 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLOSS: Free Lunch in Open-vocabulary Semantic Segmentation
Apr 14, 2025Recent Open-Vocabulary Semantic Segmentation (OVSS) models extend the CLIP model to segmentation while maintaining the use of multiple templates (e.g., a photo of <class>, a sketch of a <class>, etc.) for constructing class-wise averaged text embeddings, acting as a classifier. In this paper, we challenge this status quo and investigate the impact of templates for OVSS. Empirically, we observe that for each class, there exist single-template classifiers significantly outperforming the conventional averaged classifier. We refer to them as class-experts. Given access to unlabeled images and without any training involved, we estimate these experts by leveraging the class-wise prediction entropy of single-template classifiers, selecting as class-wise experts those which yield the lowest entropy. All experts, each specializing in a specific class, collaborate in a newly proposed fusion method to generate more accurate OVSS predictions. Our plug-and-play method, coined FLOSS, is orthogonal and complementary to existing OVSS methods, offering a ''free lunch'' to systematically improve OVSS without labels and additional training. Extensive experiments demonstrate that FLOSS consistently boosts state-of-the-art methods on various OVSS benchmarks. Moreover, the selected expert templates can generalize well from one dataset to others sharing the same semantic categories, yet exhibiting distribution shifts. Additionally, we obtain satisfactory improvements under a low-data regime, where only a few unlabeled images are available. Our code is available at https://github.com/yasserben/FLOSS .
Domain Adaptation with a Single Vision-Language Embedding
Oct 28, 2024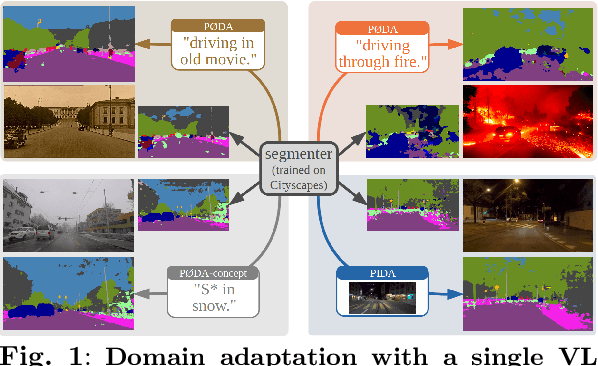
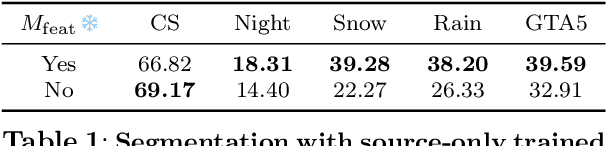
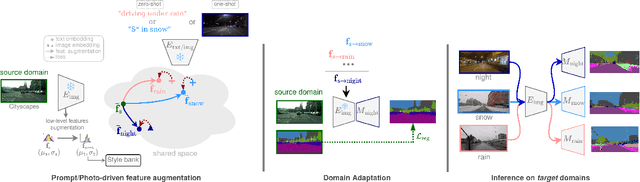
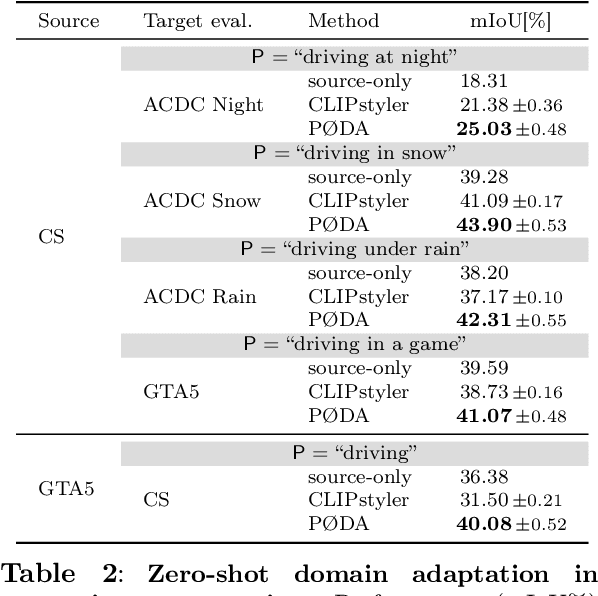
Domain adaptation has been extensively investigated in computer vision but still requires access to target data at the training time, which might be difficult to obtain in some uncommon conditions. In this paper, we present a new framework for domain adaptation relying on a single Vision-Language (VL) latent embedding instead of full target data. First, leveraging a contrastive language-image pre-training model (CLIP), we propose prompt/photo-driven instance normalization (PIN). PIN is a feature augmentation method that mines multiple visual styles using a single target VL latent embedding, by optimizing affine transformations of low-level source features. The VL embedding can come from a language prompt describing the target domain, a partially optimized language prompt, or a single unlabeled target image. Second, we show that these mined styles (i.e., augmentations) can be used for zero-shot (i.e., target-free) and one-shot unsupervised domain adaptation. Experiments on semantic segmentation demonstrate the effectiveness of the proposed method, which outperforms relevant baselines in the zero-shot and one-shot settings.
