 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriving on Registers
Jan 08, 2026We present DrivoR, a simple and efficient transformer-based architecture for end-to-end autonomous driving. Our approach builds on pretrained Vision Transformers (ViTs) and introduces camera-aware register tokens that compress multi-camera features into a compact scene representation, significantly reducing downstream computation without sacrificing accuracy. These tokens drive two lightweight transformer decoders that generate and then score candidate trajectories. The scoring decoder learns to mimic an oracle and predicts interpretable sub-scores representing aspects such as safety, comfort, and efficiency, enabling behavior-conditioned driving at inference. Despite its minimal design, DrivoR outperforms or matches strong contemporary baselines across NAVSIM-v1, NAVSIM-v2, and the photorealistic closed-loop HUGSIM benchmark. Our results show that a pure-transformer architecture, combined with targeted token compression, is sufficient for accurate, efficient, and adaptive end-to-end driving. Code and checkpoints will be made available via the project page.
3D sans 3D Scans: Scalable Pre-training from Video-Generated Point Clouds
Dec 28, 2025Despite recent progress in 3D self-supervised learning, collecting large-scale 3D scene scans remains expensive and labor-intensive. In this work, we investigate whether 3D representations can be learned from unlabeled videos recorded without any real 3D sensors. We present Laplacian-Aware Multi-level 3D Clustering with Sinkhorn-Knopp (LAM3C), a self-supervised framework that learns from video-generated point clouds from unlabeled videos. We first introduce RoomTours, a video-generated point cloud dataset constructed by collecting room-walkthrough videos from the web (e.g., real-estate tours) and generating 49,219 scenes using an off-the-shelf feed-forward reconstruction model. We also propose a noise-regularized loss that stabilizes representation learning by enforcing local geometric smoothness and ensuring feature stability under noisy point clouds. Remarkably, without using any real 3D scans, LAM3C achieves higher performance than the previous self-supervised methods on indoor semantic and instance segmentation. These results suggest that unlabeled videos represent an abundant source of data for 3D self-supervised learning.
Improving Semantic Uncertainty Quantification in LVLMs with Semantic Gaussian Processes
Dec 16, 2025Large Vision-Language Models (LVLMs) often produce plausible but unreliable outputs, making robust uncertainty estimation essential. Recent work on semantic uncertainty estimates relies on external models to cluster multiple sampled responses and measure their semantic consistency. However, these clustering methods are often fragile, highly sensitive to minor phrasing variations, and can incorrectly group or separate semantically similar answers, leading to unreliable uncertainty estimates. We propose Semantic Gaussian Process Uncertainty (SGPU), a Bayesian framework that quantifies semantic uncertainty by analyzing the geometric structure of answer embeddings, avoiding brittle clustering. SGPU maps generated answers into a dense semantic space, computes the Gram matrix of their embeddings, and summarizes their semantic configuration via the eigenspectrum. This spectral representation is then fed into a Gaussian Process Classifier that learns to map patterns of semantic consistency to predictive uncertainty, and that can be applied in both black-box and white-box settings. Across six LLMs and LVLMs on eight datasets spanning VQA, image classification, and textual QA, SGPU consistently achieves state-of-the-art calibration (ECE) and discriminative (AUROC, AUARC) performance. We further show that SGPU transfers across models and modalities, indicating that its spectral representation captures general patterns of semantic uncertainty.
LiDAS: Lighting-driven Dynamic Active Sensing for Nighttime Perception
Dec 09, 2025Nighttime environments pose significant challenges for camera-based perception, as existing methods passively rely on the scene lighting. We introduce Lighting-driven Dynamic Active Sensing (LiDAS), a closed-loop active illumination system that combines off-the-shelf visual perception models with high-definition headlights. Rather than uniformly brightening the scene, LiDAS dynamically predicts an optimal illumination field that maximizes downstream perception performance, i.e., decreasing light on empty areas to reallocate it on object regions. LiDAS enables zero-shot nighttime generalization of daytime-trained models through adaptive illumination control. Trained on synthetic data and deployed zero-shot in real-world closed-loop driving scenarios, LiDAS enables +18.7% mAP50 and +5.0% mIoU over standard low-beam at equal power. It maintains performances while reducing energy use by 40%. LiDAS complements domain-generalization methods, further strengthening robustness without retraining. By turning readily available headlights into active vision actuators, LiDAS offers a cost-effective solution to robust nighttime perception.
