 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting [CLS] and Patch Token Interaction in Vision Transformers
Feb 09, 2026Vision Transformers have emerged as powerful, scalable and versatile representation learners. To capture both global and local features, a learnable [CLS] class token is typically prepended to the input sequence of patch tokens. Despite their distinct nature, both token types are processed identically throughout the model. In this work, we investigate the friction between global and local feature learning under different pre-training strategies by analyzing the interactions between class and patch tokens. Our analysis reveals that standard normalization layers introduce an implicit differentiation between these token types. Building on this insight, we propose specialized processing paths that selectively disentangle the computational flow of class and patch tokens, particularly within normalization layers and early query-key-value projections. This targeted specialization leads to significantly improved patch representation quality for dense prediction tasks. Our experiments demonstrate segmentation performance gains of over 2 mIoU points on standard benchmarks, while maintaining strong classification accuracy. The proposed modifications introduce only an 8% increase in parameters, with no additional computational overhead. Through comprehensive ablations, we provide insights into which architectural components benefit most from specialization and how our approach generalizes across model scales and learning frameworks.
DINOv3
Aug 13, 2025Self-supervised learning holds the promise of eliminating the need for manual data annotation, enabling models to scale effortlessly to massive datasets and larger architectures. By not being tailored to specific tasks or domains, this training paradigm has the potential to learn visual representations from diverse sources, ranging from natural to aerial images -- using a single algorithm. This technical report introduces DINOv3, a major milestone toward realizing this vision by leveraging simple yet effective strategies. First, we leverage the benefit of scaling both dataset and model size by careful data preparation, design, and optimization. Second, we introduce a new method called Gram anchoring, which effectively addresses the known yet unsolved issue of dense feature maps degrading during long training schedules. Finally, we apply post-hoc strategies that further enhance our models' flexibility with respect to resolution, model size, and alignment with text. As a result, we present a versatile vision foundation model that outperforms the specialized state of the art across a broad range of settings, without fine-tuning. DINOv3 produces high-quality dense features that achieve outstanding performance on various vision tasks, significantly surpassing previous self- and weakly-supervised foundation models. We also share the DINOv3 suite of vision models, designed to advance the state of the art on a wide spectrum of tasks and data by providing scalable solutions for diverse resource constraints and deployment scenarios.
DINOv2 Meets Text: A Unified Framework for Image- and Pixel-Level Vision-Language Alignment
Dec 20, 2024



Self-supervised visual foundation models produce powerful embeddings that achieve remarkable performance on a wide range of downstream tasks. However, unlike vision-language models such as CLIP, self-supervised visual features are not readily aligned with language, hindering their adoption in open-vocabulary tasks. Our method, named dino.txt, unlocks this new ability for DINOv2, a widely used self-supervised visual encoder. We build upon the LiT training strategy, which trains a text encoder to align with a frozen vision model but leads to unsatisfactory results on dense tasks. We propose several key ingredients to improve performance on both global and dense tasks, such as concatenating the [CLS] token with the patch average to train the alignment and curating data using both text and image modalities. With these, we successfully train a CLIP-like model with only a fraction of the computational cost compared to CLIP while achieving state-of-the-art results in zero-shot classification and open-vocabulary semantic segmentation.
