 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynWoodScape: Synthetic Surround-view Fisheye Camera Dataset for Autonomous Driving
Mar 09, 2022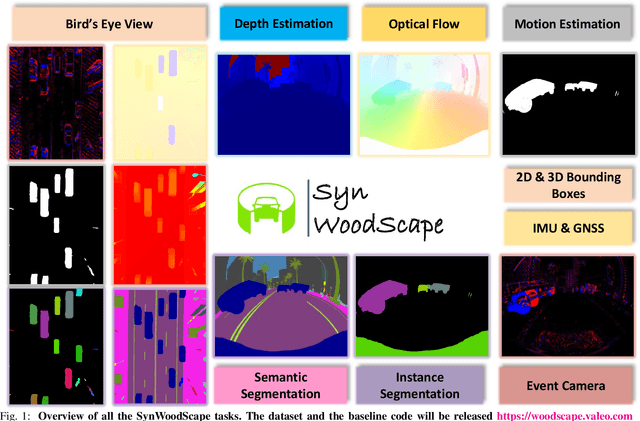
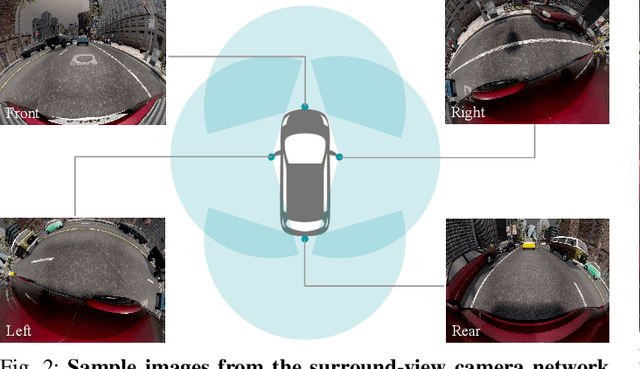
Surround-view cameras are a primary sensor for automated driving, used for near field perception. It is one of the most commonly used sensors in commercial vehicles. Four fisheye cameras with a 190{\deg} field of view cover the 360{\deg} around the vehicle. Due to its high radial distortion, the standard algorithms do not extend easily. Previously, we released the first public fisheye surround-view dataset named WoodScape. In this work, we release a synthetic version of the surround-view dataset, covering many of its weaknesses and extending it. Firstly, it is not possible to obtain ground truth for pixel-wise optical flow and depth. Secondly, WoodScape did not have all four cameras simultaneously in order to sample diverse frames. However, this means that multi-camera algorithms cannot be designed, which is enabled in the new dataset. We implemented surround-view fisheye geometric projections in CARLA Simulator matching WoodScape's configuration and created SynWoodScape. We release 80k images from the synthetic dataset with annotations for 10+ tasks. We also release the baseline code and supporting scripts.
LiMoSeg: Real-time Bird's Eye View based LiDAR Motion Segmentation
Nov 08, 2021

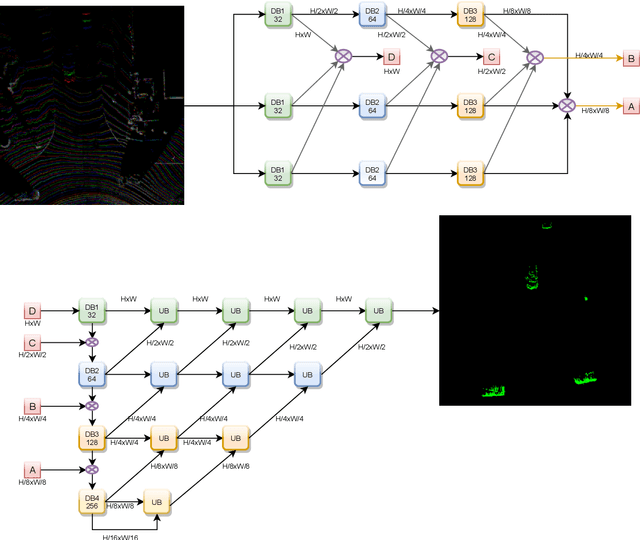

Moving object detection and segmentation is an essential task in the Autonomous Driving pipeline. Detecting and isolating static and moving components of a vehicle's surroundings are particularly crucial in path planning and localization tasks. This paper proposes a novel real-time architecture for motion segmentation of Light Detection and Ranging (LiDAR) data. We use two successive scans of LiDAR data in 2D Bird's Eye View (BEV) representation to perform pixel-wise classification as static or moving. Furthermore, we propose a novel data augmentation technique to reduce the significant class imbalance between static and moving objects. We achieve this by artificially synthesizing moving objects by cutting and pasting static vehicles. We demonstrate a low latency of 8 ms on a commonly used automotive embedded platform, namely Nvidia Jetson Xavier. To the best of our knowledge, this is the first work directly performing motion segmentation in LiDAR BEV space. We provide quantitative results on the challenging SemanticKITTI dataset, and qualitative results are provided in https://youtu.be/2aJ-cL8b0LI.
