 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiMoSeg: Real-time Bird's Eye View based LiDAR Motion Segmentation
Nov 08, 2021

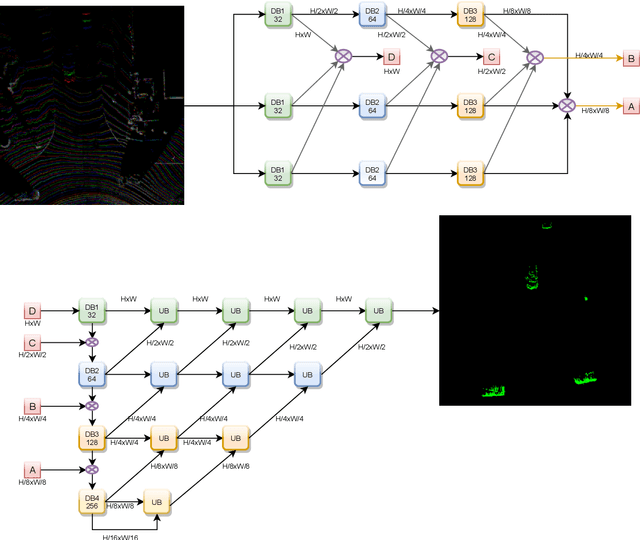

Moving object detection and segmentation is an essential task in the Autonomous Driving pipeline. Detecting and isolating static and moving components of a vehicle's surroundings are particularly crucial in path planning and localization tasks. This paper proposes a novel real-time architecture for motion segmentation of Light Detection and Ranging (LiDAR) data. We use two successive scans of LiDAR data in 2D Bird's Eye View (BEV) representation to perform pixel-wise classification as static or moving. Furthermore, we propose a novel data augmentation technique to reduce the significant class imbalance between static and moving objects. We achieve this by artificially synthesizing moving objects by cutting and pasting static vehicles. We demonstrate a low latency of 8 ms on a commonly used automotive embedded platform, namely Nvidia Jetson Xavier. To the best of our knowledge, this is the first work directly performing motion segmentation in LiDAR BEV space. We provide quantitative results on the challenging SemanticKITTI dataset, and qualitative results are provided in https://youtu.be/2aJ-cL8b0LI.
