 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASA: Cross-Attention via Self-Attention for Efficient Vision-Language Fusion
Dec 22, 2025Vision-language models (VLMs) are commonly trained by inserting image tokens from a pretrained vision encoder into the textual stream of a language model. This allows text and image information to fully attend to one another within the model, but becomes extremely costly for high-resolution images, long conversations, or streaming videos, both in memory and compute. VLMs leveraging cross-attention are an efficient alternative to token insertion but exhibit a clear performance gap, in particular on tasks involving fine-grained visual details. We find that a key to improving such models is to also enable local text-to-text interaction in the dedicated cross-attention layers. Building on this, we propose CASA, Cross-Attention via Self-Attention, a simple and efficient paradigm which substantially reduces the gap with full token insertion on common image understanding benchmarks, while enjoying the same scalability as cross-attention models when applied to long-context multimodal tasks such as streaming video captioning. For samples and code, please see our project page at https://kyutai.org/casa .
ARC-Encoder: learning compressed text representations for large language models
Oct 23, 2025Recent techniques such as retrieval-augmented generation or chain-of-thought reasoning have led to longer contexts and increased inference costs. Context compression techniques can reduce these costs, but the most effective approaches require fine-tuning the target model or even modifying its architecture. This can degrade its general abilities when not used for this specific purpose. Here we explore an alternative approach: an encoder that compresses the context into continuous representations which replace token embeddings in decoder LLMs. First, we perform a systematic study of training strategies and architecture choices for the encoder. Our findings led to the design of an Adaptable text Representations Compressor, named ARC-Encoder, which outputs $x$-times fewer continuous representations (typically $x\!\in\!\{4,8\}$) than text tokens. We evaluate ARC-Encoder across a variety of LLM usage scenarios, ranging from in-context learning to context window extension, on both instruct and base decoders. Results show that ARC-Encoder achieves state-of-the-art performance on several benchmarks while improving computational efficiency at inference. Finally, we demonstrate that our models can be adapted to multiple decoders simultaneously, allowing a single encoder to generalize across different decoder LLMs. This makes ARC-Encoder a flexible and efficient solution for portable encoders that work seamlessly with multiple LLMs. We release a training code at https://github.com/kyutai-labs/ARC-Encoder , fine-tuning dataset and pretrained models are available at https://huggingface.co/collections/kyutai/arc-encoders-68ee18787301407d60a57047 .
Streaming Sequence-to-Sequence Learning with Delayed Streams Modeling
Sep 10, 2025We introduce Delayed Streams Modeling (DSM), a flexible formulation for streaming, multimodal sequence-to-sequence learning. Sequence-to-sequence generation is often cast in an offline manner, where the model consumes the complete input sequence before generating the first output timestep. Alternatively, streaming sequence-to-sequence rely on learning a policy for choosing when to advance on the input stream, or write to the output stream. DSM instead models already time-aligned streams with a decoder-only language model. By moving the alignment to a pre-processing step,and introducing appropriate delays between streams, DSM provides streaming inference of arbitrary output sequences, from any input combination, making it applicable to many sequence-to-sequence problems. In particular, given text and audio streams, automatic speech recognition (ASR) corresponds to the text stream being delayed, while the opposite gives a text-to-speech (TTS) model. We perform extensive experiments for these two major sequence-to-sequence tasks, showing that DSM provides state-of-the-art performance and latency while supporting arbitrary long sequences, being even competitive with offline baselines. Code, samples and demos are available at https://github.com/kyutai-labs/delayed-streams-modeling
Vision-Speech Models: Teaching Speech Models to Converse about Images
Mar 19, 2025The recent successes of Vision-Language models raise the question of how to equivalently imbue a pretrained speech model with vision understanding, an important milestone towards building a multimodal speech model able to freely converse about images. Building such a conversational Vision-Speech model brings its unique challenges: (i) paired image-speech datasets are much scarcer than their image-text counterparts, (ii) ensuring real-time latency at inference is crucial thus bringing compute and memory constraints, and (iii) the model should preserve prosodic features (e.g., speaker tone) which cannot be inferred from text alone. In this work, we introduce MoshiVis, augmenting a recent dialogue speech LLM, Moshi, with visual inputs through lightweight adaptation modules. An additional dynamic gating mechanism enables the model to more easily switch between the visual inputs and unrelated conversation topics. To reduce training costs, we design a simple one-stage, parameter-efficient fine-tuning pipeline in which we leverage a mixture of image-text (i.e., "speechless") and image-speech samples. We evaluate the model on downstream visual understanding tasks with both audio and text prompts, and report qualitative samples of interactions with MoshiVis. Our inference code will be made available, as well as the image-speech data used for audio evaluation.