BEV-MODNet: Monocular Camera based Bird's Eye View Moving Object Detection for Autonomous Driving
Jul 11, 2021


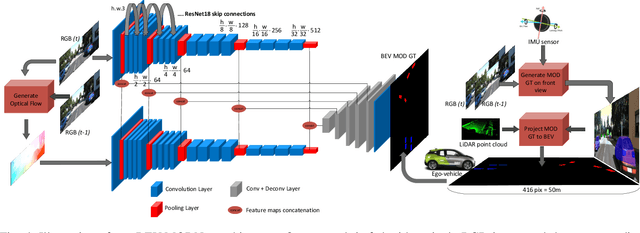
Detection of moving objects is a very important task in autonomous driving systems. After the perception phase, motion planning is typically performed in Bird's Eye View (BEV) space. This would require projection of objects detected on the image plane to top view BEV plane. Such a projection is prone to errors due to lack of depth information and noisy mapping in far away areas. CNNs can leverage the global context in the scene to project better. In this work, we explore end-to-end Moving Object Detection (MOD) on the BEV map directly using monocular images as input. To the best of our knowledge, such a dataset does not exist and we create an extended KITTI-raw dataset consisting of 12.9k images with annotations of moving object masks in BEV space for five classes. The dataset is intended to be used for class agnostic motion cue based object detection and classes are provided as meta-data for better tuning. We design and implement a two-stream RGB and optical flow fusion architecture which outputs motion segmentation directly in BEV space. We compare it with inverse perspective mapping of state-of-the-art motion segmentation predictions on the image plane. We observe a significant improvement of 13% in mIoU using the simple baseline implementation. This demonstrates the ability to directly learn motion segmentation output in BEV space. Qualitative results of our baseline and the dataset annotations can be found in https://sites.google.com/view/bev-modnet.
VM-MODNet: Vehicle Motion aware Moving Object Detection for Autonomous Driving
Apr 22, 2021


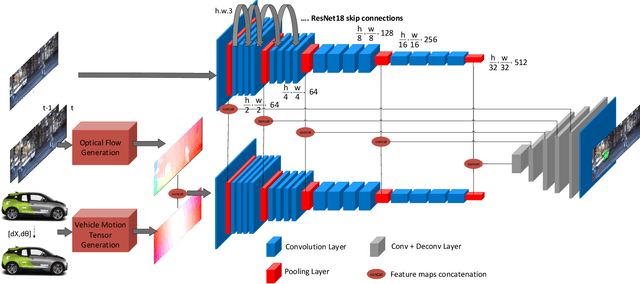
Moving object Detection (MOD) is a critical task in autonomous driving as moving agents around the ego-vehicle need to be accurately detected for safe trajectory planning. It also enables appearance agnostic detection of objects based on motion cues. There are geometric challenges like motion-parallax ambiguity which makes it a difficult problem. In this work, we aim to leverage the vehicle motion information and feed it into the model to have an adaptation mechanism based on ego-motion. The motivation is to enable the model to implicitly perform ego-motion compensation to improve performance. We convert the six degrees of freedom vehicle motion into a pixel-wise tensor which can be fed as input to the CNN model. The proposed model using Vehicle Motion Tensor (VMT) achieves an absolute improvement of 5.6% in mIoU over the baseline architecture. We also achieve state-of-the-art results on the public KITTI_MoSeg_Extended dataset even compared to methods which make use of LiDAR and additional input frames. Our model is also lightweight and runs at 85 fps on a TitanX GPU. Qualitative results are provided in https://youtu.be/ezbfjti-kTk.