A Benchmark for Spray from Nearby Cutting Vehicles
Aug 24, 2021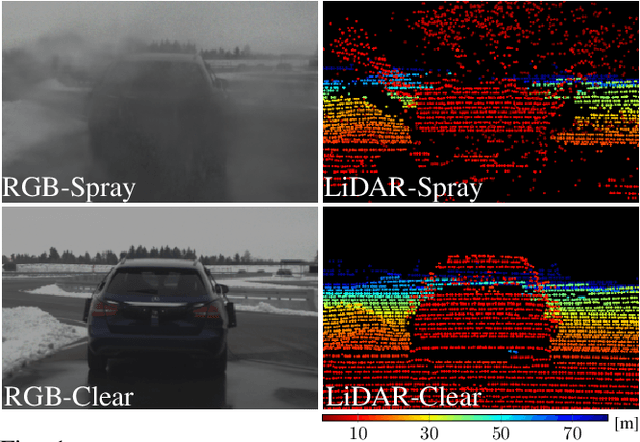
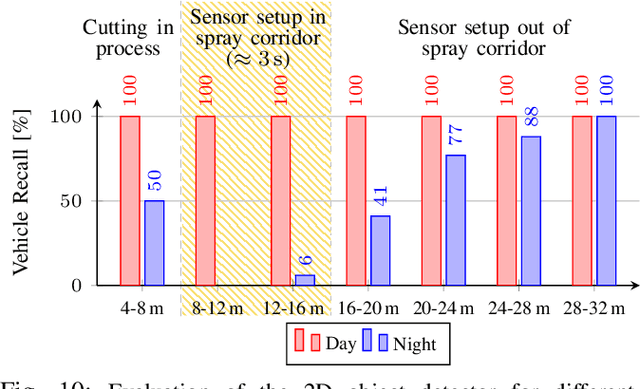
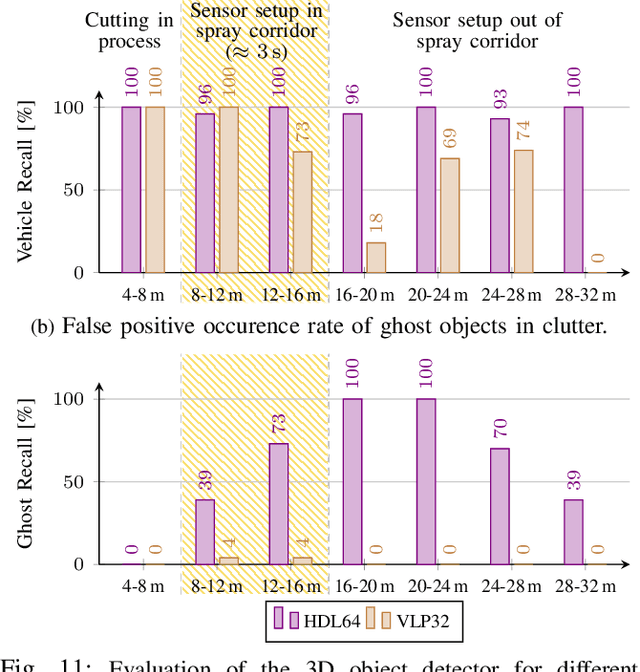
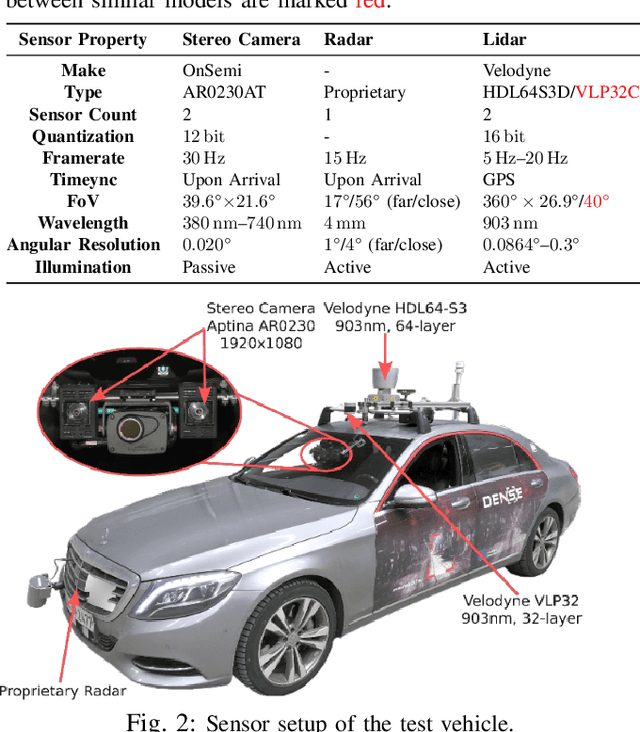
Current driver assistance systems and autonomous driving stacks are limited to well-defined environment conditions and geo fenced areas. To increase driving safety in adverse weather conditions, broadening the application spectrum of autonomous driving and driver assistance systems is necessary. In order to enable this development, reproducible benchmarking methods are required to quantify the expected distortions. In this publication, a testing methodology for disturbances from spray is presented. It introduces a novel lightweight and configurable spray setup alongside an evaluation scheme to assess the disturbances caused by spray. The analysis covers an automotive RGB camera and two different LiDAR systems, as well as downstream detection algorithms based on YOLOv3 and PV-RCNN. In a common scenario of a closely cutting vehicle, it is visible that the distortions are severely affecting the perception stack up to four seconds showing the necessity of benchmarking the influences of spray.