Fine-Tuning CLIP's Last Visual Projector: A Few-Shot Cornucopia
Oct 07, 2024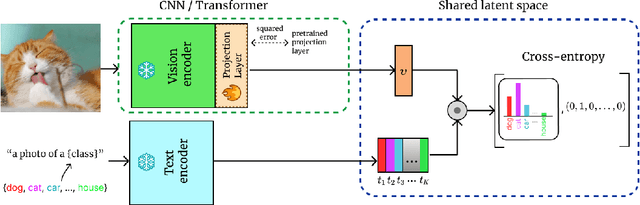
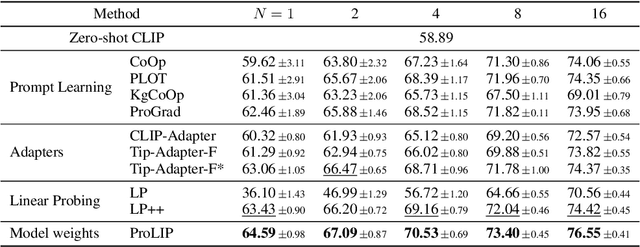

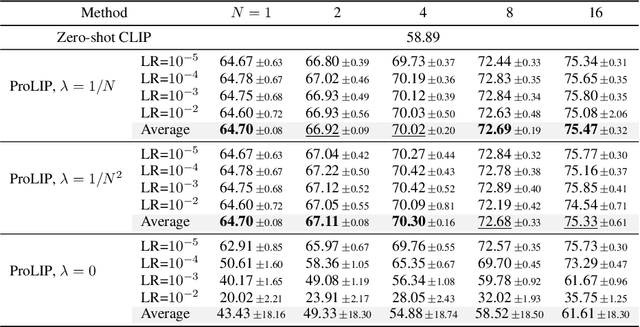
We consider the problem of adapting a contrastively pretrained vision-language model like CLIP (Radford et al., 2021) for few-shot classification. The existing literature addresses this problem by learning a linear classifier of the frozen visual features, optimizing word embeddings, or learning external feature adapters. This paper introduces an alternative way for CLIP adaptation without adding 'external' parameters to optimize. We find that simply fine-tuning the last projection matrix of the vision encoder leads to strong performance compared to the existing baselines. Furthermore, we show that regularizing training with the distance between the fine-tuned and pretrained matrices adds reliability for adapting CLIP through this layer. Perhaps surprisingly, this approach, coined ProLIP, yields performances on par or better than state of the art on 11 few-shot classification benchmarks, few-shot domain generalization, cross-dataset transfer and test-time adaptation. Code will be made available at https://github.com/astra-vision/ProLIP .
A Simple Recipe for Language-guided Domain Generalized Segmentation
Nov 29, 2023



Generalization to new domains not seen during training is one of the long-standing goals and challenges in deploying neural networks in real-world applications. Existing generalization techniques necessitate substantial data augmentation, potentially sourced from external datasets, and aim at learning invariant representations by imposing various alignment constraints. Large-scale pretraining has recently shown promising generalization capabilities, along with the potential of bridging different modalities. For instance, the recent advent of vision-language models like CLIP has opened the doorway for vision models to exploit the textual modality. In this paper, we introduce a simple framework for generalizing semantic segmentation networks by employing language as the source of randomization. Our recipe comprises three key ingredients: i) the preservation of the intrinsic CLIP robustness through minimal fine-tuning, ii) language-driven local style augmentation, and iii) randomization by locally mixing the source and augmented styles during training. Extensive experiments report state-of-the-art results on various generalization benchmarks. The code will be made available.