IPA: An Information-Preserving Input Projection Framework for Efficient Foundation Model Adaptation
Sep 04, 2025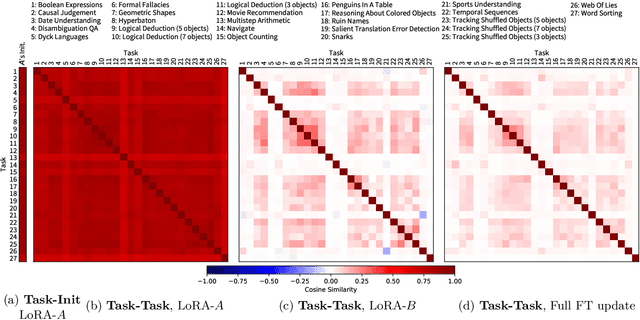
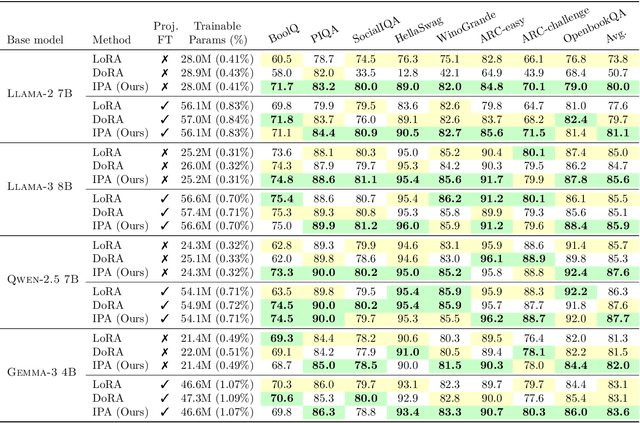
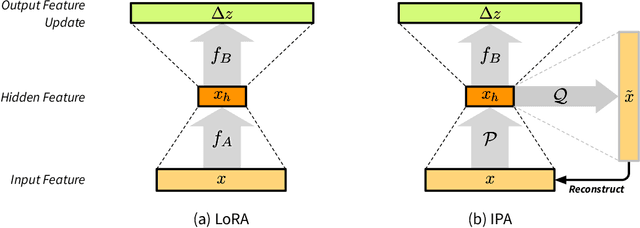
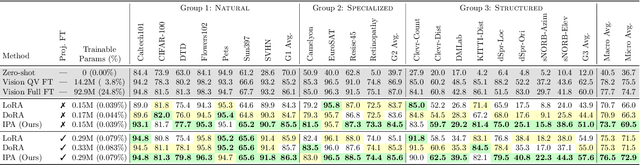
Parameter-efficient fine-tuning (PEFT) methods, such as LoRA, reduce adaptation cost by injecting low-rank updates into pretrained weights. However, LoRA's down-projection is randomly initialized and data-agnostic, discarding potentially useful information. Prior analyses show that this projection changes little during training, while the up-projection carries most of the adaptation, making the random input compression a performance bottleneck. We propose IPA, a feature-aware projection framework that explicitly preserves information in the reduced hidden space. In the linear case, we instantiate IPA with algorithms approximating top principal components, enabling efficient projector pretraining with negligible inference overhead. Across language and vision benchmarks, IPA consistently improves over LoRA and DoRA, achieving on average 1.5 points higher accuracy on commonsense reasoning and 2.3 points on VTAB-1k, while matching full LoRA performance with roughly half the trainable parameters when the projection is frozen.