StickyPillars: Robust feature matching on point clouds using Graph Neural Networks
Feb 10, 2020
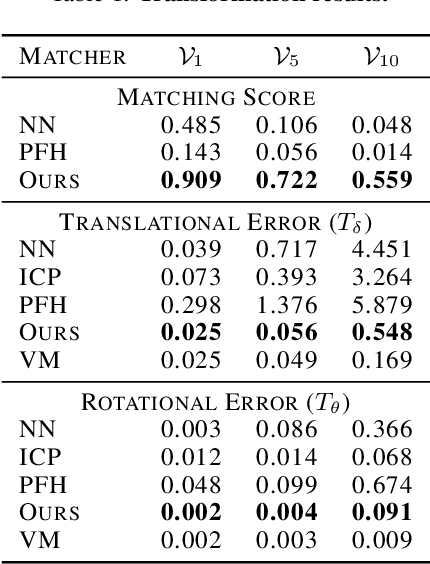
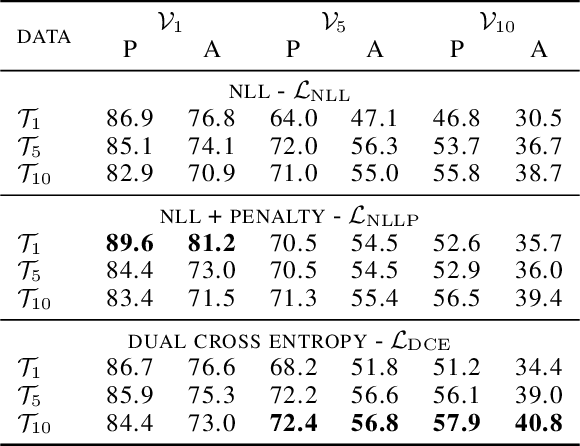
StickyPillars introduces a sparse feature matching method on point clouds. It is the first approach applying Graph Neural Networks on point clouds to stick points of interest. The feature estimation and assignment relies on the optimal transport problem, where the cost is based on the neural network itself. We utilize a Graph Neural Network for context aggregation with the aid of multihead self and cross attention. In contrast to image based feature matching methods, the architecture learns feature extraction in an end-to-end manner. Hence, the approach does not rely on handcrafted features. Our method outperforms state-of-the art matching algorithms, while providing real-time capability.
WoodScape: A multi-task, multi-camera fisheye dataset for autonomous driving
May 04, 2019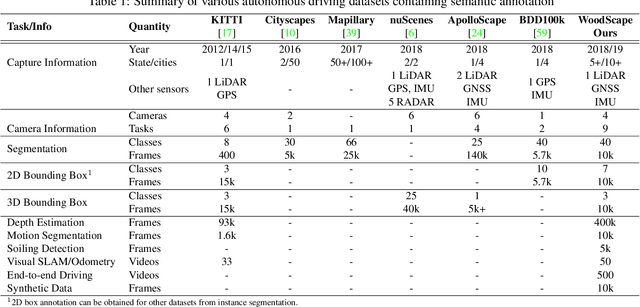
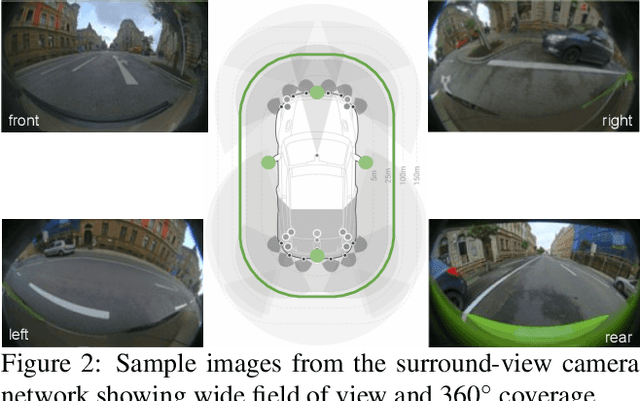
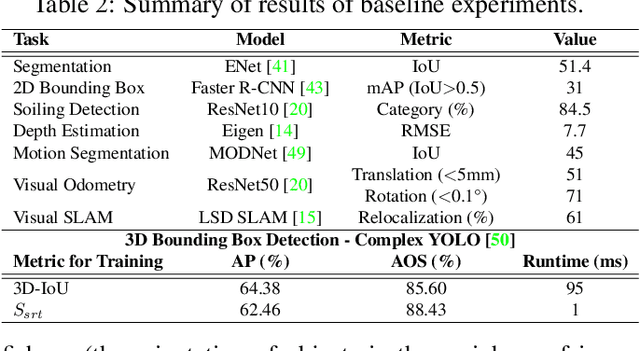
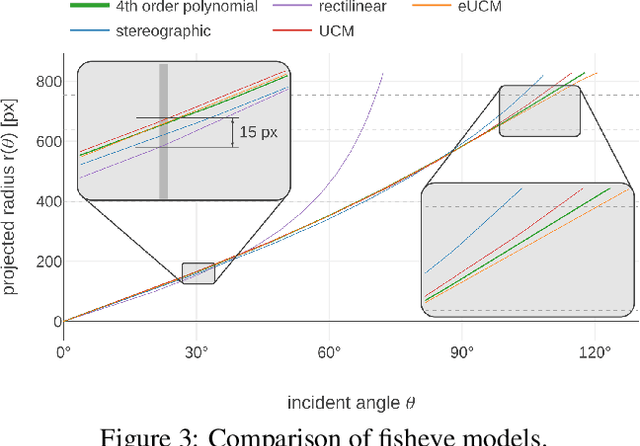
Fisheye cameras are commonly employed for obtaining a large field of view in surveillance, augmented reality and in particular automotive applications. In spite of its prevalence, there are few public datasets for detailed evaluation of computer vision algorithms on fisheye images. We release the first extensive fisheye automotive dataset, WoodScape, named after Robert