tuned models. Yet, fine-tuning VLMs comes with limitations as it requires `white-box' access to the model's architecture and weights as well as expertise to design the fine-tuning objectives and optimize the hyper-parameters, which are specific to each VLM and downstream task. In this work, we propose LLM-wrapper, a novel approach to adapt VLMs in a `black-box' manner by leveraging large language models (LLMs) so as to reason on their outputs. We demonstrate the effectiveness of LLM-wrapper on Referring Expression Comprehension (REC), a challenging open-vocabulary task that requires spatial and semantic reasoning. Our approach significantly boosts the performance of off-the-shelf models, resulting in competitive results when compared with classic fine-tuning.
A Study of Test-time Contrastive Concepts for Open-world, Open-vocabulary Semantic Segmentation
Jul 06, 2024



Recent VLMs, pre-trained on large amounts of image-text pairs to align both modalities, have opened the way to open-vocabulary semantic segmentation. Given an arbitrary set of textual queries, image regions are assigned the closest query in feature space. However, the usual setup expects the user to list all possible visual concepts that may occur in the image, typically all classes of benchmark datasets, that act as negatives to each other. We consider here the more challenging scenario of segmenting a single concept, given a textual prompt and nothing else. To achieve good results, besides contrasting with the generic 'background' text, we study different ways to generate query-specific test-time contrastive textual concepts, which leverage either the distribution of text in the VLM's training set or crafted LLM prompts. We show the relevance of our approach using a new, specific metric.