PØDA: Prompt-driven Zero-shot Domain Adaptation
Dec 06, 2022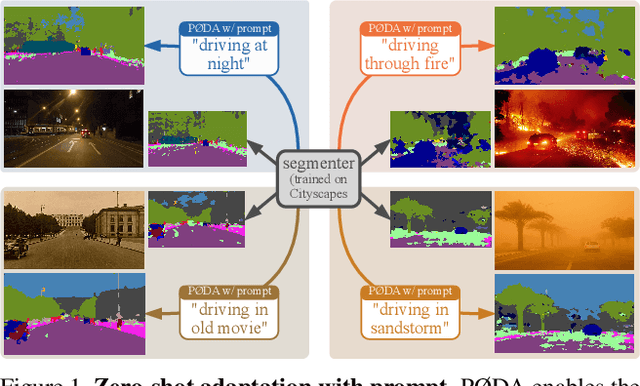


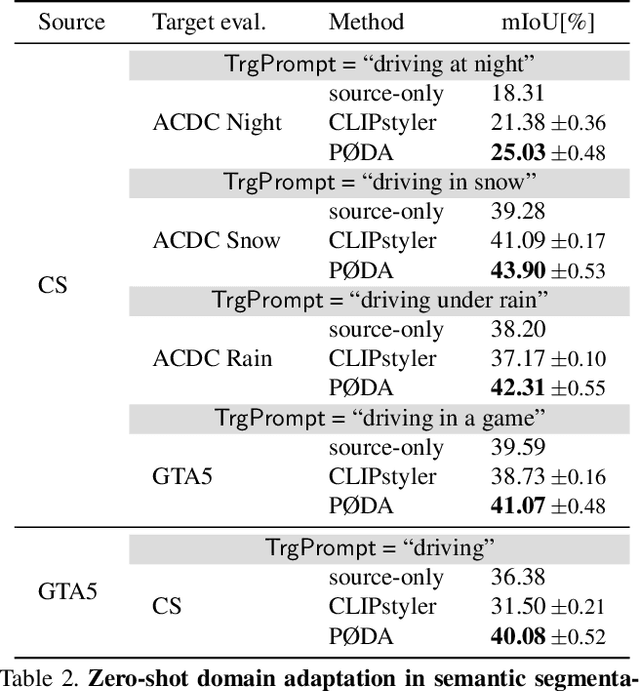
Domain adaptation has been vastly investigated in computer vision but still requires access to target images at train time, which might be intractable in some conditions, especially for long-tail samples. In this paper, we propose the task of `Prompt-driven Zero-shot Domain Adaptation', where we adapt a model trained on a source domain using only a general textual description of the target domain, i.e., a prompt. First, we leverage a pretrained contrastive vision-language model (CLIP) to optimize affine transformations of source features, bringing them closer to target text embeddings, while preserving their content and semantics. Second, we show that augmented features can be used to perform zero-shot domain adaptation for semantic segmentation. Experiments demonstrate that our method significantly outperforms CLIP-based style transfer baselines on several datasets for the downstream task at hand. Our prompt-driven approach even outperforms one-shot unsupervised domain adaptation on some datasets, and gives comparable results on others. The code is available at https://github.com/astra-vision/PODA.
unrolling palm for sparse semi-blind source separation
Dec 10, 2021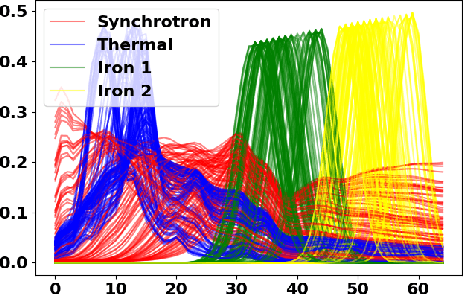
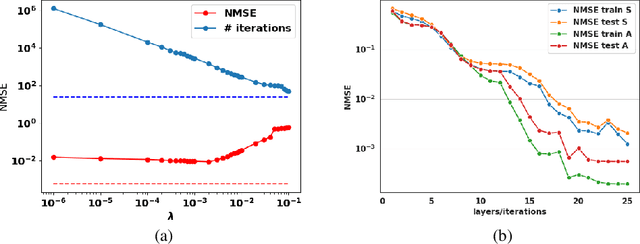

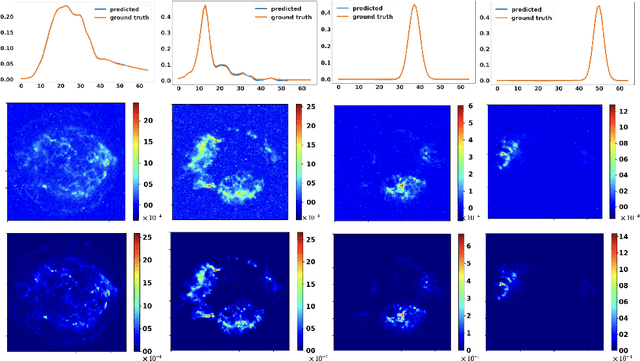
Sparse Blind Source Separation (BSS) has become a well established tool for a wide range of applications - for instance, in astrophysics and remote sensing. Classical sparse BSS methods, such as the Proximal Alternating Linearized Minimization (PALM) algorithm, nevertheless often suffer from a difficult hyperparameter choice, which undermines their results. To bypass this pitfall, we propose in this work to build on the thriving field of algorithm unfolding/unrolling. Unrolling PALM enables to leverage the data-driven knowledge stemming from realistic simulations or ground-truth data by learning both PALM hyperparameters and variables. In contrast to most existing unrolled algorithms, which assume a fixed known dictionary during the training and testing phases, this article further emphasizes on the ability to deal with variable mixing matrices (a.k.a. dictionaries). The proposed Learned PALM (LPALM) algorithm thus enables to perform semi-blind source separation, which is key to increase the generalization of the learnt model in real-world applications. We illustrate the relevance of LPALM in astrophysical multispectral imaging: the algorithm not only needs up to $10^4-10^5$ times fewer iterations than PALM, but also improves the separation quality, while avoiding the cumbersome hyperparameter and initialization choice of PALM. We further show that LPALM outperforms other unrolled source separation methods in the semi-blind setting.