Wood who invented the fisheye camera in 1906. WoodScape comprises of four surround view cameras and nine tasks including segmentation, depth estimation, 3D bounding box detection and soiling detection. Semantic annotation of 40 classes at the instance level is provided for over 10,000 images and annotation for other tasks are provided for over 100,000 images. We would like to encourage the community to adapt computer vision models for fisheye camera instead of naive rectification.
Complexer-YOLO: Real-Time 3D Object Detection and Tracking on Semantic Point Clouds
Apr 16, 2019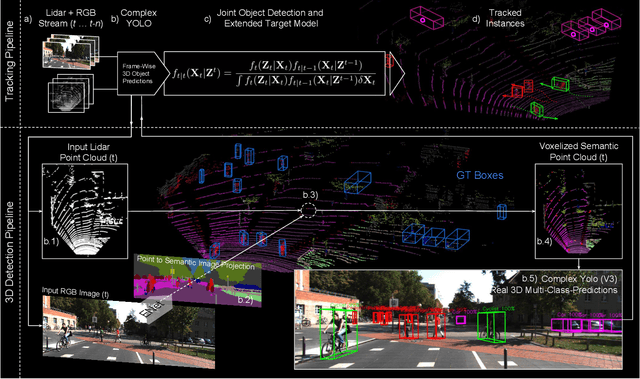
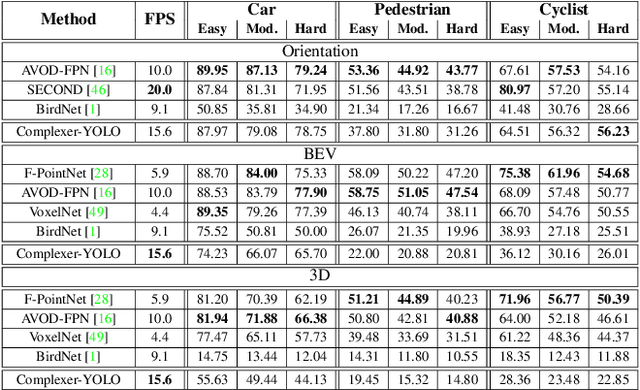
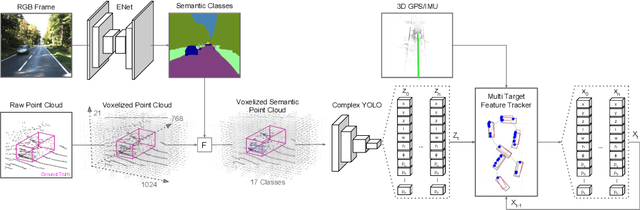
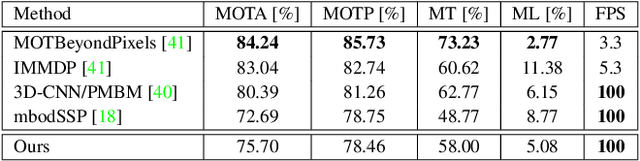
Accurate detection of 3D objects is a fundamental problem in computer vision and has an enormous impact on autonomous cars, augmented/virtual reality and many applications in robotics. In this work we present a novel fusion of neural network based state-of-the-art 3D detector and visual semantic segmentation in the context of autonomous driving. Additionally, we introduce Scale-Rotation-Translation score (SRTs), a fast and highly parameterizable evaluation metric for comparison of object detections, which speeds up our inference time up to 20\% and halves training time. On top, we apply state-of-the-art online multi target feature tracking on the object measurements to further increase accuracy and robustness utilizing temporal information. Our