Franca: Nested Matryoshka Clustering for Scalable Visual Representation Learning
Jul 18, 2025We present Franca (pronounced Fran-ka): free one; the first fully open-source (data, code, weights) vision foundation model that matches and in many cases surpasses the performance of state-of-the-art proprietary models, e.g., DINOv2, CLIP, SigLIPv2, etc. Our approach is grounded in a transparent training pipeline inspired by Web-SSL and uses publicly available data: ImageNet-21K and a subset of ReLAION-2B. Beyond model release, we tackle critical limitations in SSL clustering methods. While modern models rely on assigning image features to large codebooks via clustering algorithms like Sinkhorn-Knopp, they fail to account for the inherent ambiguity in clustering semantics. To address this, we introduce a parameter-efficient, multi-head clustering projector based on nested Matryoshka representations. This design progressively refines features into increasingly fine-grained clusters without increasing the model size, enabling both performance and memory efficiency. Additionally, we propose a novel positional disentanglement strategy that explicitly removes positional biases from dense representations, thereby improving the encoding of semantic content. This leads to consistent gains on several downstream benchmarks, demonstrating the utility of cleaner feature spaces. Our contributions establish a new standard for transparent, high-performance vision models and open a path toward more reproducible and generalizable foundation models for the broader AI community. The code and model checkpoints are available at https://github.com/valeoai/Franca.
FLOSS: Free Lunch in Open-vocabulary Semantic Segmentation
Apr 14, 2025Recent Open-Vocabulary Semantic Segmentation (OVSS) models extend the CLIP model to segmentation while maintaining the use of multiple templates (e.g., a photo of <class>, a sketch of a <class>, etc.) for constructing class-wise averaged text embeddings, acting as a classifier. In this paper, we challenge this status quo and investigate the impact of templates for OVSS. Empirically, we observe that for each class, there exist single-template classifiers significantly outperforming the conventional averaged classifier. We refer to them as class-experts. Given access to unlabeled images and without any training involved, we estimate these experts by leveraging the class-wise prediction entropy of single-template classifiers, selecting as class-wise experts those which yield the lowest entropy. All experts, each specializing in a specific class, collaborate in a newly proposed fusion method to generate more accurate OVSS predictions. Our plug-and-play method, coined FLOSS, is orthogonal and complementary to existing OVSS methods, offering a ''free lunch'' to systematically improve OVSS without labels and additional training. Extensive experiments demonstrate that FLOSS consistently boosts state-of-the-art methods on various OVSS benchmarks. Moreover, the selected expert templates can generalize well from one dataset to others sharing the same semantic categories, yet exhibiting distribution shifts. Additionally, we obtain satisfactory improvements under a low-data regime, where only a few unlabeled images are available. Our code is available at https://github.com/yasserben/FLOSS .
VaViM and VaVAM: Autonomous Driving through Video Generative Modeling
Feb 21, 2025We explore the potential of large-scale generative video models for autonomous driving, introducing an open-source auto-regressive video model (VaViM) and its companion video-action model (VaVAM) to investigate how video pre-training transfers to real-world driving. VaViM is a simple auto-regressive video model that predicts frames using spatio-temporal token sequences. We show that it captures the semantics and dynamics of driving scenes. VaVAM, the video-action model, leverages the learned representations of VaViM to generate driving trajectories through imitation learning. Together, the models form a complete perception-to-action pipeline. We evaluate our models in open- and closed-loop driving scenarios, revealing that video-based pre-training holds promise for autonomous driving. Key insights include the semantic richness of the learned representations, the benefits of scaling for video synthesis, and the complex relationship between model size, data, and safety metrics in closed-loop evaluations. We release code and model weights at https://github.com/valeoai/VideoActionModel
DOC-Depth: A novel approach for dense depth ground truth generation
Feb 04, 2025



Accurate depth information is essential for many computer vision applications. Yet, no available dataset recording method allows for fully dense accurate depth estimation in a large scale dynamic environment. In this paper, we introduce DOC-Depth, a novel, efficient and easy-to-deploy approach for dense depth generation from any LiDAR sensor. After reconstructing consistent dense 3D environment using LiDAR odometry, we address dynamic objects occlusions automatically thanks to DOC, our state-of-the art dynamic object classification method. Additionally, DOC-Depth is fast and scalable, allowing for the creation of unbounded datasets in terms of size and time. We demonstrate the effectiveness of our approach on the KITTI dataset, improving its density from 16.1% to 71.2% and release this new fully dense depth annotation, to facilitate future research in the domain. We also showcase results using various LiDAR sensors and in multiple environments. All software components are publicly available for the research community.