OmniDet: Surround View Cameras based Multi-task Visual Perception Network for Autonomous Driving
Feb 15, 2021
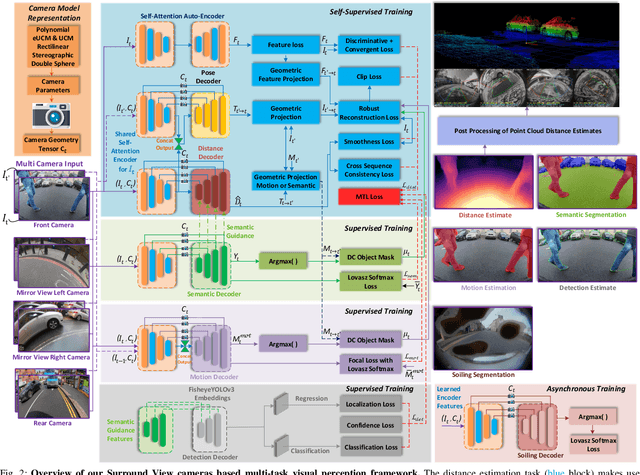
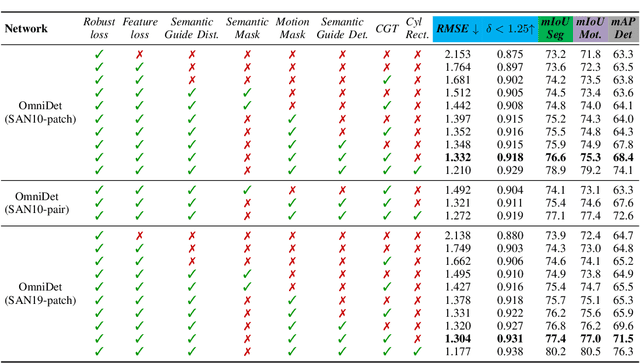
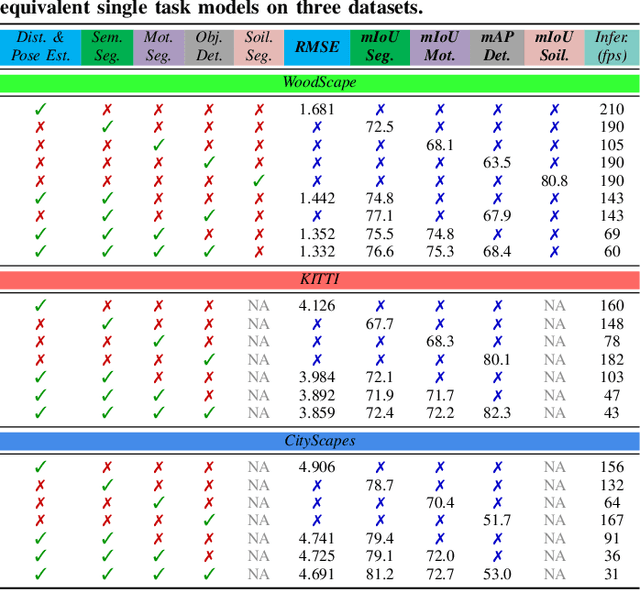
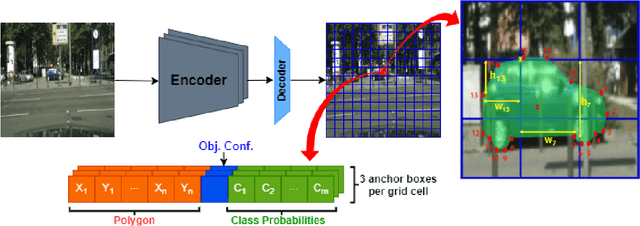
Surround View fisheye cameras are commonly deployed in automated driving for 360\deg{} near-field sensing around the vehicle. This work presents a multi-task visual perception network on unrectified fisheye images to enable the vehicle to sense its surrounding environment. It consists of six primary tasks necessary for an autonomous driving system: depth estimation, visual odometry, semantic segmentation, motion segmentation, object detection, and lens soiling detection. We demonstrate that the jointly trained model performs better than the respective single task versions. Our multi-task model has a shared encoder providing a significant computational advantage and has synergized decoders where tasks support each other. We propose a novel camera geometry based adaptation mechanism to encode the fisheye distortion model both at training and inference. This was crucial to enable training on the WoodScape dataset, comprised of data from different parts of the world collected by 12 different cameras mounted on three different cars with different intrinsics and viewpoints. Given that bounding boxes is not a good representation for distorted fisheye images, we also extend object detection to use a polygon with non-uniformly sampled vertices. We additionally evaluate our model on standard automotive datasets, namely KITTI and Cityscapes. We obtain the state-of-the-art results on KITTI for depth estimation and pose estimation tasks and competitive performance on the other tasks. We perform extensive ablation studies on various architecture choices and task weighting methodologies. A short video at https://youtu.be/xbSjZ5OfPes provides qualitative results.