experiments on KITTI show that we achieve same results as state-of-the-art in all related categories, while maintaining the performance and accuracy trade-off and still run in real-time. Furthermore, our model is the first one that fuses visual semantic with 3D object detection.
Points2Pix: 3D Point-Cloud to Image Translation using conditional Generative Adversarial Networks
Jan 26, 2019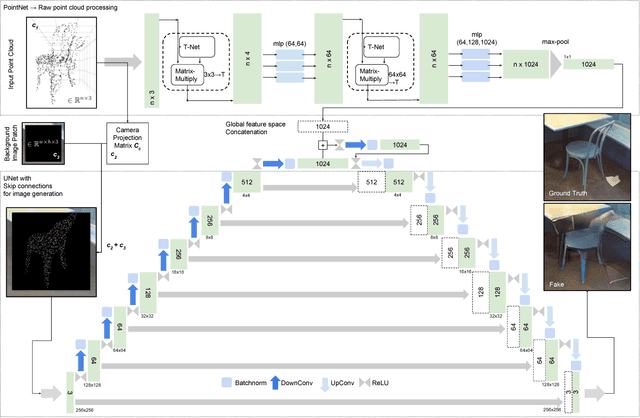
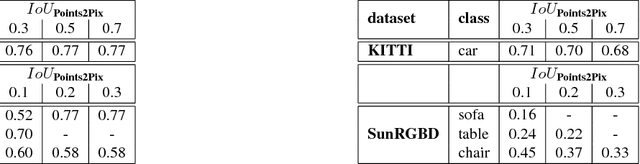
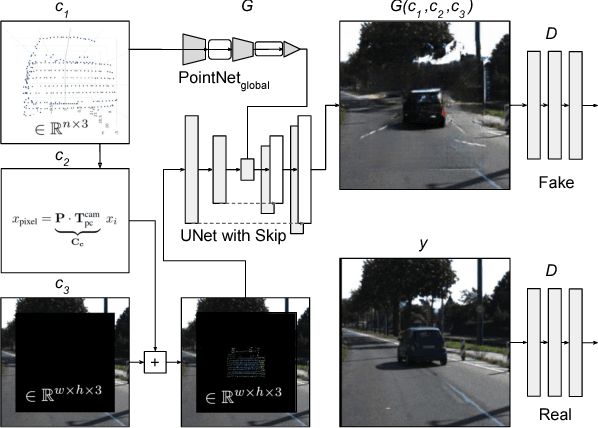

We present the first approach for 3D point-cloud to image translation based on conditional Generative Adversarial Networks (cGAN). The model handles multi-modal information sources from different domains, i.e. raw point-sets and images. The generator is capable of processing three conditions, whereas the point-cloud is encoded as raw point-set and camera projection. An image background patch is used as constraint to bias environmental texturing. A global approximation function within the generator is directly applied on the point-cloud (Point-Net). Hence, the representative learning model incorporates global 3D characteristics directly at the latent feature space. Conditions are used to bias the background and the viewpoint of the generated image. This opens up new ways in augmenting or texturing 3D data to aim the generation of fully individual images. We successfully evaluated our method on the Kitti and SunRGBD dataset with an outstanding object detection inception score.
