 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Test-time Contrastive Concepts for Open-world, Open-vocabulary Semantic Segmentation
Jul 06, 2024



Recent VLMs, pre-trained on large amounts of image-text pairs to align both modalities, have opened the way to open-vocabulary semantic segmentation. Given an arbitrary set of textual queries, image regions are assigned the closest query in feature space. However, the usual setup expects the user to list all possible visual concepts that may occur in the image, typically all classes of benchmark datasets, that act as negatives to each other. We consider here the more challenging scenario of segmenting a single concept, given a textual prompt and nothing else. To achieve good results, besides contrasting with the generic 'background' text, we study different ways to generate query-specific test-time contrastive textual concepts, which leverage either the distribution of text in the VLM's training set or crafted LLM prompts. We show the relevance of our approach using a new, specific metric.
OccFeat: Self-supervised Occupancy Feature Prediction for Pretraining BEV Segmentation Networks
Apr 22, 2024



We introduce a self-supervised pretraining method, called OcFeat, for camera-only Bird's-Eye-View (BEV) segmentation networks. With OccFeat, we pretrain a BEV network via occupancy prediction and feature distillation tasks. Occupancy prediction provides a 3D geometric understanding of the scene to the model. However, the geometry learned is class-agnostic. Hence, we add semantic information to the model in the 3D space through distillation from a self-supervised pretrained image foundation model. Models pretrained with our method exhibit improved BEV semantic segmentation performance, particularly in low-data scenarios. Moreover, empirical results affirm the efficacy of integrating feature distillation with 3D occupancy prediction in our pretraining approach.
POP-3D: Open-Vocabulary 3D Occupancy Prediction from Images
Jan 17, 2024