LLM-wrapper: Black-Box Semantic-Aware Adaptation of Vision-Language Foundation Models
Sep 18, 2024
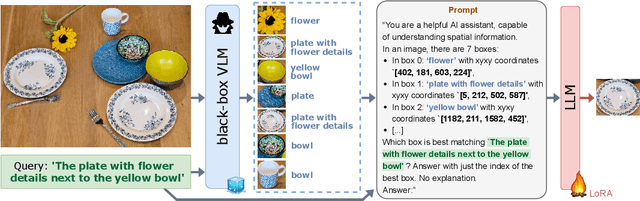
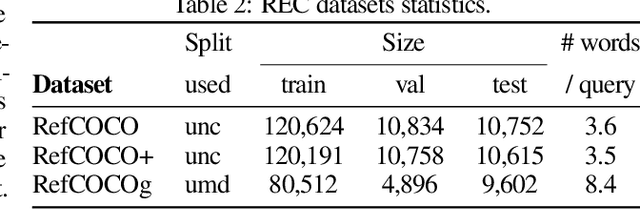
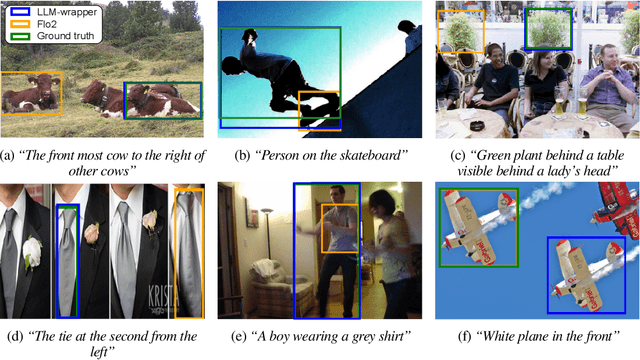
Vision Language Models (VLMs) have shown impressive performances on numerous tasks but their zero-shot capabilities can be limited compared to dedicated or fine-tuned models. Yet, fine-tuning VLMs comes with limitations as it requires `white-box' access to the model's architecture and weights as well as expertise to design the fine-tuning objectives and optimize the hyper-parameters, which are specific to each VLM and downstream task. In this work, we propose LLM-wrapper, a novel approach to adapt VLMs in a `black-box' manner by leveraging large language models (LLMs) so as to reason on their outputs. We demonstrate the effectiveness of LLM-wrapper on Referring Expression Comprehension (REC), a challenging open-vocabulary task that requires spatial and semantic reasoning. Our approach significantly boosts the performance of off-the-shelf models, resulting in competitive results when compared with classic fine-tuning.
MILAN: Milli-Annotations for Lidar Semantic Segmentation
Jul 22, 2024



Annotating lidar point clouds for autonomous driving is a notoriously expensive and time-consuming task. In this work, we show that the quality of recent self-supervised lidar scan representations allows a great reduction of the annotation cost. Our method has two main steps. First, we show that self-supervised representations allow a simple and direct selection of highly informative lidar scans to annotate: training a network on these selected scans leads to much better results than a random selection of scans and, more interestingly, to results on par with selections made by SOTA active learning methods. In a second step, we leverage the same self-supervised representations to cluster points in our selected scans. Asking the annotator to classify each cluster, with a single click per cluster, then permits us to close the gap with fully-annotated training sets, while only requiring one thousandth of the point labels.
A Study of Test-time Contrastive Concepts for Open-world, Open-vocabulary Semantic Segmentation
Jul 06, 2024



Recent VLMs, pre-trained on large amounts of image-text pairs to align both modalities, have opened the way to open-vocabulary semantic segmentation. Given an arbitrary set of textual queries, image regions are assigned the closest query in feature space. However, the usual setup expects the user to list all possible visual concepts that may occur in the image, typically all classes of benchmark datasets, that act as negatives to each other. We consider here the more challenging scenario of segmenting a single concept, given a textual prompt and nothing else. To achieve good results, besides contrasting with the generic 'background' text, we study different ways to generate query-specific test-time contrastive textual concepts, which leverage either the distribution of text in the VLM's training set or crafted LLM prompts. We show the relevance of our approach using a new, specific metric.