Efficient Semantic Segmentation for Visual Bird's-eye View Interpretation
Nov 29, 2018


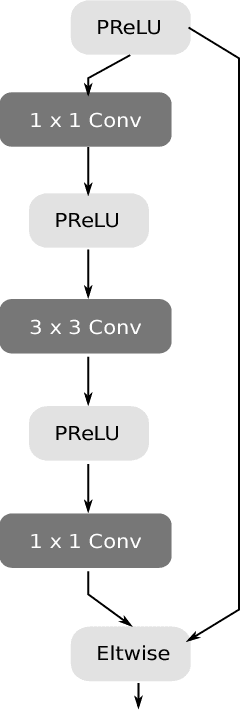
The ability to perform semantic segmentation in real-time capable applications with limited hardware is of great importance. One such application is the interpretation of the visual bird's-eye view, which requires the semantic segmentation of the four omnidirectional camera images. In this paper, we present an efficient semantic segmentation that sets new standards in terms of runtime and hardware requirements. Our two main contributions are the decrease of the runtime by parallelizing the ArgMax layer and the reduction of hardware requirements by applying the channel pruning method to the ENet model.
Monocular Fisheye Camera Depth Estimation Using Sparse LiDAR Supervision
Sep 24, 2018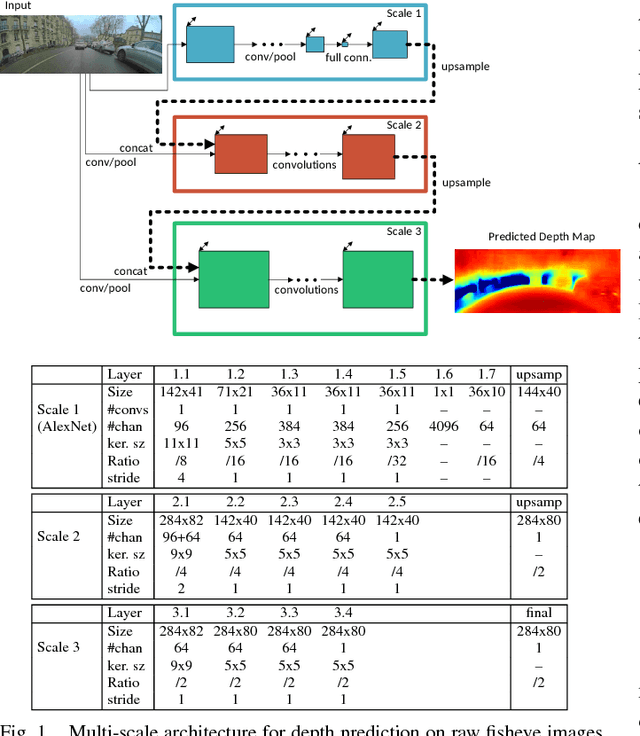

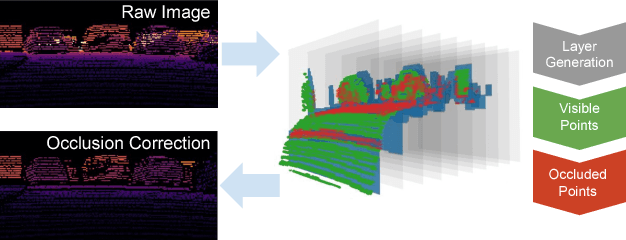

Near field depth estimation around a self driving car is an important function that can be achieved by four wide angle fisheye cameras having a field of view of over 180. Depth estimation based on convolutional neural networks (CNNs) produce state of the art results, but progress is hindered because depth annotation cannot be obtained manually. Synthetic datasets are commonly used but they have limitations. For instance, they do not capture the extensive variability in the appearance of objects like vehicles present in real datasets. There is also a domain shift while performing inference on natural images illustrated by many attempts to handle the domain adaptation explicitly. In this work, we explore an alternate approach of training using sparse LiDAR data as ground truth for depth estimation for fisheye camera. We built our own dataset using our self driving car setup which has a 64 beam Velodyne LiDAR and four wide angle fisheye cameras. To handle the difference in view points of LiDAR and fisheye camera, an occlusion resolution mechanism was implemented. We started with Eigen's multiscale convolutional network architecture and improved by modifying activation function and optimizer. We obtained promising results on our dataset with RMSE errors comparable to the state of the art results obtained on KITTI.