High-Fidelity Simultaneous Speech-To-Speech Translation
Feb 05, 2025



We introduce Hibiki, a decoder-only model for simultaneous speech translation. Hibiki leverages a multistream language model to synchronously process source and target speech, and jointly produces text and audio tokens to perform speech-to-text and speech-to-speech translation. We furthermore address the fundamental challenge of simultaneous interpretation, which unlike its consecutive counterpart, where one waits for the end of the source utterance to start translating, adapts its flow to accumulate just enough context to produce a correct translation in real-time, chunk by chunk. To do so, we introduce a weakly-supervised method that leverages the perplexity of an off-the-shelf text translation system to identify optimal delays on a per-word basis and create aligned synthetic data. After supervised training, Hibiki performs adaptive, simultaneous speech translation with vanilla temperature sampling. On a French-English simultaneous speech translation task, Hibiki demonstrates state-of-the-art performance in translation quality, speaker fidelity and naturalness. Moreover, the simplicity of its inference process makes it compatible with batched translation and even real-time on-device deployment. We provide examples as well as models and inference code.
Domain Adaptation with a Single Vision-Language Embedding
Oct 28, 2024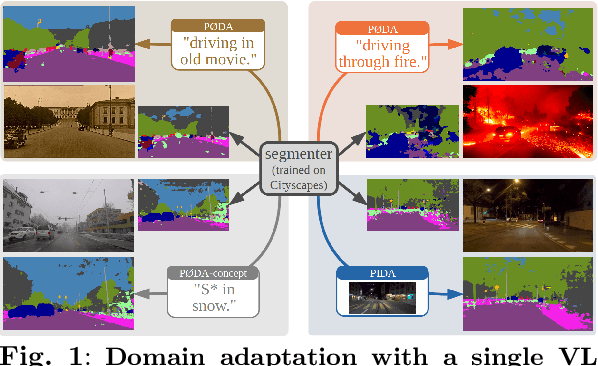
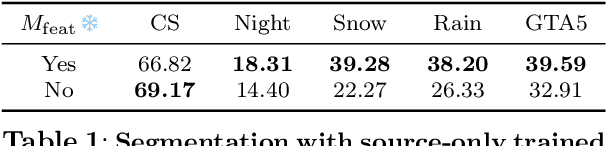
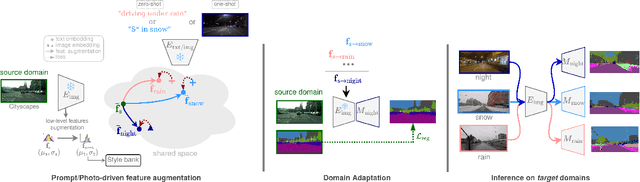
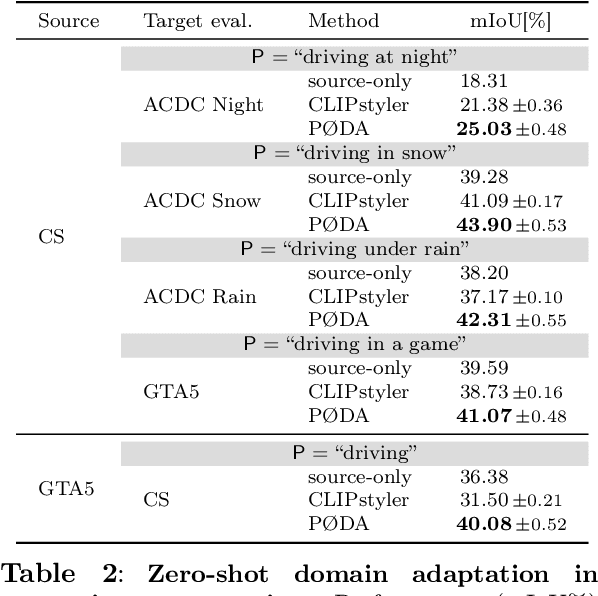
Domain adaptation has been extensively investigated in computer vision but still requires access to target data at the training time, which might be difficult to obtain in some uncommon conditions. In this paper, we present a new framework for domain adaptation relying on a single Vision-Language (VL) latent embedding instead of full target data. First, leveraging a contrastive language-image pre-training model (CLIP), we propose prompt/photo-driven instance normalization (PIN). PIN is a feature augmentation method that mines multiple visual styles using a single target VL latent embedding, by optimizing affine transformations of low-level source features. The VL embedding can come from a language prompt describing the target domain, a partially optimized language prompt, or a single unlabeled target image. Second, we show that these mined styles (i.e., augmentations) can be used for zero-shot (i.e., target-free) and one-shot unsupervised domain adaptation. Experiments on semantic segmentation demonstrate the effectiveness of the proposed method, which outperforms relevant baselines in the zero-shot and one-shot settings.