Valeo4Cast: A Modular Approach to End-to-End Forecasting
Jun 12, 2024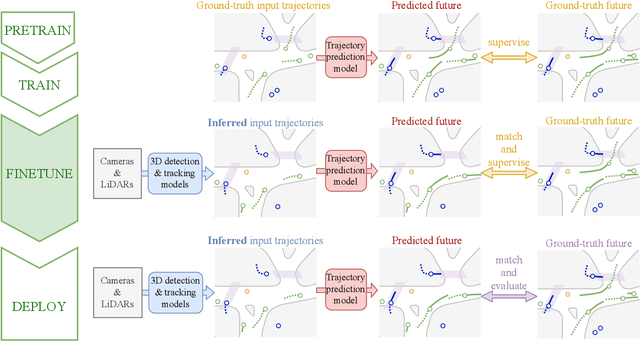
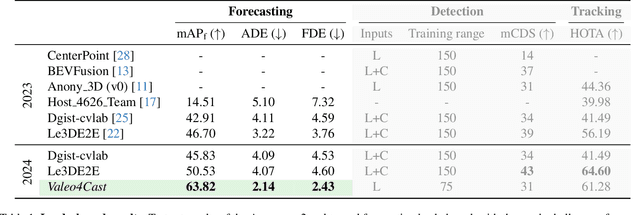
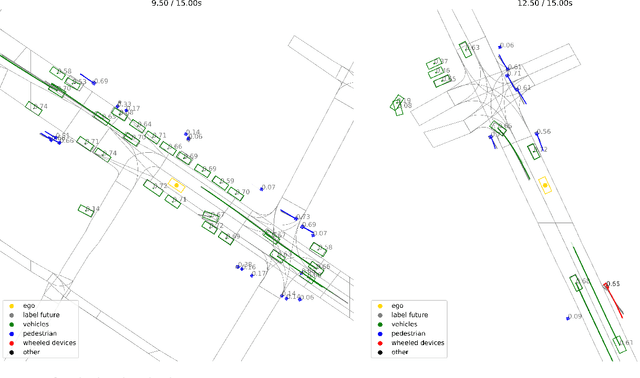
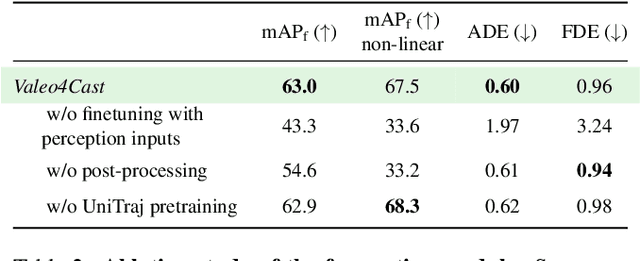
Motion forecasting is crucial in autonomous driving systems to anticipate the future trajectories of surrounding agents such as pedestrians, vehicles, and traffic signals. In end-to-end forecasting, the model must jointly detect from sensor data (cameras or LiDARs) the position and past trajectories of the different elements of the scene and predict their future location. We depart from the current trend of tackling this task via end-to-end training from perception to forecasting and we use a modular approach instead. Following a recent study, we individually build and train detection, tracking, and forecasting modules. We then only use consecutive finetuning steps to integrate the modules better and alleviate compounding errors. Our study reveals that this simple yet effective approach significantly improves performance on the end-to-end forecasting benchmark. Consequently, our solution ranks first in the Argoverse 2 end-to-end Forecasting Challenge held at CVPR 2024 Workshop on Autonomous Driving (WAD), with 63.82 mAPf. We surpass forecasting results by +17.1 points over last year's winner and by +13.3 points over this year's runner-up. This remarkable performance in forecasting can be explained by our modular paradigm, which integrates finetuning strategies and significantly outperforms the end-to-end-trained counterparts.
POP-3D: Open-Vocabulary 3D Occupancy Prediction from Images
Jan 17, 2024



We describe an approach to predict open-vocabulary 3D semantic voxel occupancy map from input 2D images with the objective of enabling 3D grounding, segmentation and retrieval of free-form language queries. This is a challenging problem because of the 2D-3D ambiguity and the open-vocabulary nature of the target tasks, where obtaining annotated training data in 3D is difficult. The contributions of this work are three-fold. First, we design a new model architecture for open-vocabulary 3D semantic occupancy prediction. The architecture consists of a 2D-3D encoder together with occupancy prediction and 3D-language heads. The output is a dense voxel map of 3D grounded language embeddings enabling a range of open-vocabulary tasks. Second, we develop a tri-modal self-supervised learning algorithm that leverages three modalities: (i) images, (ii) language and (iii) LiDAR point clouds, and enables training the proposed architecture using a strong pre-trained vision-language model without the need for any 3D manual language annotations. Finally, we demonstrate quantitatively the strengths of the proposed model on several open-vocabulary tasks: Zero-shot 3D semantic segmentation using existing datasets; 3D grounding and retrieval of free-form language queries, using a small dataset that we propose as an extension of nuScenes. You can find the project page here https://vobecant.github.io/POP3D.