INSTA-YOLO: Real-Time Instance Segmentation
Feb 12, 2021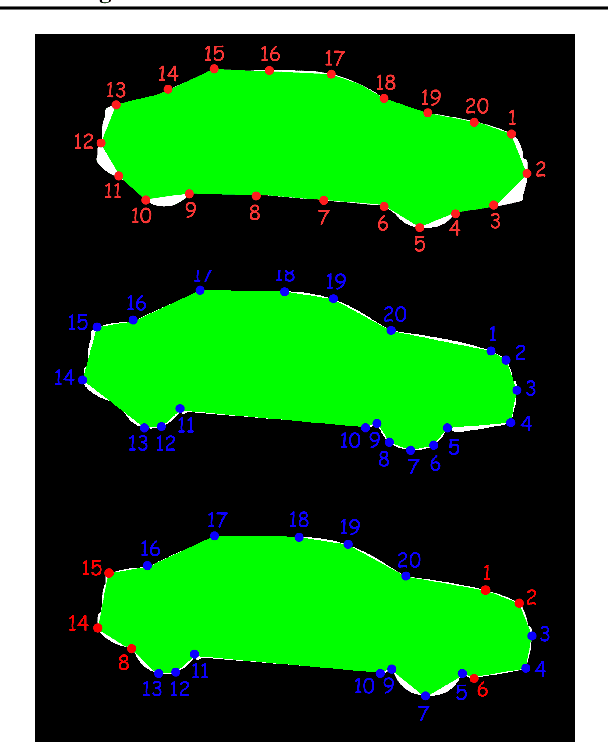
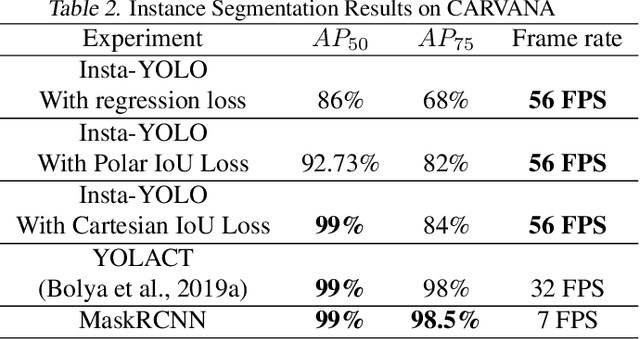

Instance segmentation has gained recently huge attention in various computer vision applications. It aims at providing different IDs to different objects of the scene, even if they belong to the same class. Instance segmentation is usually performed as a two-stage pipeline. First, an object is detected, then semantic segmentation within the detected box area is performed which involves costly up-sampling. In this paper, we propose Insta-YOLO, a novel one-stage end-to-end deep learning model for real-time instance segmentation. Instead of pixel-wise prediction, our model predicts instances as object contours represented by 2D points in Cartesian space. We evaluate our model on three datasets, namely, Carvana,Cityscapes and Airbus. We compare our results to the state-of-the-art models for instance segmentation. The results show our model achieves competitive accuracy in terms of mAP at twice the speed on GTX-1080 GPU.