Fine-Tuning CLIP's Last Visual Projector: A Few-Shot Cornucopia
Oct 07, 2024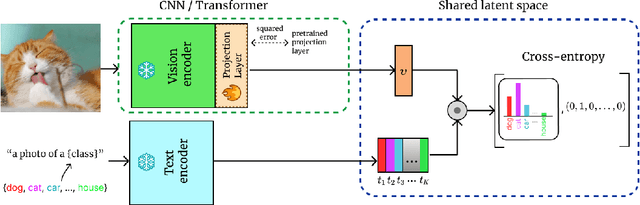
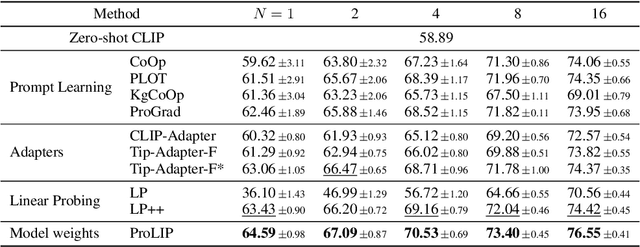

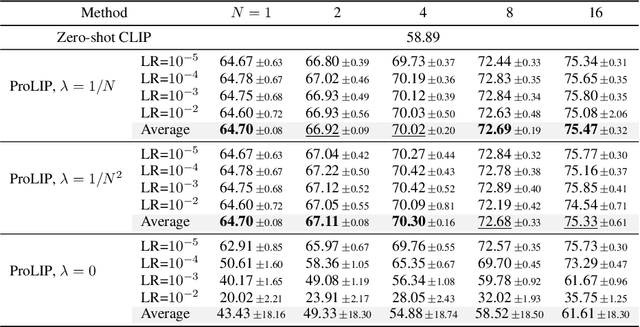
We consider the problem of adapting a contrastively pretrained vision-language model like CLIP (Radford et al., 2021) for few-shot classification. The existing literature addresses this problem by learning a linear classifier of the frozen visual features, optimizing word embeddings, or learning external feature adapters. This paper introduces an alternative way for CLIP adaptation without adding 'external' parameters to optimize. We find that simply fine-tuning the last projection matrix of the vision encoder leads to strong performance compared to the existing baselines. Furthermore, we show that regularizing training with the distance between the fine-tuned and pretrained matrices adds reliability for adapting CLIP through this layer. Perhaps surprisingly, this approach, coined ProLIP, yields performances on par or better than state of the art on 11 few-shot classification benchmarks, few-shot domain generalization, cross-dataset transfer and test-time adaptation. Code will be made available at https://github.com/astra-vision/ProLIP .