CLIP-DINOiser: Teaching CLIP a few DINO tricks
Dec 19, 2023



The popular CLIP model displays impressive zero-shot capabilities thanks to its seamless interaction with arbitrary text prompts. However, its lack of spatial awareness makes it unsuitable for dense computer vision tasks, e.g., semantic segmentation, without an additional fine-tuning step that often uses annotations and can potentially suppress its original open-vocabulary properties. Meanwhile, self-supervised representation methods have demonstrated good localization properties without human-made annotations nor explicit supervision. In this work, we take the best of both worlds and propose a zero-shot open-vocabulary semantic segmentation method, which does not require any annotations. We propose to locally improve dense MaskCLIP features, computed with a simple modification of CLIP's last pooling layer, by integrating localization priors extracted from self-supervised features. By doing so, we greatly improve the performance of MaskCLIP and produce smooth outputs. Moreover, we show that the used self-supervised feature properties can directly be learnt from CLIP features therefore allowing us to obtain the best results with a single pass through CLIP model. Our method CLIP-DINOiser needs only a single forward pass of CLIP and two light convolutional layers at inference, no extra supervision nor extra memory and reaches state-of-the-art results on challenging and fine-grained benchmarks such as COCO, Pascal Context, Cityscapes and ADE20k. The code to reproduce our results is available at https://github.com/wysoczanska/clip_dinoiser.
Revisiting the Distillation of Image Representations into Point Clouds for Autonomous Driving
Oct 26, 2023
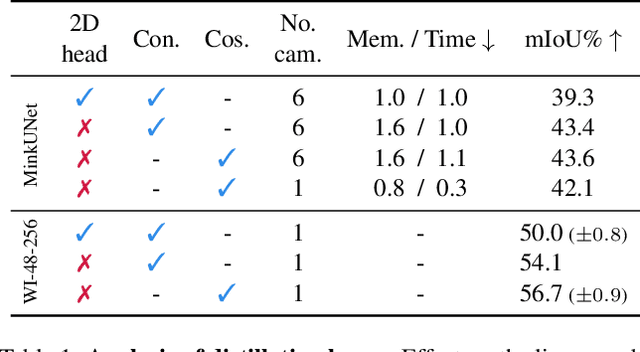
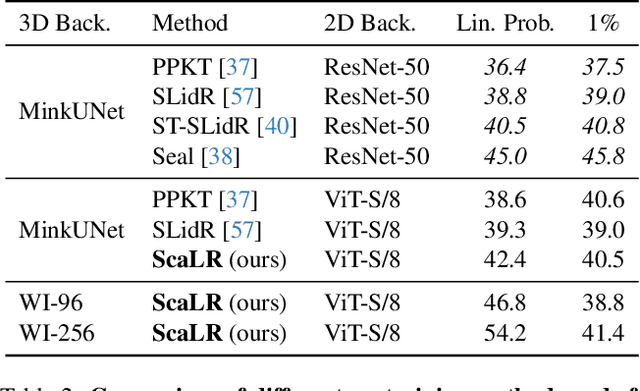
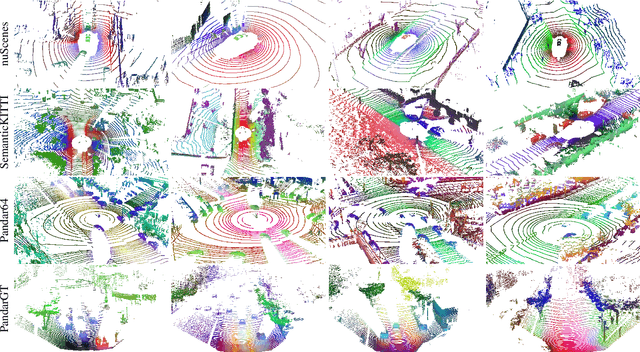
Self-supervised image networks can be used to address complex 2D tasks (e.g., semantic segmentation, object discovery) very efficiently and with little or no downstream supervision. However, self-supervised 3D networks on lidar data do not perform as well for now. A few methods therefore propose to distill high-quality self-supervised 2D features into 3D networks. The most recent ones doing so on autonomous driving data show promising results. Yet, a performance gap persists between these distilled features and fully-supervised ones. In this work, we revisit 2D-to-3D distillation. First, we propose, for semantic segmentation, a simple approach that leads to a significant improvement compared to prior 3D distillation methods. Second, we show that distillation in high capacity 3D networks is key to reach high quality 3D features. This actually allows us to significantly close the gap between unsupervised distilled 3D features and fully-supervised ones. Last, we show that our high-quality distilled representations can also be used for open-vocabulary segmentation and background/foreground discovery.