Domain Adaptation with a Single Vision-Language Embedding
Oct 28, 2024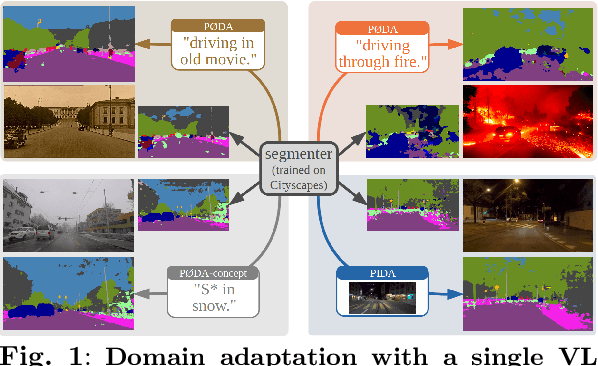
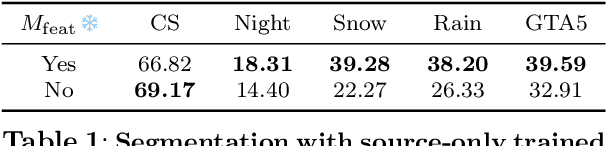
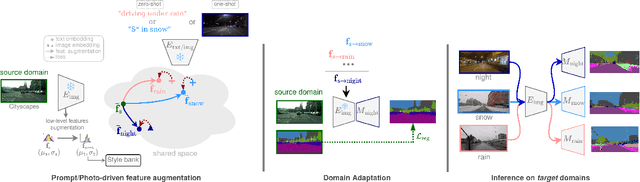
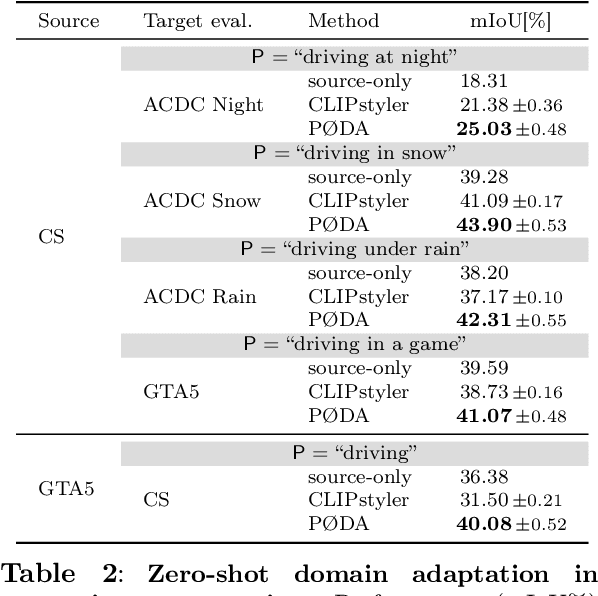
Domain adaptation has been extensively investigated in computer vision but still requires access to target data at the training time, which might be difficult to obtain in some uncommon conditions. In this paper, we present a new framework for domain adaptation relying on a single Vision-Language (VL) latent embedding instead of full target data. First, leveraging a contrastive language-image pre-training model (CLIP), we propose prompt/photo-driven instance normalization (PIN). PIN is a feature augmentation method that mines multiple visual styles using a single target VL latent embedding, by optimizing affine transformations of low-level source features. The VL embedding can come from a language prompt describing the target domain, a partially optimized language prompt, or a single unlabeled target image. Second, we show that these mined styles (i.e., augmentations) can be used for zero-shot (i.e., target-free) and one-shot unsupervised domain adaptation. Experiments on semantic segmentation demonstrate the effectiveness of the proposed method, which outperforms relevant baselines in the zero-shot and one-shot settings.