We describe an approach to predict open-vocabulary 3D semantic voxel occupancy map from input 2D images with the objective of enabling 3D grounding, segmentation and retrieval of free-form language queries. This is a challenging problem because of the 2D-3D ambiguity and the open-vocabulary nature of the target tasks, where obtaining annotated training data in 3D is difficult. The contributions of this work are three-fold. First, we design a new model architecture for open-vocabulary 3D semantic occupancy prediction. The architecture consists of a 2D-3D encoder together with occupancy prediction and 3D-language heads. The output is a dense voxel map of 3D grounded language embeddings enabling a range of open-vocabulary tasks. Second, we develop a tri-modal self-supervised learning algorithm that leverages three modalities: (i) images, (ii) language and (iii) LiDAR point clouds, and enables training the proposed architecture using a strong pre-trained vision-language model without the need for any 3D manual language annotations. Finally, we demonstrate quantitatively the strengths of the proposed model on several open-vocabulary tasks: Zero-shot 3D semantic segmentation using existing datasets; 3D grounding and retrieval of free-form language queries, using a small dataset that we propose as an extension of nuScenes. You can find the project page here https://vobecant.github.io/POP3D.
MOCA: Self-supervised Representation Learning by Predicting Masked Online Codebook Assignments
Jul 18, 2023Self-supervised learning can be used for mitigating the greedy needs of Vision Transformer networks for very large fully-annotated datasets. Different classes of self-supervised learning offer representations with either good contextual reasoning properties, e.g., using masked image modeling strategies, or invariance to image perturbations, e.g., with contrastive methods. In this work, we propose a single-stage and standalone method, MOCA, which unifies both desired properties using novel mask-and-predict objectives defined with high-level features (instead of pixel-level details). Moreover, we show how to effectively employ both learning paradigms in a synergistic and computation-efficient way. Doing so, we achieve new state-of-the-art results on low-shot settings and strong experimental results in various evaluation protocols with a training that is at least 3 times faster than prior methods.
Unsupervised Object Localization: Observing the Background to Discover Objects
Dec 15, 2022Recent advances in self-supervised visual representation learning have paved the way for unsupervised methods tackling tasks such as object discovery and instance segmentation. However, discovering objects in an image with no supervision is a very hard task; what are the desired objects, when to separate them into parts, how many are there, and of what classes? The answers to these questions depend on the tasks and datasets of evaluation. In this work, we take a different approach and propose to look for the background instead. This way, the salient objects emerge as a by-product without any strong assumption on what an object should be. We propose FOUND, a simple model made of a single $conv1\times1$ initialized with coarse background masks extracted from self-supervised patch-based representations. After fast training and refining these seed masks, the model reaches state-of-the-art results on unsupervised saliency detection and object discovery benchmarks. Moreover, we show that our approach yields good results in the unsupervised semantic segmentation retrieval task. The code to reproduce our results is available at https://github.com/valeoai/FOUND.
Drive&Segment: Unsupervised Semantic Segmentation of Urban Scenes via Cross-modal Distillation
Mar 21, 2022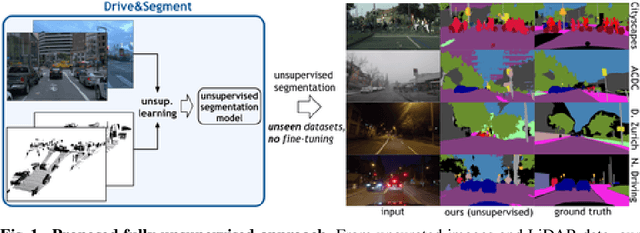
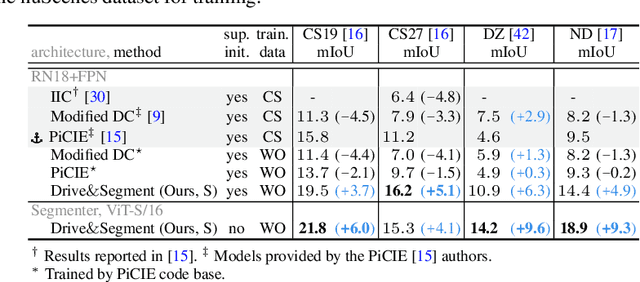
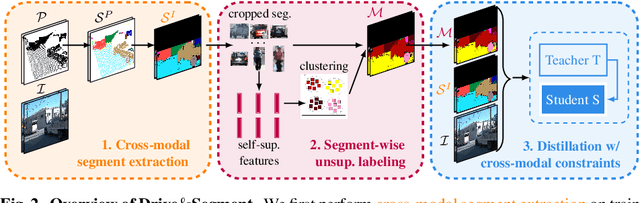
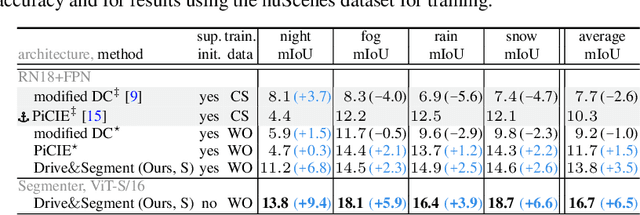
This work investigates learning pixel-wise semantic image segmentation in urban scenes without any manual annotation, just from the raw non-curated data collected by cars which, equipped with cameras and LiDAR sensors, drive around a city. Our contributions are threefold. First, we propose a novel method for cross-modal unsupervised learning of semantic image segmentation by leveraging synchronized LiDAR and image data. The key ingredient of our method is the use of an object proposal module that analyzes the LiDAR point cloud to obtain proposals for spatially consistent objects. Second, we show that these 3D object proposals can be aligned with the input images and reliably clustered into semantically meaningful pseudo-classes. Finally, we develop a cross-modal distillation approach that leverages image data partially annotated with the resulting pseudo-classes to train a transformer-based model for image semantic segmentation. We show the generalization capabilities of our method by testing on four different testing datasets (Cityscapes, Dark Zurich, Nighttime Driving and ACDC) without any finetuning, and demonstrate significant improvements compared to the current state of the art on this problem. See project webpage https://vobecant.github.io/DriveAndSegment/ for the code and more.
Let's Get Dirty: GAN Based Data Augmentation for Soiling and Adverse Weather Classification in Autonomous Driving
Dec 04, 2019

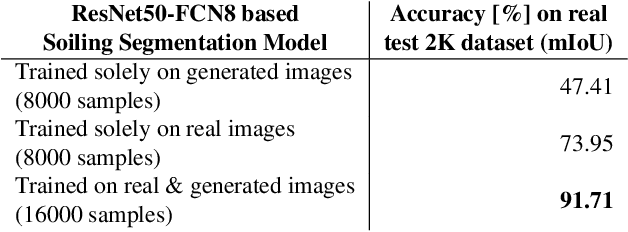

Cameras are getting more and more important in autonomous driving. Wide-angle fisheye cameras are relatively cheap sensors and very suitable for automated parking and low-speed navigation tasks. Four of such cameras form a surround-view system that provides a complete and detailed view around the vehicle. These cameras are usually directly exposed to harsh environmental settings and therefore can get soiled very easily by mud, dust, water, frost, etc. The soiling on the camera lens has a direct impact on the further processing of the images they provide. While adverse weather conditions, such as rain, are getting attention recently, there is limited work on lens soiling. We believe that one of the reasons is that it is difficult to build a diverse dataset for this task, which is moreover expensive to annotate. We propose a novel GAN based algorithm for generating artificial soiling data along with the corresponding annotation masks. The manually annotated soiling dataset and the generated augmentation dataset will be made public. We demonstrate the generalization of our fisheye trained soiling GAN model on the Cityscapes dataset. Additionally, we provide an empirical evaluation of the degradation of the semantic segmentation algorithm with the soiled data.