Complex-YOLO: Real-time 3D Object Detection on Point Clouds
Sep 24, 2018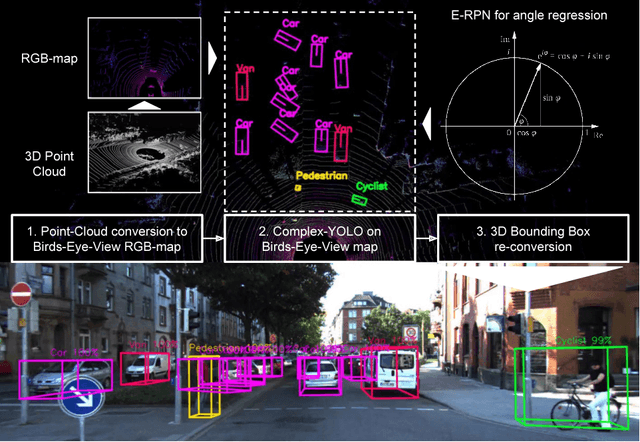

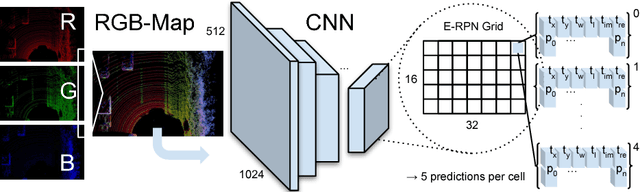
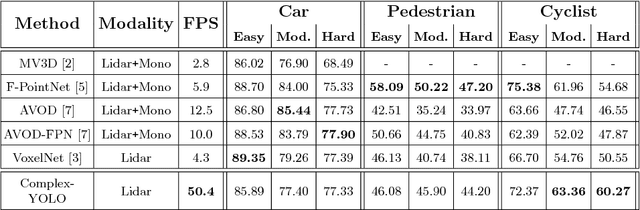
Lidar based 3D object detection is inevitable for autonomous driving, because it directly links to environmental understanding and therefore builds the base for prediction and motion planning. The capacity of inferencing highly sparse 3D data in real-time is an ill-posed problem for lots of other application areas besides automated vehicles, e.g. augmented reality, personal robotics or industrial automation. We introduce Complex-YOLO, a state of the art real-time 3D object detection network on point clouds only. In this work, we describe a network that expands YOLOv2, a fast 2D standard object detector for RGB images, by a specific complex regression strategy to estimate multi-class 3D boxes in Cartesian space. Thus, we propose a specific Euler-Region-Proposal Network (E-RPN) to estimate the pose of the object by adding an imaginary and a real fraction to the regression network. This ends up in a closed complex space and avoids singularities, which occur by single angle estimations. The E-RPN supports to generalize well during training. Our experiments on the KITTI benchmark suite show that we outperform current leading methods for 3D object detection specifically in terms of efficiency. We achieve state of the art results for cars, pedestrians and cyclists by being more than five times faster than the fastest competitor. Further, our model is capable of estimating all eight KITTI-classes, including Vans, Trucks or sitting pedestrians simultaneously with high accuracy.