Generalized Object Detection on Fisheye Cameras for Autonomous Driving: Dataset, Representations and Baseline
Dec 03, 2020
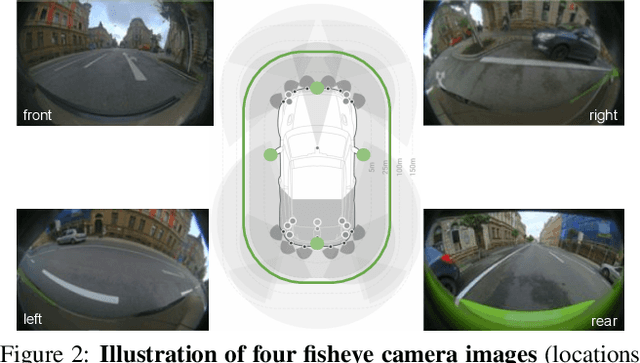
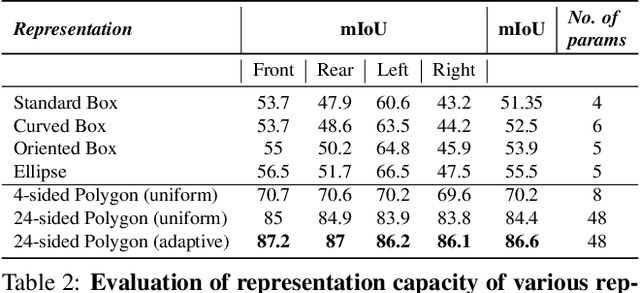
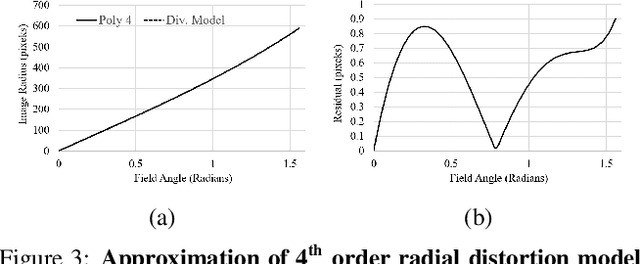
Object detection is a comprehensively studied problem in autonomous driving. However, it has been relatively less explored in the case of fisheye cameras. The standard bounding box fails in fisheye cameras due to the strong radial distortion, particularly in the image's periphery. We explore better representations like oriented bounding box, ellipse, and generic polygon for object detection in fisheye images in this work. We use the IoU metric to compare these representations using accurate instance segmentation ground truth. We design a novel curved bounding box model that has optimal properties for fisheye distortion models. We also design a curvature adaptive perimeter sampling method for obtaining polygon vertices, improving relative mAP score by 4.9% compared to uniform sampling. Overall, the proposed polygon model improves mIoU relative accuracy by 40.3%. It is the first detailed study on object detection on fisheye cameras for autonomous driving scenarios to the best of our knowledge. The dataset comprising of 10,000 images along with all the object representations ground truth will be made public to encourage further research. We summarize our work in a short video with qualitative results at https://youtu.be/iLkOzvJpL-A.
InstanceMotSeg: Real-time Instance Motion Segmentation for Autonomous Driving
Aug 16, 2020
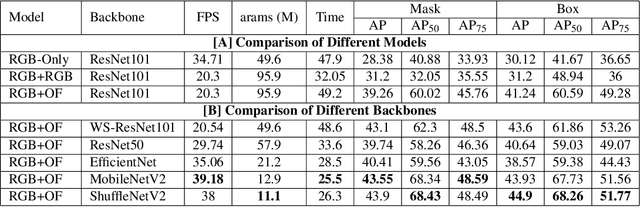
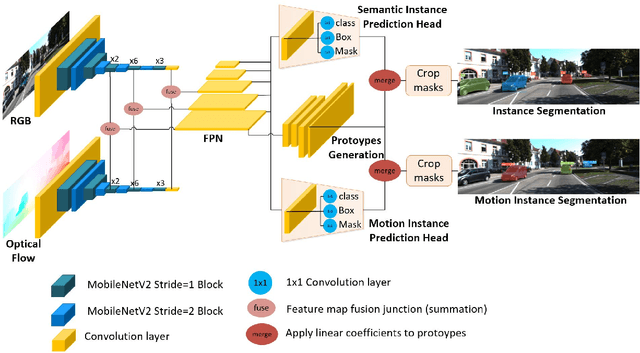
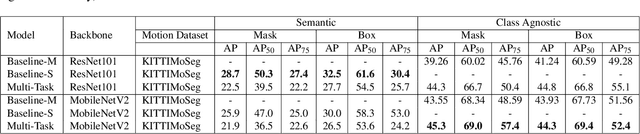
Moving object segmentation is a crucial task for autonomous vehicles as it can be used to segment objects in a class agnostic manner based on its motion cues. It will enable the detection of objects unseen during training (e.g., moose or a construction truck) generically based on their motion. Although pixel-wise motion segmentation has been studied in the literature, it is not dealt with at instance level, which would help separate connected segments of moving objects leading to better trajectory planning. In this paper, we proposed a motion-based instance segmentation task and created a new annotated dataset based on KITTI, which will be released publicly. We make use of the YOLACT model to solve the instance motion segmentation network by feeding inflow and image as input and instance motion masks as output. We extend it to a multi-task model that learns semantic and motion instance segmentation in a computationally efficient manner. Our model is based on sharing a prototype generation network between the two tasks and learning separate prototype coefficients per task. To obtain real-time performance, we study different efficient encoders and obtain 39 fps on a Titan Xp GPU using MobileNetV2 with an improvement of 10% mAP relative to the baseline. A video demonstration of our work is available in https://youtu.be/CWGZibugD9g.