Winner-takes-all learners are geometry-aware conditional density estimators
Jun 07, 2024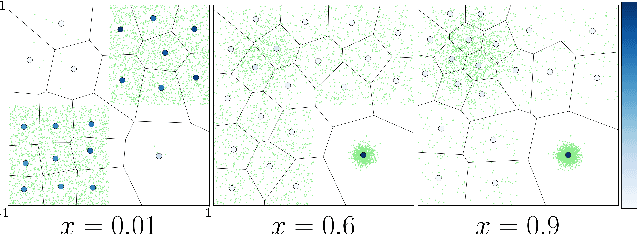
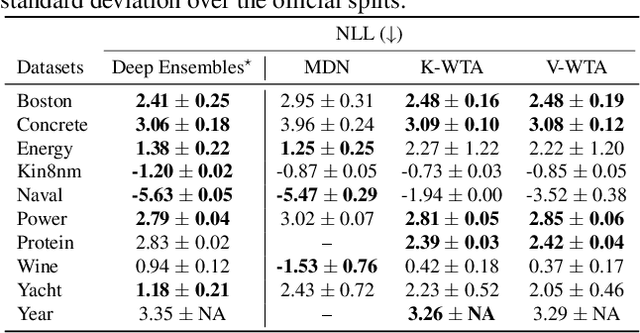
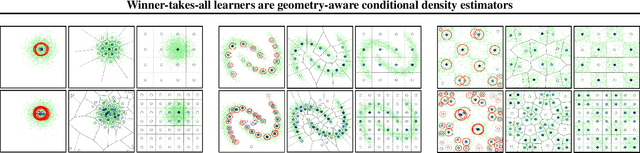
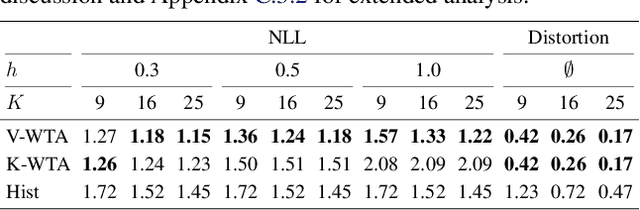
Winner-takes-all training is a simple learning paradigm, which handles ambiguous tasks by predicting a set of plausible hypotheses. Recently, a connection was established between Winner-takes-all training and centroidal Voronoi tessellations, showing that, once trained, hypotheses should quantize optimally the shape of the conditional distribution to predict. However, the best use of these hypotheses for uncertainty quantification is still an open question.In this work, we show how to leverage the appealing geometric properties of the Winner-takes-all learners for conditional density estimation, without modifying its original training scheme. We theoretically establish the advantages of our novel estimator both in terms of quantization and density estimation, and we demonstrate its competitiveness on synthetic and real-world datasets, including audio data.
OccFeat: Self-supervised Occupancy Feature Prediction for Pretraining BEV Segmentation Networks
Apr 22, 2024



We introduce a self-supervised pretraining method, called OcFeat, for camera-only Bird's-Eye-View (BEV) segmentation networks. With OccFeat, we pretrain a BEV network via occupancy prediction and feature distillation tasks. Occupancy prediction provides a 3D geometric understanding of the scene to the model. However, the geometry learned is class-agnostic. Hence, we add semantic information to the model in the 3D space through distillation from a self-supervised pretrained image foundation model. Models pretrained with our method exhibit improved BEV semantic segmentation performance, particularly in low-data scenarios. Moreover, empirical results affirm the efficacy of integrating feature distillation with 3D occupancy prediction in our pretraining approach.
POP-3D: Open-Vocabulary 3D Occupancy Prediction from Images
Jan 17, 2024



We describe an approach to predict open-vocabulary 3D semantic voxel occupancy map from input 2D images with the objective of enabling 3D grounding, segmentation and retrieval of free-form language queries. This is a challenging problem because of the 2D-3D ambiguity and the open-vocabulary nature of the target tasks, where obtaining annotated training data in 3D is difficult. The contributions of this work are three-fold. First, we design a new model architecture for open-vocabulary 3D semantic occupancy prediction. The architecture consists of a 2D-3D encoder together with occupancy prediction and 3D-language heads. The output is a dense voxel map of 3D grounded language embeddings enabling a range of open-vocabulary tasks. Second, we develop a tri-modal self-supervised learning algorithm that leverages three modalities: (i) images, (ii) language and (iii) LiDAR point clouds, and enables training the proposed architecture using a strong pre-trained vision-language model without the need for any 3D manual language annotations. Finally, we demonstrate quantitatively the strengths of the proposed model on several open-vocabulary tasks: Zero-shot 3D semantic segmentation using existing datasets; 3D grounding and retrieval of free-form language queries, using a small dataset that we propose as an extension of nuScenes. You can find the project page here https://vobecant.github.io/POP3D.