FisheyeMultiNet: Real-time Multi-task Learning Architecture for Surround-view Automated Parking System
Dec 23, 2019
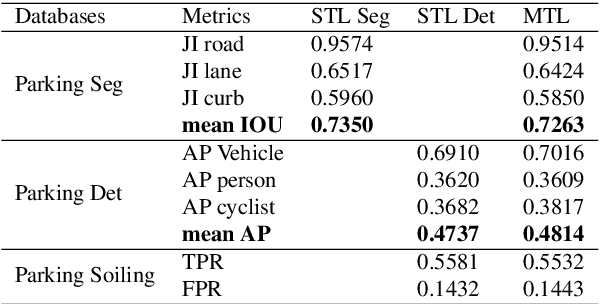
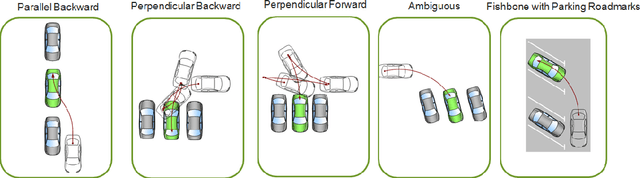
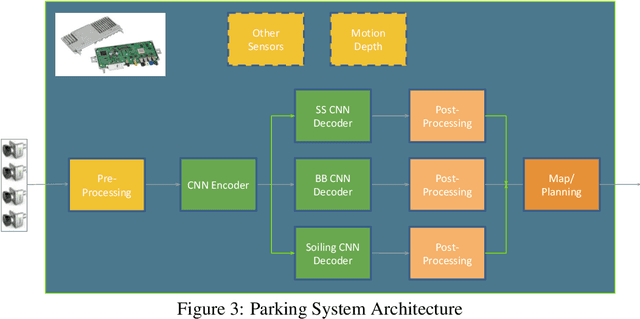
Automated Parking is a low speed manoeuvring scenario which is quite unstructured and complex, requiring full 360{\deg} near-field sensing around the vehicle. In this paper, we discuss the design and implementation of an automated parking system from the perspective of camera based deep learning algorithms. We provide a holistic overview of an industrial system covering the embedded system, use cases and the deep learning architecture. We demonstrate a real-time multi-task deep learning network called FisheyeMultiNet, which detects all the necessary objects for parking on a low-power embedded system. FisheyeMultiNet runs at 15 fps for 4 cameras and it has three tasks namely object detection, semantic segmentation and soiling detection. To encourage further research, we release a partial dataset of 5,000 images containing semantic segmentation and bounding box detection ground truth via WoodScape project \cite{yogamani2019woodscape}.
Let's Get Dirty: GAN Based Data Augmentation for Soiling and Adverse Weather Classification in Autonomous Driving
Dec 04, 2019

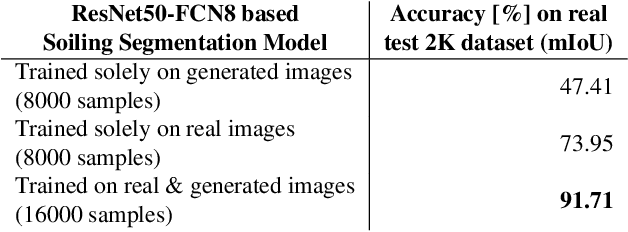

Cameras are getting more and more important in autonomous driving. Wide-angle fisheye cameras are relatively cheap sensors and very suitable for automated parking and low-speed navigation tasks. Four of such cameras form a surround-view system that provides a complete and detailed view around the vehicle. These cameras are usually directly exposed to harsh environmental settings and therefore can get soiled very easily by mud, dust, water, frost, etc. The soiling on the camera lens has a direct impact on the further processing of the images they provide. While adverse weather conditions, such as rain, are getting attention recently, there is limited work on lens soiling. We believe that one of the reasons is that it is difficult to build a diverse dataset for this task, which is moreover expensive to annotate. We propose a novel GAN based algorithm for generating artificial soiling data along with the corresponding annotation masks. The manually annotated soiling dataset and the generated augmentation dataset will be made public. We demonstrate the generalization of our fisheye trained soiling GAN model on the Cityscapes dataset. Additionally, we provide an empirical evaluation of the degradation of the semantic segmentation algorithm with the soiled data.